 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Top-1 to Top-K: A Reproducibility Study and Benchmarking of Counterfactual Explanations for Recommender Systems
Apr 21, 2026Counterfactual explanations (CEs) provide an intuitive way to understand recommender systems by identifying minimal modifications to user-item interactions that alter recommendation outcomes. Existing CE methods for recommender systems, however, have been evaluated under heterogeneous protocols, using different datasets, recommenders, metrics, and even explanation formats, which hampers reproducibility and fair comparison. Our paper systematically reproduces, re-implement, and re-evaluate eleven state-of-the-art CE methods for recommender systems, covering both native explainers (e.g., LIME-RS, SHAP, PRINCE, ACCENT, LXR, GREASE) and specific graph-based explainers originally proposed for GNNs. Here, a unified benchmarking framework is proposed to assess explainers along three dimensions: explanation format (implicit vs. explicit), evaluation level (item-level vs. list-level), and perturbation scope (user interaction vectors vs. user-item interaction graphs). Our evaluation protocol includes effectiveness, sparsity, and computational complexity metrics, and extends existing item-level assessments to top-K list-level explanations. Through extensive experiments on three real-world datasets and six representative recommender models, we analyze how well previously reported strengths of CE methods generalize across diverse setups. We observe that the trade-off between effectiveness and sparsity depends strongly on the specific method and evaluation setting, particularly under the explicit format; in addition, explainer performance remains largely consistent across item level and list level evaluations, and several graph-based explainers exhibit notable scalability limitations on large recommender graphs. Our results refine and challenge earlier conclusions about the robustness and practicality of CE generation methods in recommender systems: https://github.com/L2R-UET/CFExpRec.
Conformalized Neural Networks for Federated Uncertainty Quantification under Dual Heterogeneity
Feb 26, 2026Federated learning (FL) faces challenges in uncertainty quantification (UQ). Without reliable UQ, FL systems risk deploying overconfident models at under-resourced agents, leading to silent local failures despite seemingly satisfactory global performance. Existing federated UQ approaches often address data heterogeneity or model heterogeneity in isolation, overlooking their joint effect on coverage reliability across agents. Conformal prediction is a widely used distribution-free UQ framework, yet its applications in heterogeneous FL settings remains underexplored. We provide FedWQ-CP, a simple yet effective approach that balances empirical coverage performance with efficiency at both global and agent levels under the dual heterogeneity. FedWQ-CP performs agent-server calibration in a single communication round. On each agent, conformity scores are computed on calibration data and a local quantile threshold is derived. Each agent then transmits only its quantile threshold and calibration sample size to the server. The server simply aggregates these thresholds through a weighted average to produce a global threshold. Experimental results on seven public datasets for both classification and regression demonstrate that FedWQ-CP empirically maintains agent-wise and global coverage while producing the smallest prediction sets or intervals.
Federated-inspired Single-cell Batch Integration in Latent Space
Jan 31, 2026Advances in single-cell RNA sequencing enable the rapid generation of massive, high-dimensional datasets, yet the accumulation of data across experiments introduces batch effects that obscure true biological signals. Existing batch correction approaches either insufficiently correct batch effects or require centralized retraining on the complete dataset, limiting their applicability in distributed and continually evolving single-cell data settings. We introduce scBatchProx, a post-hoc optimization method inspired by federated learning principles for refining cell-level embeddings produced by arbitrary upstream methods. Treating each batch as a client, scBatchProx learns batch-conditioned adapters under proximal regularization, correcting batch structure directly in latent space without requiring raw expression data or centralized optimization. The method is lightweight and deployable, optimizing batch-specific adapter parameters only. Extensive experiments show that scBatchProx consistently yields relative gains of approximately 3-8% in overall embedding quality, with batch correction and biological conservation improving in 90% and 85% of data-method pairs, respectively. We envision this work as a step toward the practical refinement of learned representations in dynamic single-cell data systems.
