 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClothes-Changing Person Re-identification with RGB Modality Only
Apr 14, 2022
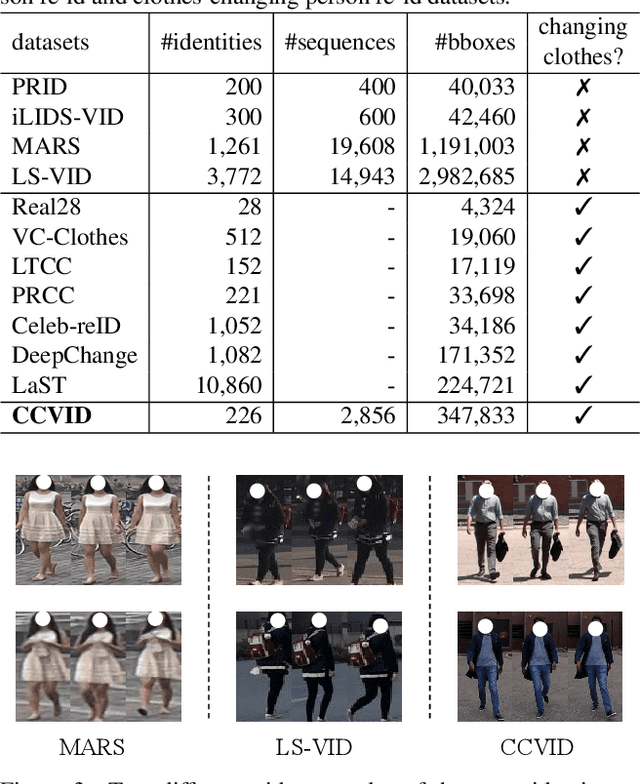
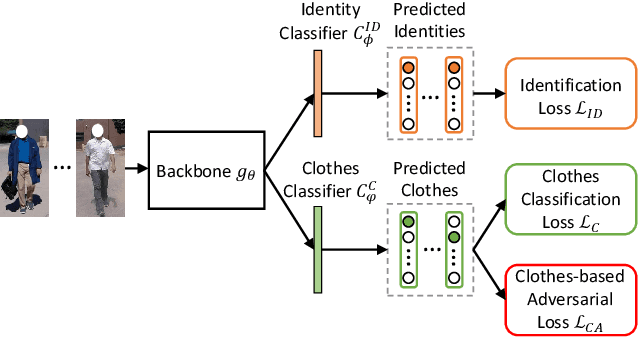
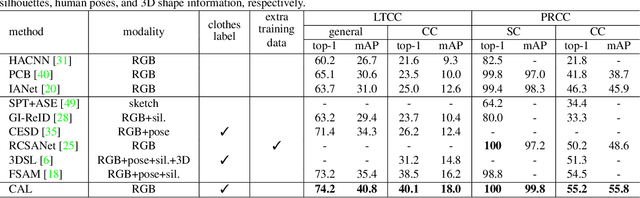
The key to address clothes-changing person re-identification (re-id) is to extract clothes-irrelevant features, e.g., face, hairstyle, body shape, and gait. Most current works mainly focus on modeling body shape from multi-modality information (e.g., silhouettes and sketches), but do not make full use of the clothes-irrelevant information in the original RGB images. In this paper, we propose a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images by penalizing the predictive power of re-id model w.r.t. clothes. Extensive experiments demonstrate that using RGB images only, CAL outperforms all state-of-the-art methods on widely-used clothes-changing person re-id benchmarks. Besides, compared with images, videos contain richer appearance and additional temporal information, which can be used to model proper spatiotemporal patterns to assist clothes-changing re-id. Since there is no publicly available clothes-changing video re-id dataset, we contribute a new dataset named CCVID and show that there exists much room for improvement in modeling spatiotemporal information. The code and new dataset are available at: https://github.com/guxinqian/Simple-CCReID.
