 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Iterative Symbolic-Aided Chain-of-Thought for Logical Reasoning
Aug 17, 2025This work introduces Symbolic-Aided Chain-of-Thought (CoT), an improved approach to standard CoT, for logical reasoning in large language models (LLMs). The key idea is to integrate lightweight symbolic representations into few-shot prompts, structuring the inference steps with a consistent strategy to make reasoning patterns more explicit within a non-iterative reasoning process. By incorporating these symbolic structures, our method preserves the generalizability of standard prompting techniques while enhancing the transparency, interpretability, and analyzability of LLM logical reasoning. Extensive experiments on four well-known logical reasoning benchmarks -- ProofWriter, FOLIO, ProntoQA, and LogicalDeduction, which cover diverse reasoning scenarios -- demonstrate the effectiveness of the proposed approach, particularly in complex reasoning tasks that require navigating multiple constraints or rules. Notably, Symbolic-Aided CoT consistently improves LLMs' reasoning capabilities across various model sizes and significantly outperforms conventional CoT on three out of four datasets, ProofWriter, ProntoQA, and LogicalDeduction.
JNLP at SemEval-2025 Task 11: Cross-Lingual Multi-Label Emotion Detection Using Generative Models
May 19, 2025With the rapid advancement of global digitalization, users from different countries increasingly rely on social media for information exchange. In this context, multilingual multi-label emotion detection has emerged as a critical research area. This study addresses SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection. Our paper focuses on two sub-tracks of this task: (1) Track A: Multi-label emotion detection, and (2) Track B: Emotion intensity. To tackle multilingual challenges, we leverage pre-trained multilingual models and focus on two architectures: (1) a fine-tuned BERT-based classification model and (2) an instruction-tuned generative LLM. Additionally, we propose two methods for handling multi-label classification: the base method, which maps an input directly to all its corresponding emotion labels, and the pairwise method, which models the relationship between the input text and each emotion category individually. Experimental results demonstrate the strong generalization ability of our approach in multilingual emotion recognition. In Track A, our method achieved Top 4 performance across 10 languages, ranking 1st in Hindi. In Track B, our approach also secured Top 5 performance in 7 languages, highlighting its simplicity and effectiveness\footnote{Our code is available at https://github.com/yingjie7/mlingual_multilabel_emo_detection.
An Effective Method using Phrase Mechanism in Neural Machine Translation
Aug 22, 2023Machine Translation is one of the essential tasks in Natural Language Processing (NLP), which has massive applications in real life as well as contributing to other tasks in the NLP research community. Recently, Transformer -based methods have attracted numerous researchers in this domain and achieved state-of-the-art results in most of the pair languages. In this paper, we report an effective method using a phrase mechanism, PhraseTransformer, to improve the strong baseline model Transformer in constructing a Neural Machine Translation (NMT) system for parallel corpora Vietnamese-Chinese. Our experiments on the MT dataset of the VLSP 2022 competition achieved the BLEU score of 35.3 on Vietnamese to Chinese and 33.2 BLEU scores on Chinese to Vietnamese data. Our code is available at https://github.com/phuongnm94/PhraseTransformer.
Miko Team: Deep Learning Approach for Legal Question Answering in ALQAC 2022
Nov 04, 2022We introduce efficient deep learning-based methods for legal document processing including Legal Document Retrieval and Legal Question Answering tasks in the Automated Legal Question Answering Competition (ALQAC 2022). In this competition, we achieve 1\textsuperscript{st} place in the first task and 3\textsuperscript{rd} place in the second task. Our method is based on the XLM-RoBERTa model that is pre-trained from a large amount of unlabeled corpus before fine-tuning to the specific tasks. The experimental results showed that our method works well in legal retrieval information tasks with limited labeled data. Besides, this method can be applied to other information retrieval tasks in low-resource languages.
