 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum AUC Difference (SAUCD): Human-aligned 3D Shape Evaluation
Mar 03, 2024Existing 3D mesh shape evaluation metrics mainly focus on the overall shape but are usually less sensitive to local details. This makes them inconsistent with human evaluation, as human perception cares about both overall and detailed shape. In this paper, we propose an analytic metric named Spectrum Area Under the Curve Difference (SAUCD) that demonstrates better consistency with human evaluation. To compare the difference between two shapes, we first transform the 3D mesh to the spectrum domain using the discrete Laplace-Beltrami operator and Fourier transform. Then, we calculate the Area Under the Curve (AUC) difference between the two spectrums, so that each frequency band that captures either the overall or detailed shape is equitably considered. Taking human sensitivity across frequency bands into account, we further extend our metric by learning suitable weights for each frequency band which better aligns with human perception. To measure the performance of SAUCD, we build a 3D mesh evaluation dataset called Shape Grading, along with manual annotations from more than 800 subjects. By measuring the correlation between our metric and human evaluation, we demonstrate that SAUCD is well aligned with human evaluation, and outperforms previous 3D mesh metrics.
Tri$^{2}$-plane: Volumetric Avatar Reconstruction with Feature Pyramid
Jan 17, 2024Recent years have witnessed considerable achievements in facial avatar reconstruction with neural volume rendering. Despite notable advancements, the reconstruction of complex and dynamic head movements from monocular videos still suffers from capturing and restoring fine-grained details. In this work, we propose a novel approach, named Tri$^2$-plane, for monocular photo-realistic volumetric head avatar reconstructions. Distinct from the existing works that rely on a single tri-plane deformation field for dynamic facial modeling, the proposed Tri$^2$-plane leverages the principle of feature pyramids and three top-to-down lateral connections tri-planes for details improvement. It samples and renders facial details at multiple scales, transitioning from the entire face to specific local regions and then to even more refined sub-regions. Moreover, we incorporate a camera-based geometry-aware sliding window method as an augmentation in training, which improves the robustness beyond the canonical space, with a particular improvement in cross-identity generation capabilities. Experimental outcomes indicate that the Tri$^2$-plane not only surpasses existing methodologies but also achieves superior performance across both quantitative metrics and qualitative assessments through experiments.
Relit-NeuLF: Efficient Relighting and Novel View Synthesis via Neural 4D Light Field
Oct 23, 2023



In this paper, we address the problem of simultaneous relighting and novel view synthesis of a complex scene from multi-view images with a limited number of light sources. We propose an analysis-synthesis approach called Relit-NeuLF. Following the recent neural 4D light field network (NeuLF), Relit-NeuLF first leverages a two-plane light field representation to parameterize each ray in a 4D coordinate system, enabling efficient learning and inference. Then, we recover the spatially-varying bidirectional reflectance distribution function (SVBRDF) of a 3D scene in a self-supervised manner. A DecomposeNet learns to map each ray to its SVBRDF components: albedo, normal, and roughness. Based on the decomposed BRDF components and conditioning light directions, a RenderNet learns to synthesize the color of the ray. To self-supervise the SVBRDF decomposition, we encourage the predicted ray color to be close to the physically-based rendering result using the microfacet model. Comprehensive experiments demonstrate that the proposed method is efficient and effective on both synthetic data and real-world human face data, and outperforms the state-of-the-art results. We publicly released our code on GitHub. You can find it here: https://github.com/oppo-us-research/RelitNeuLF
NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions
Sep 27, 2023We present a novel type of neural fields that uses general radial bases for signal representation. State-of-the-art neural fields typically rely on grid-based representations for storing local neural features and N-dimensional linear kernels for interpolating features at continuous query points. The spatial positions of their neural features are fixed on grid nodes and cannot well adapt to target signals. Our method instead builds upon general radial bases with flexible kernel position and shape, which have higher spatial adaptivity and can more closely fit target signals. To further improve the channel-wise capacity of radial basis functions, we propose to compose them with multi-frequency sinusoid functions. This technique extends a radial basis to multiple Fourier radial bases of different frequency bands without requiring extra parameters, facilitating the representation of details. Moreover, by marrying adaptive radial bases with grid-based ones, our hybrid combination inherits both adaptivity and interpolation smoothness. We carefully designed weighting schemes to let radial bases adapt to different types of signals effectively. Our experiments on 2D image and 3D signed distance field representation demonstrate the higher accuracy and compactness of our method than prior arts. When applied to neural radiance field reconstruction, our method achieves state-of-the-art rendering quality, with small model size and comparable training speed.