Basket-based Softmax
Jan 23, 2022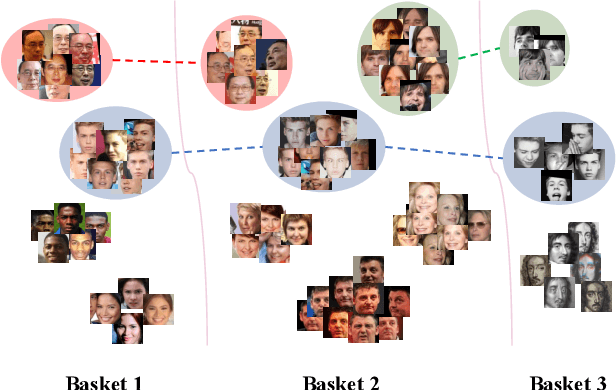

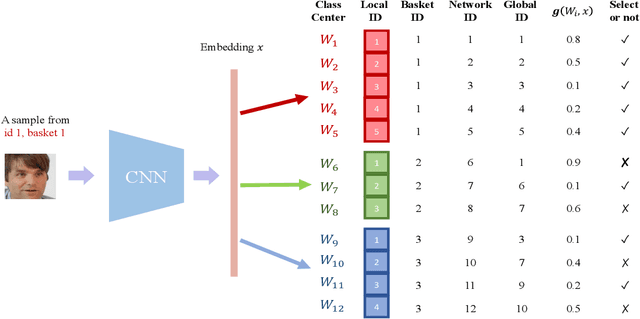
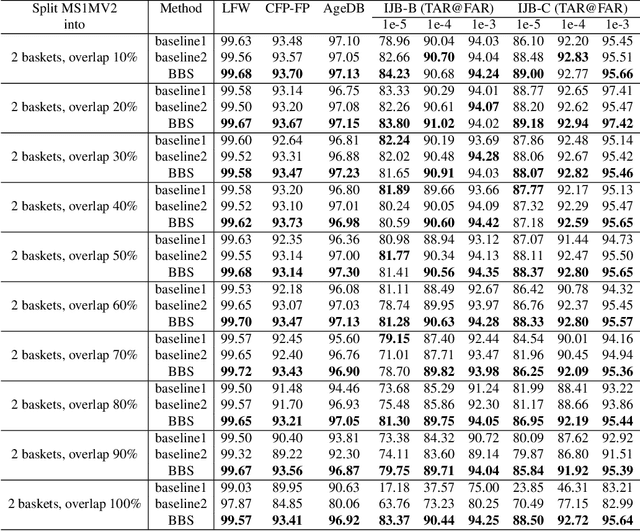
Softmax-based losses have achieved state-of-the-art performances on various tasks such as face recognition and re-identification. However, these methods highly relied on clean datasets with global labels, which limits their usage in many real-world applications. An important reason is that merging and organizing datasets from various temporal and spatial scenarios is usually not realistic, as noisy labels can be introduced and exponential-increasing resources are required. To address this issue, we propose a novel mining-during-training strategy called Basket-based Softmax (BBS) as well as its parallel version to effectively train models on multiple datasets in an end-to-end fashion. Specifically, for each training sample, we simultaneously adopt similarity scores as the clue to mining negative classes from other datasets, and dynamically add them to assist the learning of discriminative features. Experimentally, we demonstrate the efficiency and superiority of the BBS on the tasks of face recognition and re-identification, with both simulated and real-world datasets.
