 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAUnet: Global Context-Aware Feature Learning for Person Re-Identification
Paper and Code
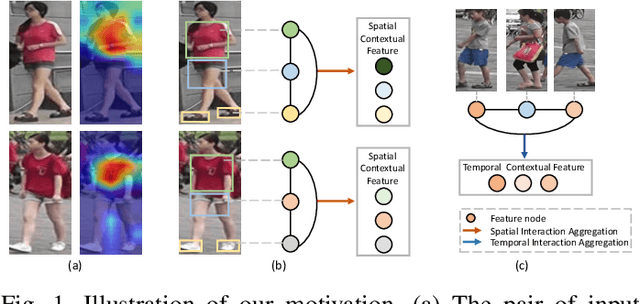
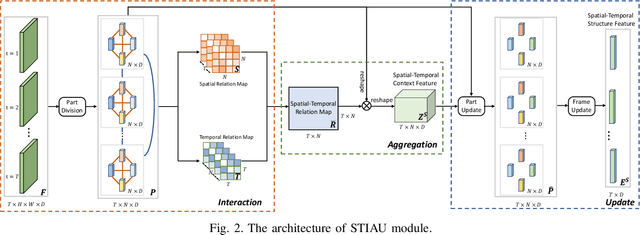
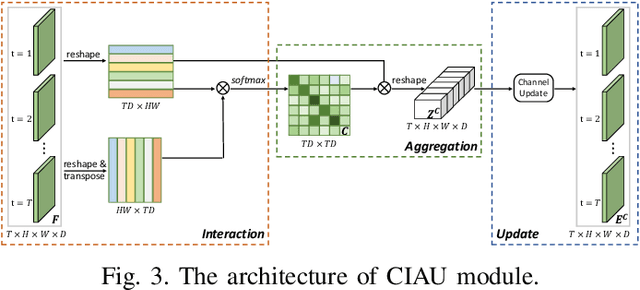

Person re-identification (reID) by CNNs based networks has achieved favorable performance in recent years. However, most of existing CNNs based methods do not take full advantage of spatial-temporal context modeling. In fact, the global spatial-temporal context can greatly clarify local distractions to enhance the target feature representation. To comprehensively leverage the spatial-temporal context information, in this work, we present a novel block, Interaction-Aggregation-Update (IAU), for high-performance person reID. Firstly, Spatial-Temporal IAU (STIAU) module is introduced. STIAU jointly incorporates two types of contextual interactions into a CNN framework for target feature learning. Here the spatial interactions learn to compute the contextual dependencies between different body parts of a single frame. While the temporal interactions are used to capture the contextual dependencies between the same body parts across all frames. Furthermore, a Channel IAU (CIAU) module is designed to model the semantic contextual interactions between channel features to enhance the feature representation, especially for small-scale visual cues and body parts. Therefore, the IAU block enables the feature to incorporate the globally spatial, temporal, and channel context. It is lightweight, end-to-end trainable, and can be easily plugged into existing CNNs to form IAUnet. The experiments show that IAUnet performs favorably against state-of-the-art on both image and video reID tasks and achieves compelling results on a general object categorization task. The source code is available at https://github.com/blue-blue272/ImgReID-IAnet.