Uncertainty-aware State Space Transformer for Egocentric 3D Hand Trajectory Forecasting
Jul 17, 2023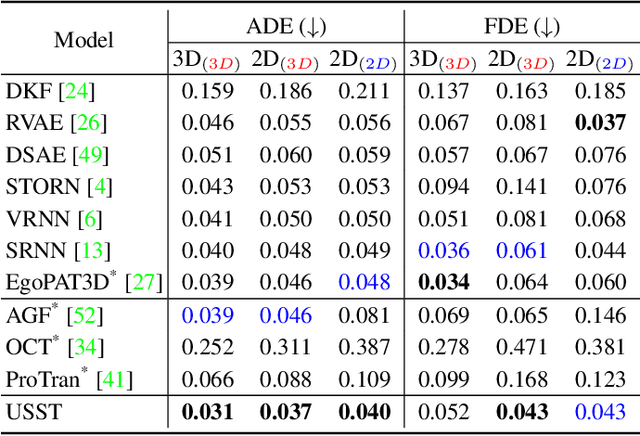


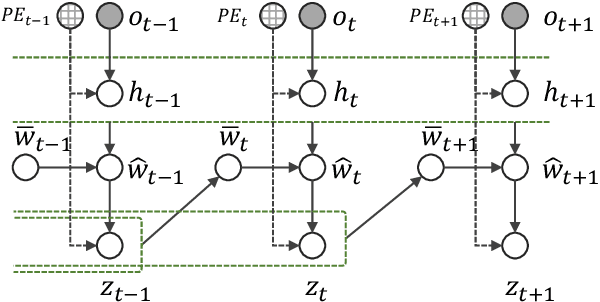
Hand trajectory forecasting from egocentric views is crucial for enabling a prompt understanding of human intentions when interacting with AR/VR systems. However, existing methods handle this problem in a 2D image space which is inadequate for 3D real-world applications. In this paper, we set up an egocentric 3D hand trajectory forecasting task that aims to predict hand trajectories in a 3D space from early observed RGB videos in a first-person view. To fulfill this goal, we propose an uncertainty-aware state space Transformer (USST) that takes the merits of the attention mechanism and aleatoric uncertainty within the framework of the classical state-space model. The model can be further enhanced by the velocity constraint and visual prompt tuning (VPT) on large vision transformers. Moreover, we develop an annotation workflow to collect 3D hand trajectories with high quality. Experimental results on H2O and EgoPAT3D datasets demonstrate the superiority of USST for both 2D and 3D trajectory forecasting. The code and datasets are publicly released: https://github.com/Cogito2012/USST.
MyStyle++: A Controllable Personalized Generative Prior
Jun 09, 2023
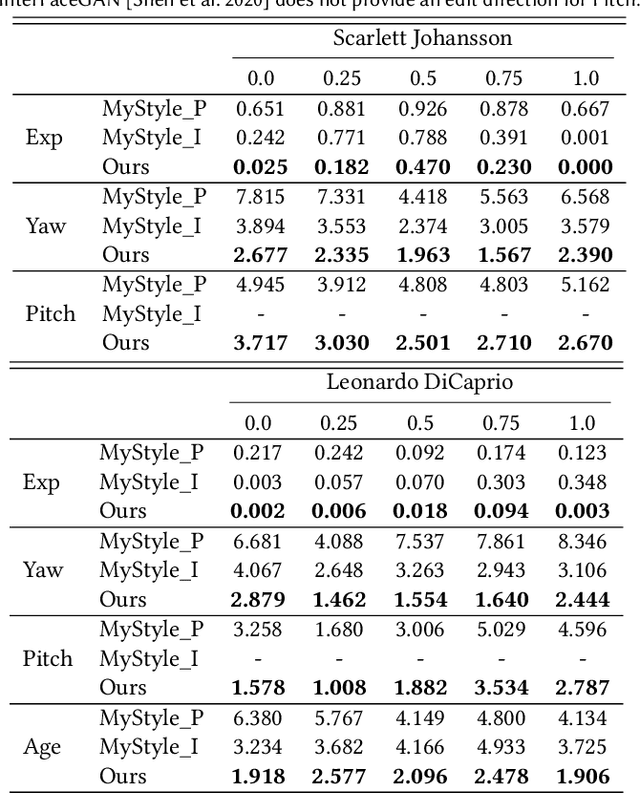


In this paper, we propose an approach to obtain a personalized generative prior with explicit control over a set of attributes. We build upon MyStyle, a recently introduced method, that tunes the weights of a pre-trained StyleGAN face generator on a few images of an individual. This system allows synthesizing, editing, and enhancing images of the target individual with high fidelity to their facial features. However, MyStyle does not demonstrate precise control over the attributes of the generated images. We propose to address this problem through a novel optimization system that organizes the latent space in addition to tuning the generator. Our key contribution is to formulate a loss that arranges the latent codes, corresponding to the input images, along a set of specific directions according to their attributes. We demonstrate that our approach, dubbed MyStyle++, is able to synthesize, edit, and enhance images of an individual with great control over the attributes, while preserving the unique facial characteristics of that individual.