Revisiting semi-supervised learning in the era of foundation models
Mar 12, 2025

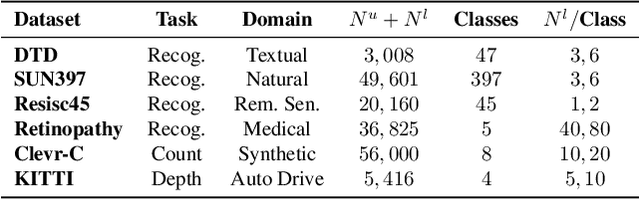
Semi-supervised learning (SSL) leverages abundant unlabeled data alongside limited labeled data to enhance learning. As vision foundation models (VFMs) increasingly serve as the backbone of vision applications, it remains unclear how SSL interacts with these pre-trained models. To address this gap, we develop new SSL benchmark datasets where frozen VFMs underperform and systematically evaluate representative SSL methods. We make a surprising observation: parameter-efficient fine-tuning (PEFT) using only labeled data often matches SSL performance, even without leveraging unlabeled data. This motivates us to revisit self-training, a conceptually simple SSL baseline, where we use the supervised PEFT model to pseudo-label unlabeled data for further training. To overcome the notorious issue of noisy pseudo-labels, we propose ensembling multiple PEFT approaches and VFM backbones to produce more robust pseudo-labels. Empirical results validate the effectiveness of this simple yet powerful approach, providing actionable insights into SSL with VFMs and paving the way for more scalable and practical semi-supervised learning in the era of foundation models.
Improving Pareto Set Learning for Expensive Multi-objective Optimization via Stein Variational Hypernetworks
Dec 23, 2024



Expensive multi-objective optimization problems (EMOPs) are common in real-world scenarios where evaluating objective functions is costly and involves extensive computations or physical experiments. Current Pareto set learning methods for such problems often rely on surrogate models like Gaussian processes to approximate the objective functions. These surrogate models can become fragmented, resulting in numerous small uncertain regions between explored solutions. When using acquisition functions such as the Lower Confidence Bound (LCB), these uncertain regions can turn into pseudo-local optima, complicating the search for globally optimal solutions. To address these challenges, we propose a novel approach called SVH-PSL, which integrates Stein Variational Gradient Descent (SVGD) with Hypernetworks for efficient Pareto set learning. Our method addresses the issues of fragmented surrogate models and pseudo-local optima by collectively moving particles in a manner that smooths out the solution space. The particles interact with each other through a kernel function, which helps maintain diversity and encourages the exploration of underexplored regions. This kernel-based interaction prevents particles from clustering around pseudo-local optima and promotes convergence towards globally optimal solutions. Our approach aims to establish robust relationships between trade-off reference vectors and their corresponding true Pareto solutions, overcoming the limitations of existing methods. Through extensive experiments across both synthetic and real-world MOO benchmarks, we demonstrate that SVH-PSL significantly improves the quality of the learned Pareto set, offering a promising solution for expensive multi-objective optimization problems.
Zero-shot Object-Level OOD Detection with Context-Aware Inpainting
Feb 07, 2024


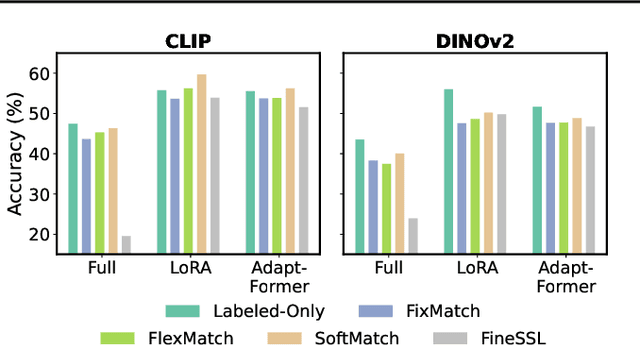
Machine learning algorithms are increasingly provided as black-box cloud services or pre-trained models, without access to their training data. This motivates the problem of zero-shot out-of-distribution (OOD) detection. Concretely, we aim to detect OOD objects that do not belong to the classifier's label set but are erroneously classified as in-distribution (ID) objects. Our approach, RONIN, uses an off-the-shelf diffusion model to replace detected objects with inpainting. RONIN conditions the inpainting process with the predicted ID label, drawing the input object closer to the in-distribution domain. As a result, the reconstructed object is very close to the original in the ID cases and far in the OOD cases, allowing RONIN to effectively distinguish ID and OOD samples. Throughout extensive experiments, we demonstrate that RONIN achieves competitive results compared to previous approaches across several datasets, both in zero-shot and non-zero-shot settings.
