 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
ZeFaV: Boosting Large Language Models for Zero-shot Fact Verification
Nov 18, 2024In this paper, we propose ZeFaV - a zero-shot based fact-checking verification framework to enhance the performance on fact verification task of large language models by leveraging the in-context learning ability of large language models to extract the relations among the entities within a claim, re-organized the information from the evidence in a relationally logical form, and combine the above information with the original evidence to generate the context from which our fact-checking model provide verdicts for the input claims. We conducted empirical experiments to evaluate our approach on two multi-hop fact-checking datasets including HoVer and FEVEROUS, and achieved potential results results comparable to other state-of-the-art fact verification task methods.
Federated Learning for Non-IID Data via Client Variance Reduction and Adaptive Server Update
Jul 18, 2022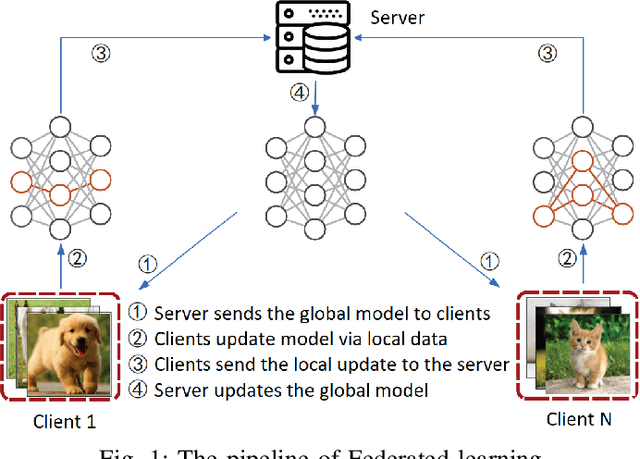
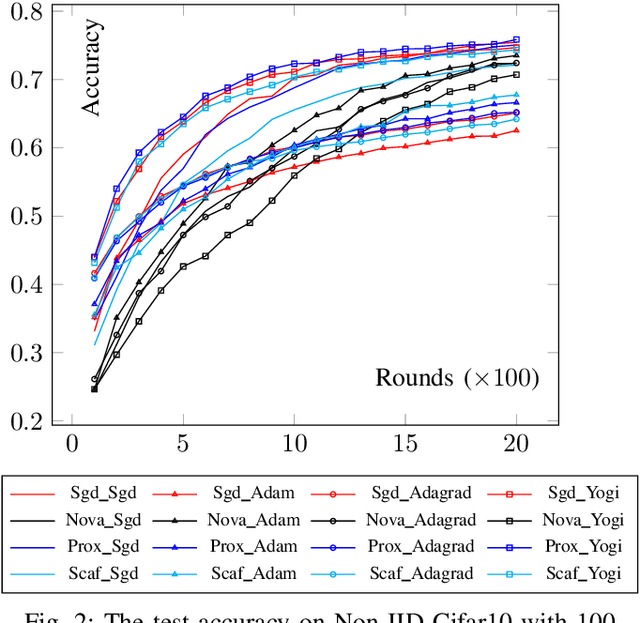
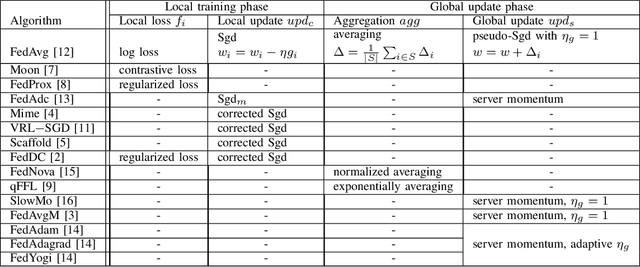

Federated learning (FL) is an emerging technique used to collaboratively train a global machine learning model while keeping the data localized on the user devices. The main obstacle to FL's practical implementation is the Non-Independent and Identical (Non-IID) data distribution across users, which slows convergence and degrades performance. To tackle this fundamental issue, we propose a method (ComFed) that enhances the whole training process on both the client and server sides. The key idea of ComFed is to simultaneously utilize client-variance reduction techniques to facilitate server aggregation and global adaptive update techniques to accelerate learning. Our experiments on the Cifar-10 classification task show that ComFed can improve state-of-the-art algorithms dedicated to Non-IID data.