Harnessing Low-Frequency Neural Fields for Few-Shot View Synthesis
Mar 15, 2023Neural Radiance Fields (NeRF) have led to breakthroughs in the novel view synthesis problem. Positional Encoding (P.E.) is a critical factor that brings the impressive performance of NeRF, where low-dimensional coordinates are mapped to high-dimensional space to better recover scene details. However, blindly increasing the frequency of P.E. leads to overfitting when the reconstruction problem is highly underconstrained, \eg, few-shot images for training. We harness low-frequency neural fields to regularize high-frequency neural fields from overfitting to better address the problem of few-shot view synthesis. We propose reconstructing with a low-frequency only field and then finishing details with a high-frequency equipped field. Unlike most existing solutions that regularize the output space (\ie, rendered images), our regularization is conducted in the input space (\ie, signal frequency). We further propose a simple-yet-effective strategy for tuning the frequency to avoid overfitting few-shot inputs: enforcing consistency among the frequency domain of rendered 2D images. Thanks to the input space regularizing scheme, our method readily applies to inputs beyond spatial locations, such as the time dimension in dynamic scenes. Comparisons with state-of-the-art on both synthetic and natural datasets validate the effectiveness of our proposed solution for few-shot view synthesis. Code is available at \href{https://github.com/lsongx/halo}{https://github.com/lsongx/halo}.
NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields
Oct 28, 2022



Visually exploring in a real-world 4D spatiotemporal space freely in VR has been a long-term quest. The task is especially appealing when only a few or even single RGB cameras are used for capturing the dynamic scene. To this end, we present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. First, we propose to decompose the 4D spatiotemporal space according to temporal characteristics. Points in the 4D space are associated with probabilities of belonging to three categories: static, deforming, and new areas. Each area is represented and regularized by a separate neural field. Second, we propose a hybrid representations based feature streaming scheme for efficiently modeling the neural fields. Our approach, coined NeRFPlayer, is evaluated on dynamic scenes captured by single hand-held cameras and multi-camera arrays, achieving comparable or superior rendering performance in terms of quality and speed comparable to recent state-of-the-art methods, achieving reconstruction in 10 seconds per frame and real-time rendering.
High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation
Mar 29, 2021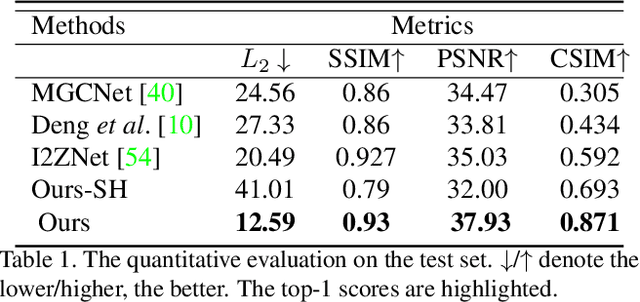


3D video avatars can empower virtual communications by providing compression, privacy, entertainment, and a sense of presence in AR/VR. Best 3D photo-realistic AR/VR avatars driven by video, that can minimize uncanny effects, rely on person-specific models. However, existing person-specific photo-realistic 3D models are not robust to lighting, hence their results typically miss subtle facial behaviors and cause artifacts in the avatar. This is a major drawback for the scalability of these models in communication systems (e.g., Messenger, Skype, FaceTime) and AR/VR. This paper addresses previous limitations by learning a deep learning lighting model, that in combination with a high-quality 3D face tracking algorithm, provides a method for subtle and robust facial motion transfer from a regular video to a 3D photo-realistic avatar. Extensive experimental validation and comparisons to other state-of-the-art methods demonstrate the effectiveness of the proposed framework in real-world scenarios with variability in pose, expression, and illumination. Please visit https://www.youtube.com/watch?v=dtz1LgZR8cc for more results. Our project page can be found at https://www.cs.rochester.edu/u/lchen63.