Feature Completion for Occluded Person Re-Identification
Jun 24, 2021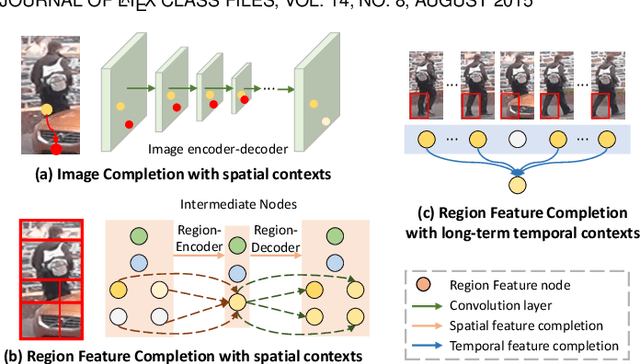
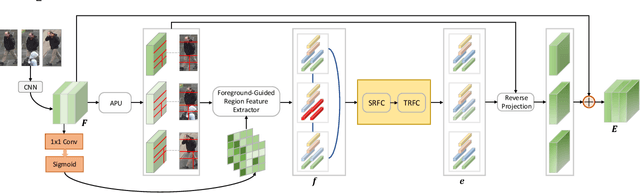

Person re-identification (reID) plays an important role in computer vision. However, existing methods suffer from performance degradation in occluded scenes. In this work, we propose an occlusion-robust block, Region Feature Completion (RFC), for occluded reID. Different from most previous works that discard the occluded regions, RFC block can recover the semantics of occluded regions in feature space. Firstly, a Spatial RFC (SRFC) module is developed. SRFC exploits the long-range spatial contexts from non-occluded regions to predict the features of occluded regions. The unit-wise prediction task leads to an encoder/decoder architecture, where the region-encoder models the correlation between non-occluded and occluded region, and the region-decoder utilizes the spatial correlation to recover occluded region features. Secondly, we introduce Temporal RFC (TRFC) module which captures the long-term temporal contexts to refine the prediction of SRFC. RFC block is lightweight, end-to-end trainable and can be easily plugged into existing CNNs to form RFCnet. Extensive experiments are conducted on occluded and commonly holistic reID benchmarks. Our method significantly outperforms existing methods on the occlusion datasets, while remains top even superior performance on holistic datasets. The source code is available at https://github.com/blue-blue272/OccludedReID-RFCnet.
* 18 pages, 17 figures. The paper is accepted by TPAMI, and the code is available at https://github.com/blue-blue272/OccludedReID-RFCnet
IAUnet: Global Context-Aware Feature Learning for Person Re-Identification
Sep 02, 2020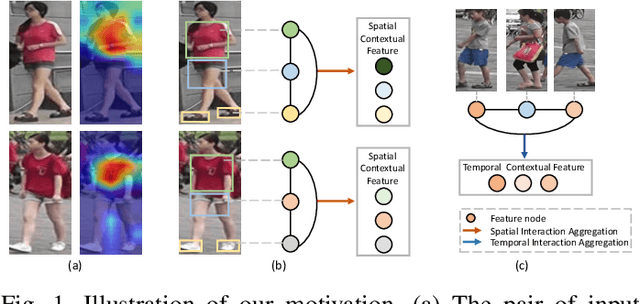
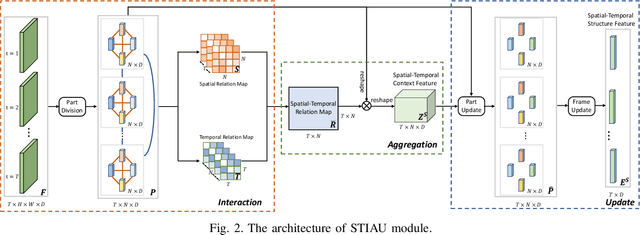
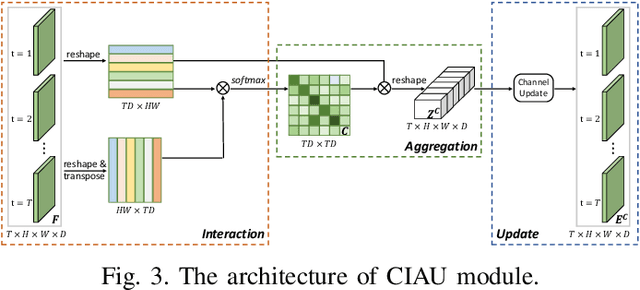

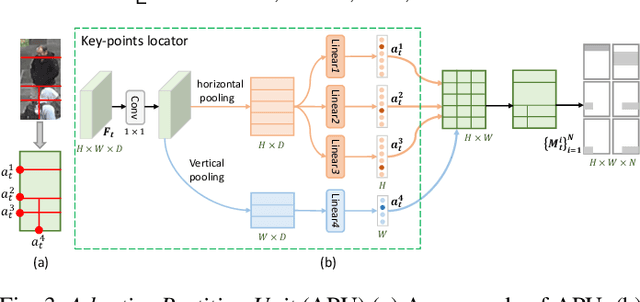