An Ensemble Boosting Model for Predicting Transfer to the Pediatric Intensive Care Unit
Jul 16, 2017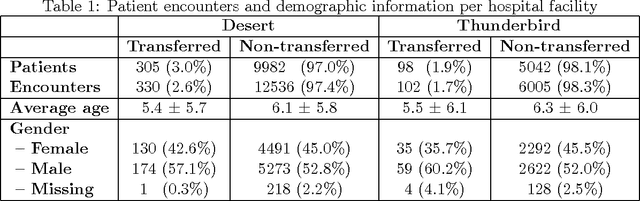
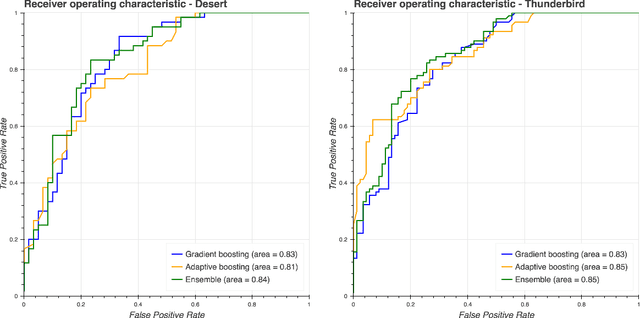
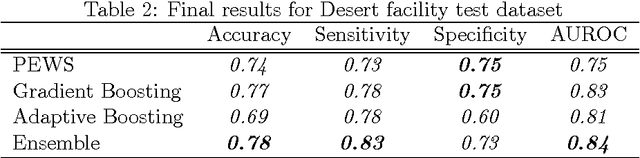
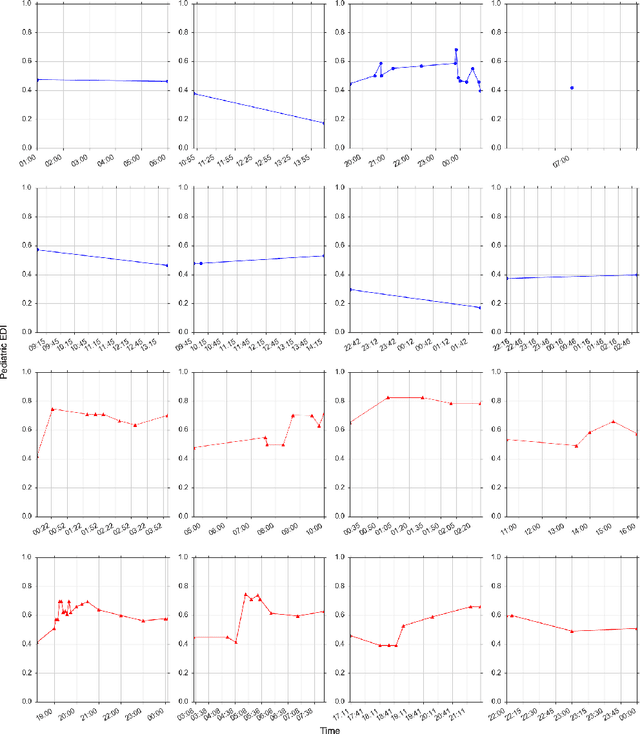
Our work focuses on the problem of predicting the transfer of pediatric patients from the general ward of a hospital to the pediatric intensive care unit. Using data collected over 5.5 years from the electronic health records of two medical facilities, we develop classifiers based on adaptive boosting and gradient tree boosting. We further combine these learned classifiers into an ensemble model and compare its performance to a modified pediatric early warning score (PEWS) baseline that relies on expert defined guidelines. To gauge model generalizability, we perform an inter-facility evaluation where we train our algorithm on data from one facility and perform evaluation on a hidden test dataset from a separate facility. We show that improvements are witnessed over the PEWS baseline in accuracy (0.77 vs. 0.69), sensitivity (0.80 vs. 0.68), specificity (0.74 vs. 0.70) and AUROC (0.85 vs. 0.73).
Exploring tradeoffs in pleiotropy and redundancy using evolutionary computing
Apr 07, 2004Evolutionary computation algorithms are increasingly being used to solve optimization problems as they have many advantages over traditional optimization algorithms. In this paper we use evolutionary computation to study the trade-off between pleiotropy and redundancy in a client-server based network. Pleiotropy is a term used to describe components that perform multiple tasks, while redundancy refers to multiple components performing one same task. Pleiotropy reduces cost but lacks robustness, while redundancy increases network reliability but is more costly, as together, pleiotropy and redundancy build flexibility and robustness into systems. Therefore it is desirable to have a network that contains a balance between pleiotropy and redundancy. We explore how factors such as link failure probability, repair rates, and the size of the network influence the design choices that we explore using genetic algorithms.
* 10 pages, 6 figures