 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRSTC: Occlusion-Free Video Person Re-Identification
Paper and Code
Jul 19, 2019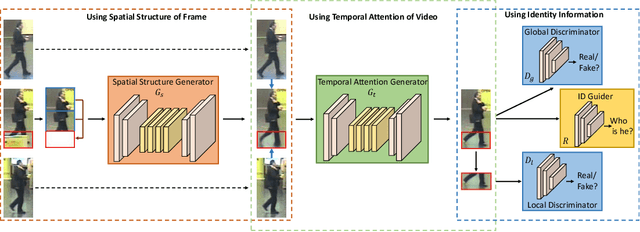
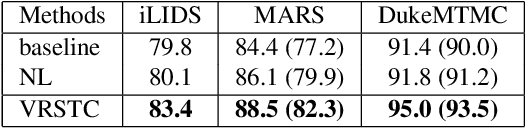
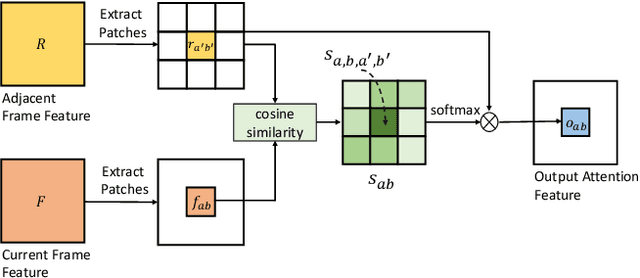
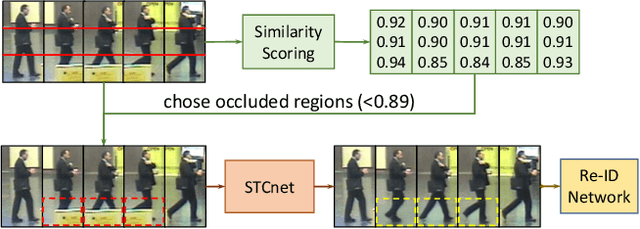
Video person re-identification (re-ID) plays an important role in surveillance video analysis. However, the performance of video re-ID degenerates severely under partial occlusion. In this paper, we propose a novel network, called Spatio-Temporal Completion network (STCnet), to explicitly handle partial occlusion problem. Different from most previous works that discard the occluded frames, STCnet can recover the appearance of the occluded parts. For one thing, the spatial structure of a pedestrian frame can be used to predict the occluded body parts from the unoccluded body parts of this frame. For another, the temporal patterns of pedestrian sequence provide important clues to generate the contents of occluded parts. With the Spatio-temporal information, STCnet can recover the appearance for the occluded parts, which could be leveraged with those unoccluded parts for more accurate video re-ID. By combining a re-ID network with STCnet, a video re-ID framework robust to partial occlusion (VRSTC) is proposed. Experiments on three challenging video re-ID databases demonstrate that the proposed approach outperforms the state-of-the-art.