 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Machine Learning Models for Early Detection of Hospital-Acquired Infections
Nov 15, 2023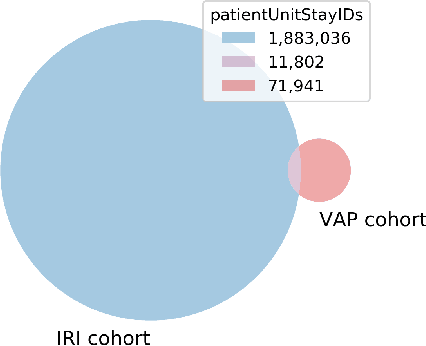

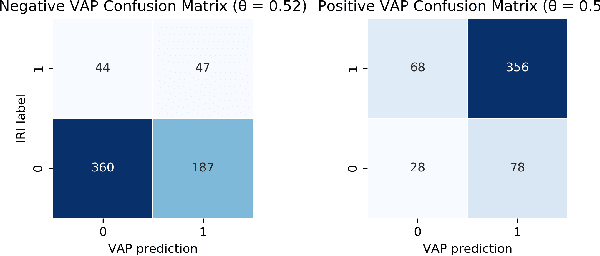

As more and more infection-specific machine learning models are developed and planned for clinical deployment, simultaneously running predictions from different models may provide overlapping or even conflicting information. It is important to understand the concordance and behavior of parallel models in deployment. In this study, we focus on two models for the early detection of hospital-acquired infections (HAIs): 1) the Infection Risk Index (IRI) and 2) the Ventilator-Associated Pneumonia (VAP) prediction model. The IRI model was built to predict all HAIs, whereas the VAP model identifies patients at risk of developing ventilator-associated pneumonia. These models could make important improvements in patient outcomes and hospital management of infections through early detection of infections and in turn, enable early interventions. The two models vary in terms of infection label definition, cohort selection, and prediction schema. In this work, we present a comparative analysis between the two models to characterize concordances and confusions in predicting HAIs by these models. The learnings from this study will provide important findings for how to deploy multiple concurrent disease-specific models in the future.
An Ensemble Boosting Model for Predicting Transfer to the Pediatric Intensive Care Unit
Jul 16, 2017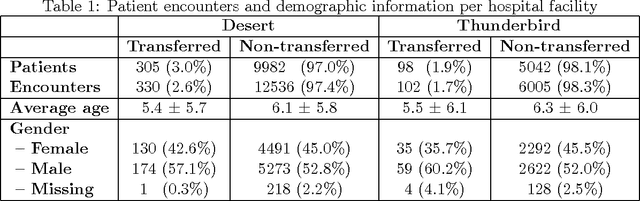
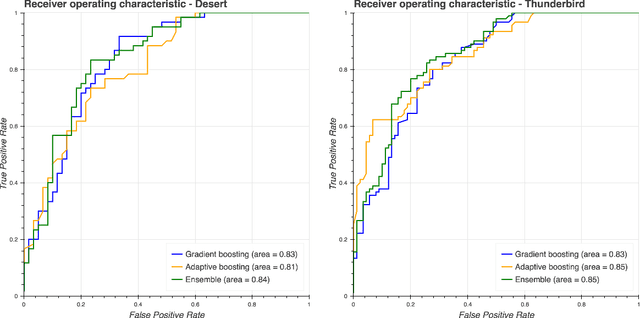
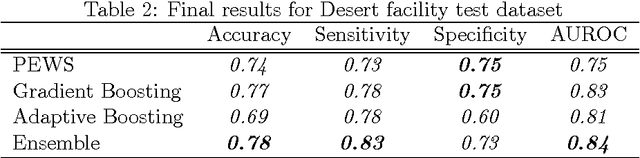
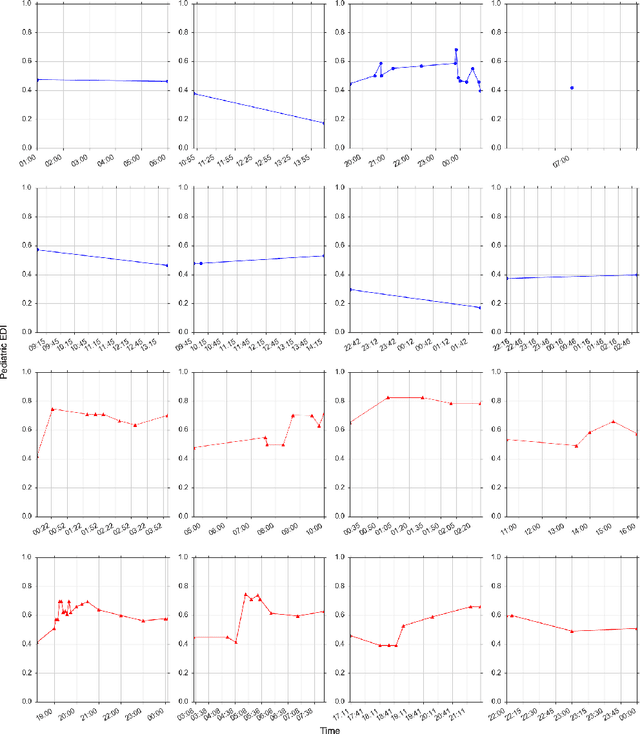
Our work focuses on the problem of predicting the transfer of pediatric patients from the general ward of a hospital to the pediatric intensive care unit. Using data collected over 5.5 years from the electronic health records of two medical facilities, we develop classifiers based on adaptive boosting and gradient tree boosting. We further combine these learned classifiers into an ensemble model and compare its performance to a modified pediatric early warning score (PEWS) baseline that relies on expert defined guidelines. To gauge model generalizability, we perform an inter-facility evaluation where we train our algorithm on data from one facility and perform evaluation on a hidden test dataset from a separate facility. We show that improvements are witnessed over the PEWS baseline in accuracy (0.77 vs. 0.69), sensitivity (0.80 vs. 0.68), specificity (0.74 vs. 0.70) and AUROC (0.85 vs. 0.73).