Controllable Expensive Multi-objective Optimization with Warm-starting Gaussian Processes
Nov 26, 2023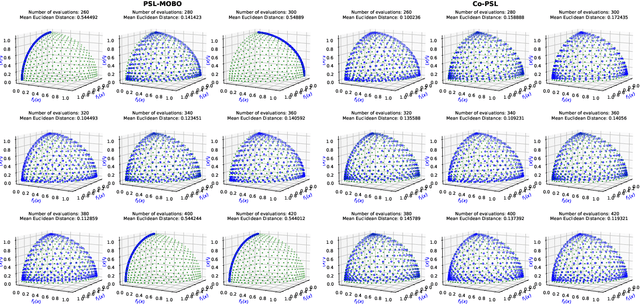
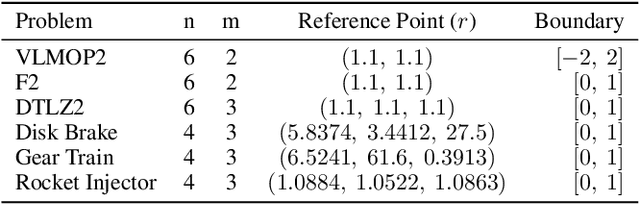
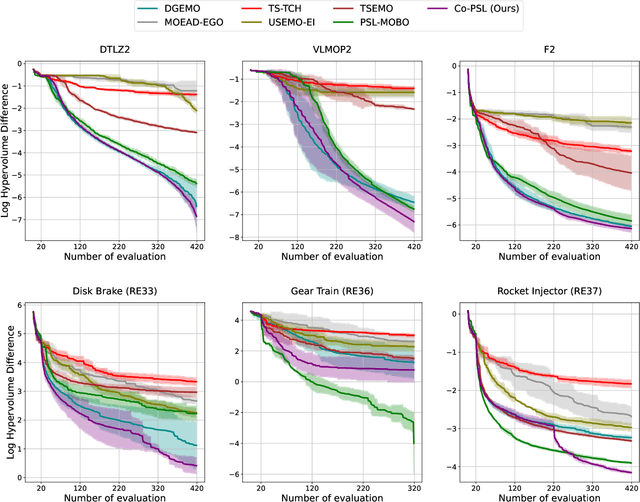
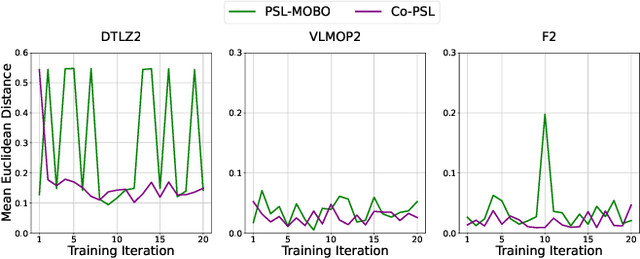
Pareto Set Learning (PSL) is a promising approach for approximating the entire Pareto front in multi-objective optimization (MOO) problems. However, existing derivative-free PSL methods are often unstable and inefficient, especially for expensive black-box MOO problems where objective function evaluations are costly. In this work, we propose to address the instability and inefficiency of existing PSL methods with a novel controllable PSL method, called Co-PSL. Particularly, Co-PSL consists of two stages: (1) warm-starting Bayesian optimization to obtain quality Gaussian Processes priors and (2) controllable Pareto set learning to accurately acquire a parametric mapping from preferences to the corresponding Pareto solutions. The former is to help stabilize the PSL process and reduce the number of expensive function evaluations. The latter is to support real-time trade-off control between conflicting objectives. Performances across synthesis and real-world MOO problems showcase the effectiveness of our Co-PSL for expensive multi-objective optimization tasks.
