 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Representation Misdirection for Large Language Model Unlearning
Jan 31, 2025Representation Misdirection (RM) and variants are established large language model (LLM) unlearning methods with state-of-the-art performance. In this paper, we show that RM methods inherently reduce models' robustness, causing them to misbehave even when a single non-adversarial forget-token is in the retain-query. Toward understanding underlying causes, we reframe the unlearning process as backdoor attacks and defenses: forget-tokens act as backdoor triggers that, when activated in retain-queries, cause disruptions in RM models' behaviors, similar to successful backdoor attacks. To mitigate this vulnerability, we propose Random Noise Augmentation -- a model and method agnostic approach with theoretical guarantees for improving the robustness of RM methods. Extensive experiments demonstrate that RNA significantly improves the robustness of RM models while enhancing the unlearning performances.
On Effects of Steering Latent Representation for Large Language Model Unlearning
Aug 12, 2024



Representation Misdirection for Unlearning (RMU), which steers model representation in the intermediate layer to a target random representation, is an effective method for large language model (LLM) unlearning. Despite its high performance, the underlying cause and explanation remain underexplored. In this paper, we first theoretically demonstrate that steering forget representations in the intermediate layer reduces token confidence, causing LLMs to generate wrong or nonsense responses. Second, we investigate how the coefficient influences the alignment of forget-sample representations with the random direction and hint at the optimal coefficient values for effective unlearning across different network layers. Third, we show that RMU unlearned models are robust against adversarial jailbreak attacks. Last, our empirical analysis shows that RMU is less effective when applied to the middle and later layers in LLMs. To resolve this drawback, we propose Adaptive RMU -- a simple yet effective alternative method that makes unlearning effective with most layers. Extensive experiments demonstrate that Adaptive RMU significantly improves the unlearning performance compared to prior art while incurring no additional computational cost.
Class based Influence Functions for Error Detection
May 02, 2023


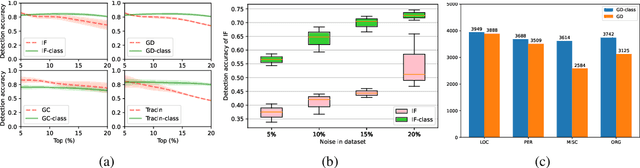
Influence functions (IFs) are a powerful tool for detecting anomalous examples in large scale datasets. However, they are unstable when applied to deep networks. In this paper, we provide an explanation for the instability of IFs and develop a solution to this problem. We show that IFs are unreliable when the two data points belong to two different classes. Our solution leverages class information to improve the stability of IFs. Extensive experiments show that our modification significantly improves the performance and stability of IFs while incurring no additional computational cost.