 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting LLMs' Reasoning Capability to Infer Implicit Concepts in Legal Information Retrieval
Oct 16, 2024



Statutory law retrieval is a typical problem in legal language processing, that has various practical applications in law engineering. Modern deep learning-based retrieval methods have achieved significant results for this problem. However, retrieval systems relying on semantic and lexical correlations often exhibit limitations, particularly when handling queries that involve real-life scenarios, or use the vocabulary that is not specific to the legal domain. In this work, we focus on overcoming this weaknesses by utilizing the logical reasoning capabilities of large language models (LLMs) to identify relevant legal terms and facts related to the situation mentioned in the query. The proposed retrieval system integrates additional information from the term--based expansion and query reformulation to improve the retrieval accuracy. The experiments on COLIEE 2022 and COLIEE 2023 datasets show that extra knowledge from LLMs helps to improve the retrieval result of both lexical and semantic ranking models. The final ensemble retrieval system outperformed the highest results among all participating teams in the COLIEE 2022 and 2023 competitions.
Improving Vietnamese Legal Question--Answering System based on Automatic Data Enrichment
Jun 08, 2023
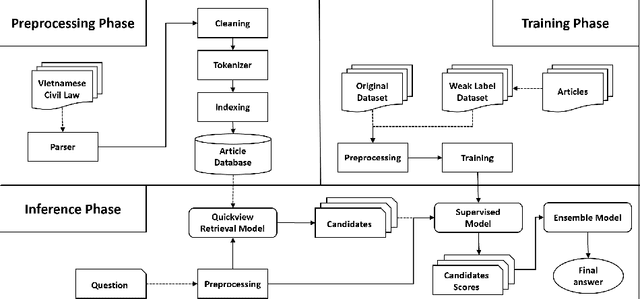


Question answering (QA) in law is a challenging problem because legal documents are much more complicated than normal texts in terms of terminology, structure, and temporal and logical relationships. It is even more difficult to perform legal QA for low-resource languages like Vietnamese where labeled data are rare and pre-trained language models are still limited. In this paper, we try to overcome these limitations by implementing a Vietnamese article-level retrieval-based legal QA system and introduce a novel method to improve the performance of language models by improving data quality through weak labeling. Our hypothesis is that in contexts where labeled data are limited, efficient data enrichment can help increase overall performance. Our experiments are designed to test multiple aspects, which demonstrate the effectiveness of the proposed technique.
Non-Standard Vietnamese Word Detection and Normalization for Text-to-Speech
Sep 07, 2022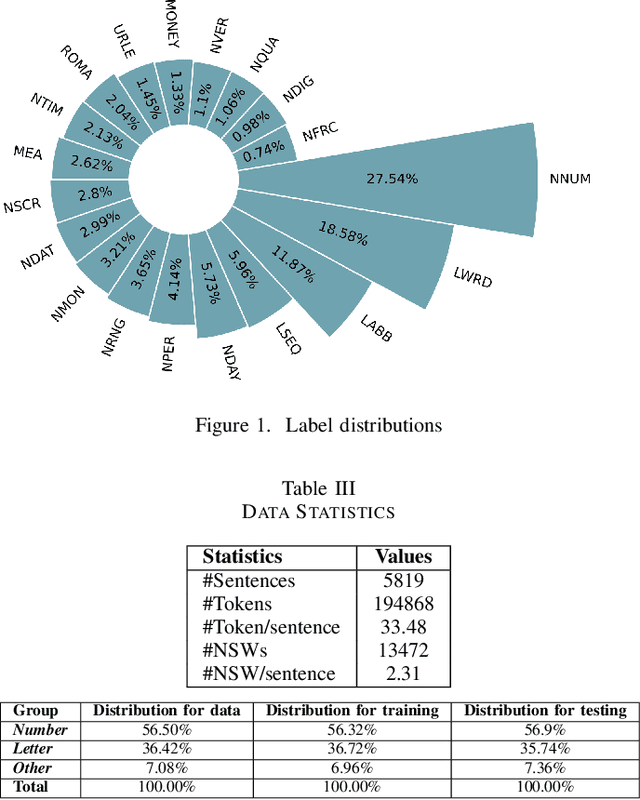
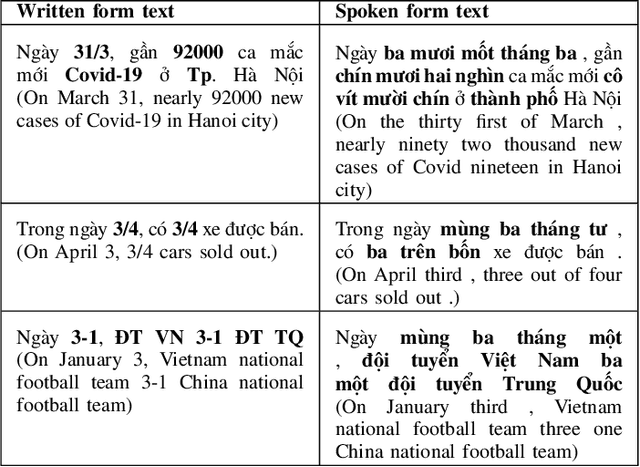

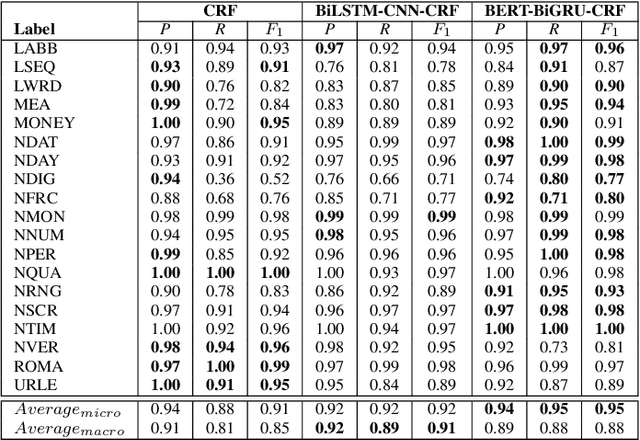
Converting written texts into their spoken forms is an essential problem in any text-to-speech (TTS) systems. However, building an effective text normalization solution for a real-world TTS system face two main challenges: (1) the semantic ambiguity of non-standard words (NSWs), e.g., numbers, dates, ranges, scores, abbreviations, and (2) transforming NSWs into pronounceable syllables, such as URL, email address, hashtag, and contact name. In this paper, we propose a new two-phase normalization approach to deal with these challenges. First, a model-based tagger is designed to detect NSWs. Then, depending on NSW types, a rule-based normalizer expands those NSWs into their final verbal forms. We conducted three empirical experiments for NSW detection using Conditional Random Fields (CRFs), BiLSTM-CNN-CRF, and BERT-BiGRU-CRF models on a manually annotated dataset including 5819 sentences extracted from Vietnamese news articles. In the second phase, we propose a forward lexicon-based maximum matching algorithm to split down the hashtag, email, URL, and contact name. The experimental results of the tagging phase show that the average F1 scores of the BiLSTM-CNN-CRF and CRF models are above 90.00%, reaching the highest F1 of 95.00% with the BERT-BiGRU-CRF model. Overall, our approach has low sentence error rates, at 8.15% with CRF and 7.11% with BiLSTM-CNN-CRF taggers, and only 6.67% with BERT-BiGRU-CRF tagger.