Talking-head Generation with Rhythmic Head Motion
Jul 16, 2020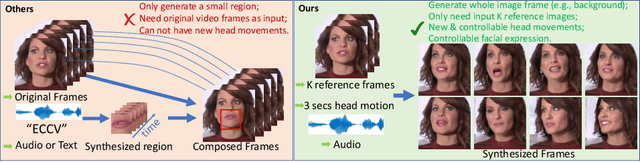
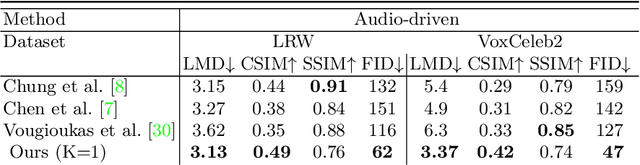
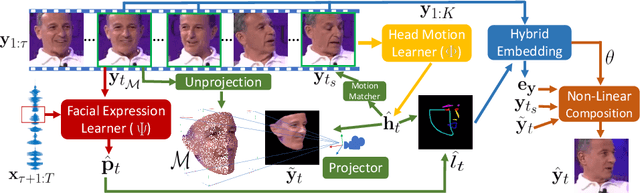
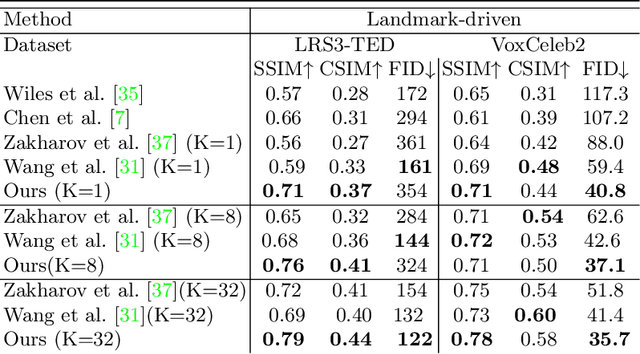
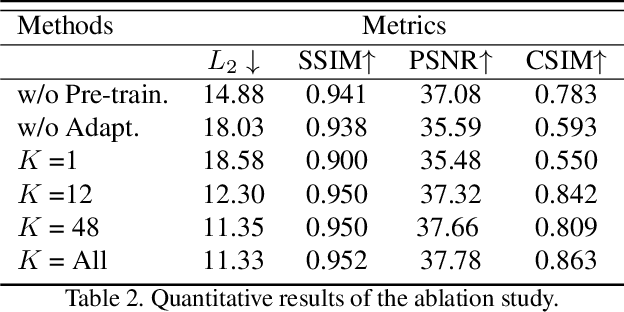
When people deliver a speech, they naturally move heads, and this rhythmic head motion conveys prosodic information. However, generating a lip-synced video while moving head naturally is challenging. While remarkably successful, existing works either generate still talkingface videos or rely on landmark/video frames as sparse/dense mapping guidance to generate head movements, which leads to unrealistic or uncontrollable video synthesis. To overcome the limitations, we propose a 3D-aware generative network along with a hybrid embedding module and a non-linear composition module. Through modeling the head motion and facial expressions1 explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. Thoughtful experiments on several standard benchmarks demonstrate that our method achieves significantly better results than the state-of-the-art methods in both quantitative and qualitative comparisons. The code is available on https://github.com/ lelechen63/Talking-head-Generation-with-Rhythmic-Head-Motion.