Improving Vietnamese Legal Question--Answering System based on Automatic Data Enrichment
Jun 08, 2023
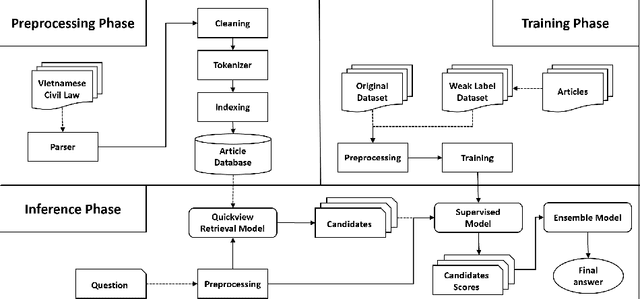


Question answering (QA) in law is a challenging problem because legal documents are much more complicated than normal texts in terms of terminology, structure, and temporal and logical relationships. It is even more difficult to perform legal QA for low-resource languages like Vietnamese where labeled data are rare and pre-trained language models are still limited. In this paper, we try to overcome these limitations by implementing a Vietnamese article-level retrieval-based legal QA system and introduce a novel method to improve the performance of language models by improving data quality through weak labeling. Our hypothesis is that in contexts where labeled data are limited, efficient data enrichment can help increase overall performance. Our experiments are designed to test multiple aspects, which demonstrate the effectiveness of the proposed technique.
Law to Binary Tree -- An Formal Interpretation of Legal Natural Language
Dec 16, 2022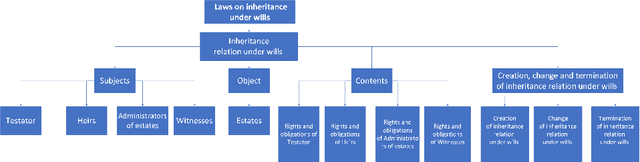
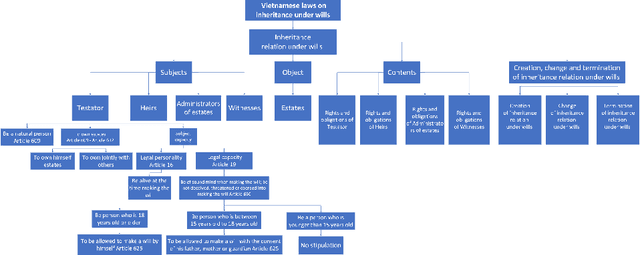
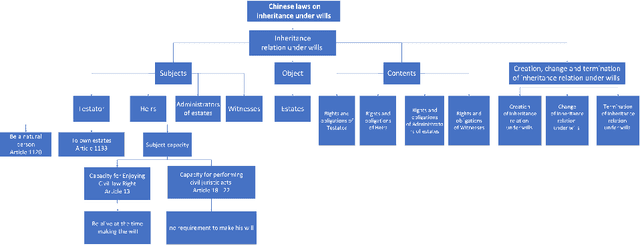
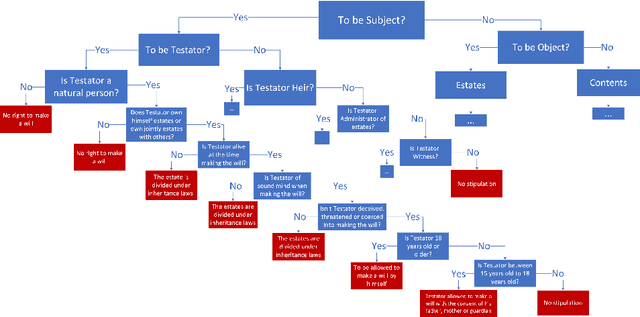
Knowledge representation and reasoning in law are essential to facilitate the automation of legal analysis and decision-making tasks. In this paper, we propose a new approach based on legal science, specifically legal taxonomy, for representing and reasoning with legal documents. Our approach interprets the regulations in legal documents as binary trees, which facilitates legal reasoning systems to make decisions and resolve logical contradictions. The advantages of this approach are twofold. First, legal reasoning can be performed on the basis of the binary tree representation of the regulations. Second, the binary tree representation of the regulations is more understandable than the existing sentence-based representations. We provide an example of how our approach can be used to interpret the regulations in a legal document.