Person re-identification (reID) by CNNs based networks has achieved favorable performance in recent years. However, most of existing CNNs based methods do not take full advantage of spatial-temporal context modeling. In fact, the global spatial-temporal context can greatly clarify local distractions to enhance the target feature representation. To comprehensively leverage the spatial-temporal context information, in this work, we present a novel block, Interaction-Aggregation-Update (IAU), for high-performance person reID. Firstly, Spatial-Temporal IAU (STIAU) module is introduced. STIAU jointly incorporates two types of contextual interactions into a CNN framework for target feature learning. Here the spatial interactions learn to compute the contextual dependencies between different body parts of a single frame. While the temporal interactions are used to capture the contextual dependencies between the same body parts across all frames. Furthermore, a Channel IAU (CIAU) module is designed to model the semantic contextual interactions between channel features to enhance the feature representation, especially for small-scale visual cues and body parts. Therefore, the IAU block enables the feature to incorporate the globally spatial, temporal, and channel context. It is lightweight, end-to-end trainable, and can be easily plugged into existing CNNs to form IAUnet. The experiments show that IAUnet performs favorably against state-of-the-art on both image and video reID tasks and achieves compelling results on a general object categorization task. The source code is available at https://github.com/blue-blue272/ImgReID-IAnet.
Appearance-Preserving 3D Convolution for Video-based Person Re-identification
Jul 27, 2020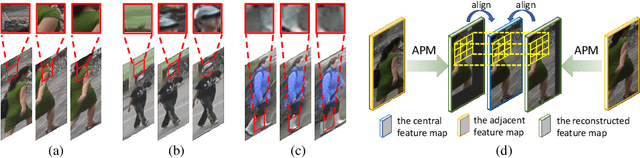
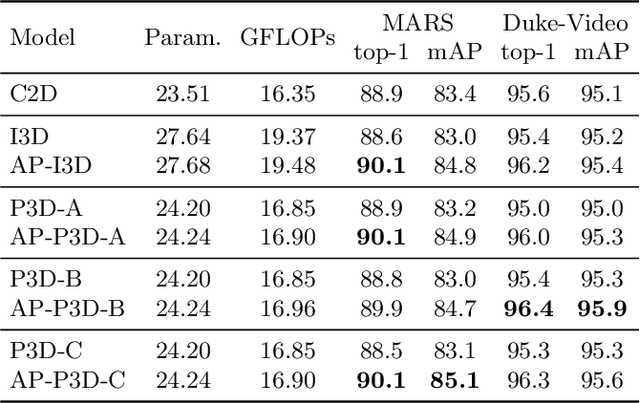
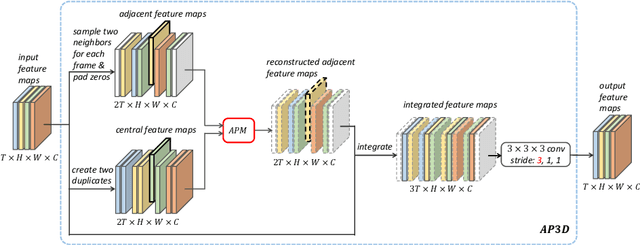
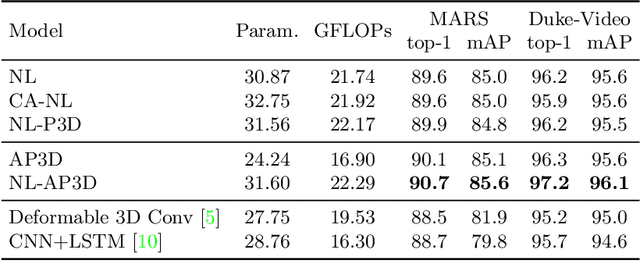
Due to the imperfect person detection results and posture changes, temporal appearance misalignment is unavoidable in video-based person re-identification (ReID). In this case, 3D convolution may destroy the appearance representation of person video clips, thus it is harmful to ReID. To address this problem, we propose AppearancePreserving 3D Convolution (AP3D), which is composed of two