 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Paper and Code
Sep 22, 2024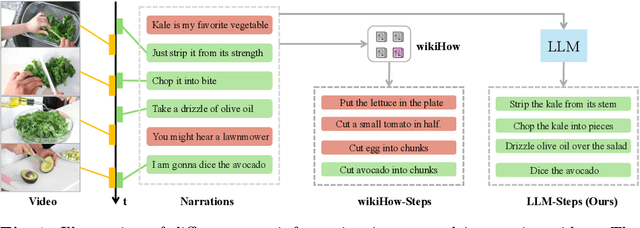



Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9\%, 3.1\%, and 2.8\%.