Enhancing Few-shot Image Classification with Cosine Transformer
Nov 16, 2022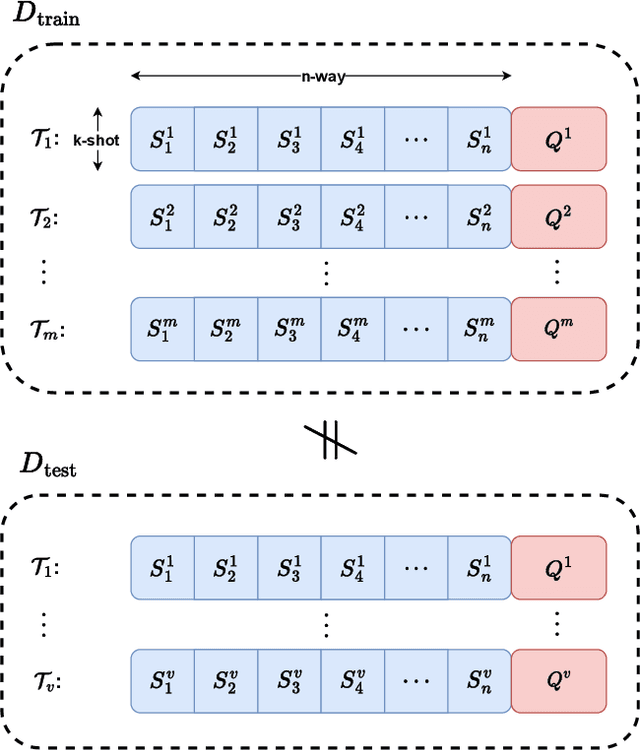

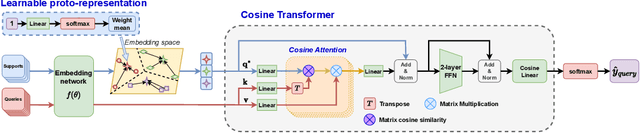
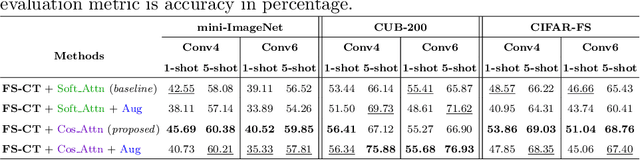
This paper addresses the few-shot image classification problem. One notable limitation of few-shot learning is the variation in describing the same category, which might result in a significant difference between small labeled support and large unlabeled query sets. Our approach is to obtain a relation heatmap between the two sets in order to label the latter one in a transductive setting manner. This can be solved by using cross-attention with the scaled dot-product mechanism. However, the magnitude differences between two separate sets of embedding vectors may cause a significant impact on the output attention map and affect model performance. We tackle this problem by improving the attention mechanism with cosine similarity. Specifically, we develop FS-CT (Few-shot Cosine Transformer), a few-shot image classification method based on prototypical embedding and transformer-based framework. The proposed Cosine attention improves FS-CT performances significantly from nearly 5% to over 20% in accuracy compared to the baseline scaled dot-product attention in various scenarios on three few-shot datasets mini-ImageNet, CUB-200, and CIFAR-FS. Additionally, we enhance the prototypical embedding for categorical representation with learnable weights before feeding them to the attention module. Our proposed method FS-CT along with the Cosine attention is simple to implement and can be applied for a wide range of applications. Our codes are available at https://github.com/vinuni-vishc/Few-Shot-Cosine-Transformer