components: an Appearance-Preserving Module (APM) and a 3D convolution kernel. With APM aligning the adjacent feature maps in pixel level, the following 3D convolution can model temporal information on the premise of maintaining the appearance representation quality. It is easy to combine AP3D with existing 3D ConvNets by simply replacing the original 3D convolution kernels with AP3Ds. Extensive experiments demonstrate the effectiveness of AP3D for video-based ReID and the results on three widely used datasets surpass the state-of-the-arts. Code is available at: https://github.com/guxinqian/AP3D.
Temporal Knowledge Propagation for Image-to-Video Person Re-identification
Aug 11, 2019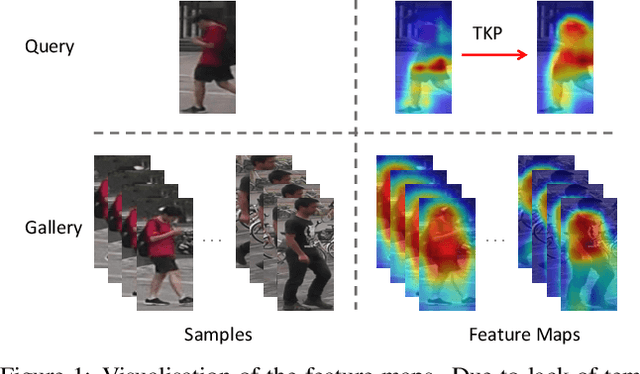
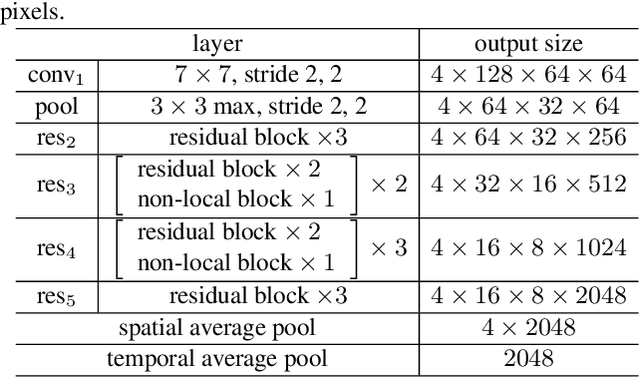
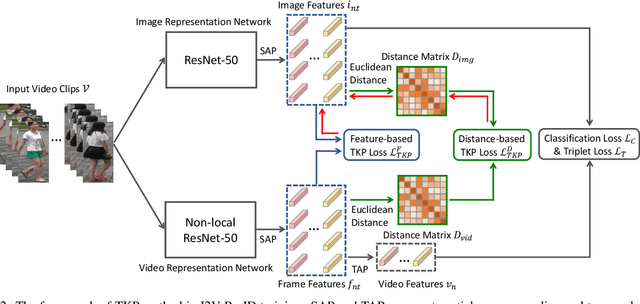
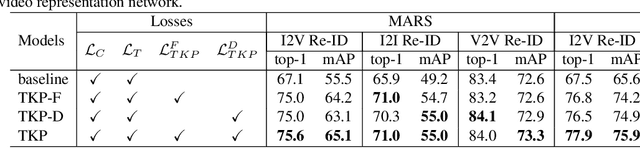
In many scenarios of Person Re-identification (Re-ID), the gallery set consists of lots of surveillance videos and the query is just an image, thus Re-ID has to be conducted between image and videos. Compared with videos, still person images lack temporal information. Besides, the information asymmetry between image and video features increases the difficulty in matching images and videos. To solve this problem, we propose a novel Temporal Knowledge Propagation (TKP) method which propagates the temporal knowledge learned by the video representation network to the image representation network. Specifically, given the input videos, we enforce the image representation network to fit the outputs of video representation network in a shared feature space. With back propagation, temporal knowledge can be transferred to enhance the image features and the information asymmetry problem can be alleviated. With additional classification and integrated triplet losses, our model can learn expressive and discriminative image and video features for image-to-video re-identification. Extensive experiments demonstrate the effectiveness of our method and the overall results on two widely used datasets surpass the state-of-the-art methods by a large margin.