JNLP Team: Deep Learning Approaches for Legal Processing Tasks in COLIEE 2021
Jun 25, 2021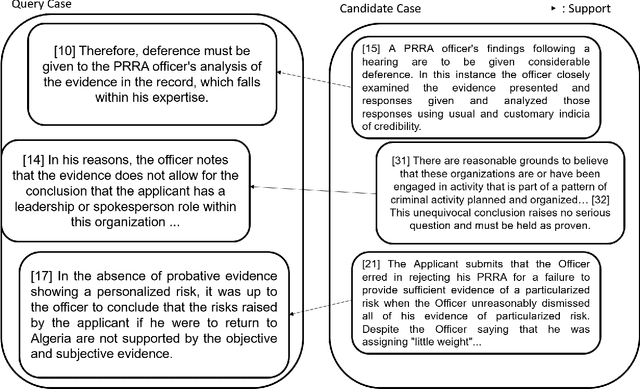



COLIEE is an annual competition in automatic computerized legal text processing. Automatic legal document processing is an ambitious goal, and the structure and semantics of the law are often far more complex than everyday language. In this article, we survey and report our methods and experimental results in using deep learning in legal document processing. The results show the difficulties as well as potentials in this family of approaches.
ParaLaw Nets -- Cross-lingual Sentence-level Pretraining for Legal Text Processing
Jun 25, 2021


Ambiguity is a characteristic of natural language, which makes expression ideas flexible. However, in a domain that requires accurate statements, it becomes a barrier. Specifically, a single word can have many meanings and multiple words can have the same meaning. When translating a text into a foreign language, the translator needs to determine the exact meaning of each element in the original sentence to produce the correct translation sentence. From that observation, in this paper, we propose ParaLaw Nets, a pretrained model family using sentence-level cross-lingual information to reduce ambiguity and increase the performance in legal text processing. This approach achieved the best result in the Question Answering task of COLIEE-2021.
JNLP Team: Deep Learning for Legal Processing in COLIEE 2020
Nov 04, 2020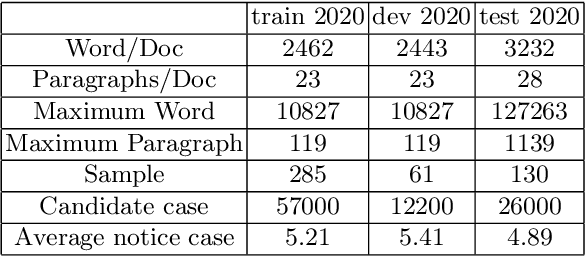
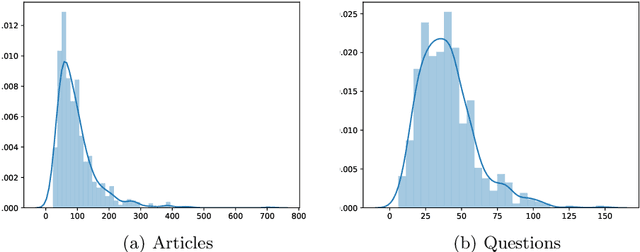
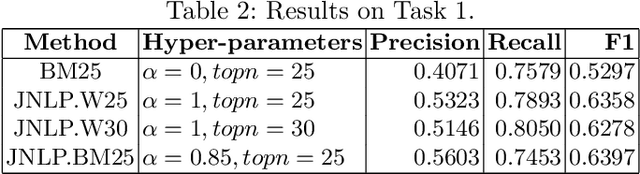
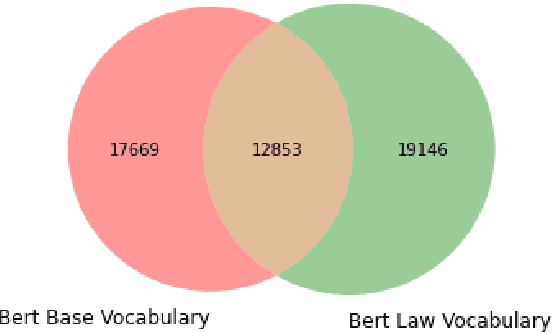
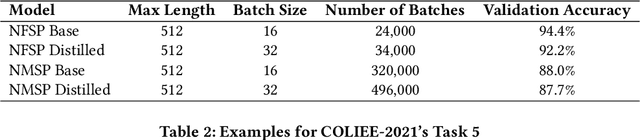
We propose deep learning based methods for automatic systems of legal retrieval and legal question-answering in COLIEE 2020. These systems are all characterized by being pre-trained on large amounts of data before being finetuned for the specified tasks. This approach helps to overcome the data scarcity and achieve good performance, thus can be useful for tackling related problems in information retrieval, and decision support in the legal domain. Besides, the approach can be explored to deal with other domain specific problems.