Interaction-and-Aggregation Network for Person Re-identification
Jul 19, 2019
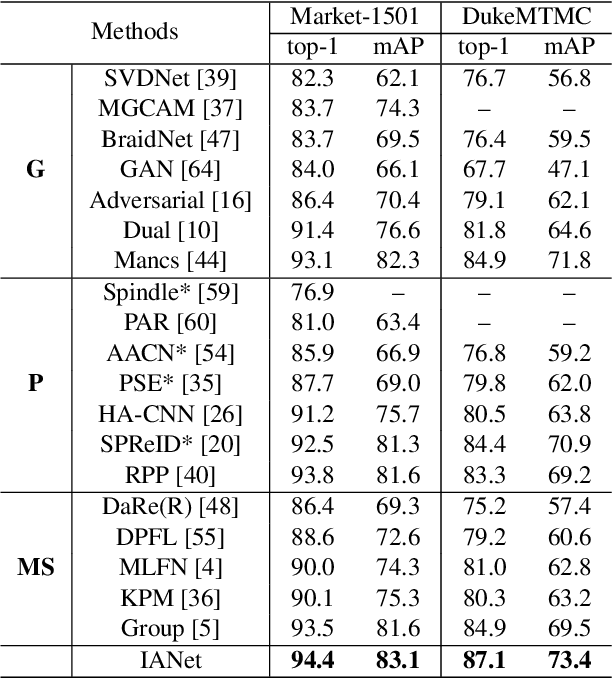
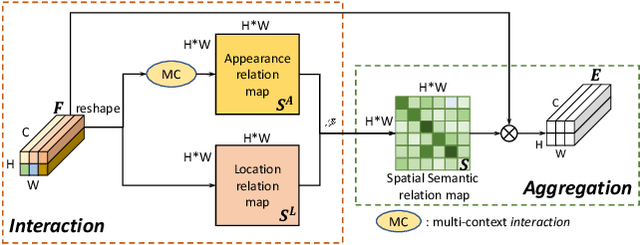
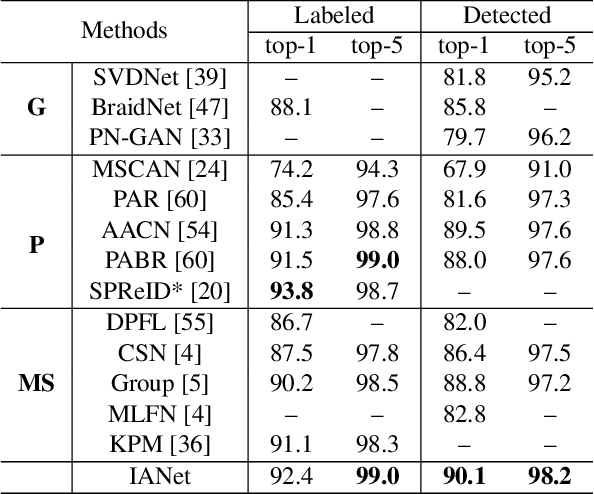
Person re-identification (reID) benefits greatly from deep convolutional neural networks (CNNs) which learn robust feature embeddings. However, CNNs are inherently limited in modeling the large variations in person pose and scale due to their fixed geometric structures. In this paper, we propose a novel network structure, Interaction-and-Aggregation (IA), to enhance the feature representation capability of CNNs. Firstly, Spatial IA (SIA) module is introduced. It models the interdependencies between spatial features and then aggregates the correlated features corresponding to the same body parts. Unlike CNNs which extract features from fixed rectangle regions, SIA can adaptively determine the receptive fields according to the input person pose and scale. Secondly, we introduce Channel IA (CIA) module which selectively aggregates channel features to enhance the feature representation, especially for smallscale visual cues. Further, IA network can be constructed by inserting IA blocks into CNNs at any depth. We validate the effectiveness of our model for person reID by demonstrating its superiority over state-of-the-art methods on three benchmark datasets.
VRSTC: Occlusion-Free Video Person Re-Identification
Jul 19, 2019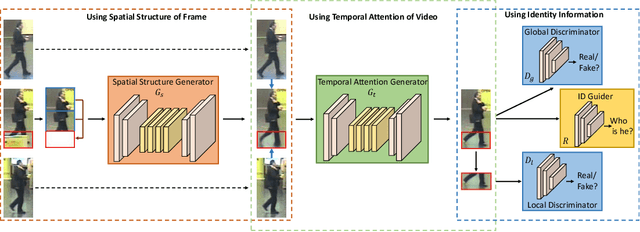
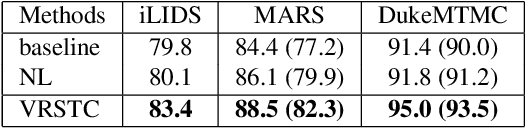
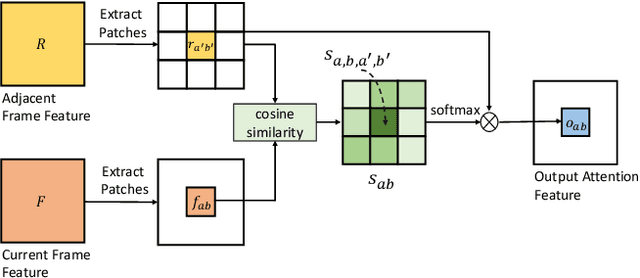
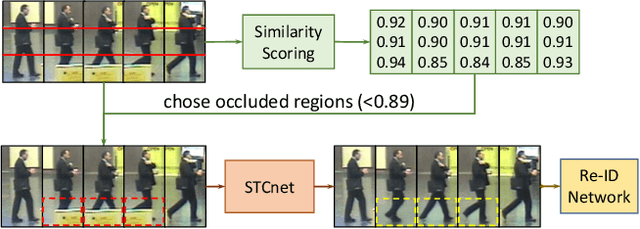
Video person re-identification (re-ID) plays an important role in surveillance video analysis. However, the performance of video re-ID degenerates severely under partial occlusion. In this paper, we propose a novel network, called Spatio-Temporal Completion network (STCnet), to explicitly handle partial occlusion problem. Different from most previous works that discard the occluded frames, STCnet can recover the appearance of the occluded parts. For one thing, the spatial structure of a pedestrian frame can be used to predict the occluded body parts from the unoccluded body parts of this frame. For another, the temporal patterns of pedestrian sequence provide important clues to generate the contents of occluded parts. With the Spatio-temporal information, STCnet can recover the appearance for the occluded parts, which could be leveraged with those unoccluded parts for more accurate video re-ID. By combining a re-ID network with STCnet, a video re-ID framework robust to partial occlusion (VRSTC) is proposed. Experiments on three challenging video re-ID databases demonstrate that the proposed approach outperforms the state-of-the-art.