 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormal Guidance is what Attention Needs
May 26, 2026We consider training classifiers for 3D medical images using only one binary label for the entire volume rather than a label for each 2D slice. In such weakly supervised settings, can we learn accurate classifiers for slice-level predictions? Attention-based multiple instance learning (MIL) can produce an attention score for every slice. Yet recent work demonstrates that a simple center-focused baseline that ignores image content can outperform attention-based and transformer-based MIL at slice-level classification of 3D brain scans. We show this baseline also outperforms existing MIL at slice-level classification of thoracic and abdominal CT scans. Motivated by this baseline, we propose Normal Guidance, a regularization technique that encourages the learned attention distribution to follow a bell-shaped curve. Across three medical imaging datasets totaling over 4 million 2D slices, we show our Normal Guidance enables attention-based and transformer-based MIL methods to deliver significantly better slice-level localization than the state-of-the-art while remaining competitive at whole-scan classification.
Synthetic Data Reveals Generalization Gaps in Correlated Multiple Instance Learning
Oct 29, 2025Multiple instance learning (MIL) is often used in medical imaging to classify high-resolution 2D images by processing patches or classify 3D volumes by processing slices. However, conventional MIL approaches treat instances separately, ignoring contextual relationships such as the appearance of nearby patches or slices that can be essential in real applications. We design a synthetic classification task where accounting for adjacent instance features is crucial for accurate prediction. We demonstrate the limitations of off-the-shelf MIL approaches by quantifying their performance compared to the optimal Bayes estimator for this task, which is available in closed-form. We empirically show that newer correlated MIL methods still struggle to generalize as well as possible when trained from scratch on tens of thousands of instances.
Learning Hyperparameters via a Data-Emphasized Variational Objective
Feb 03, 2025



When training large flexible models, practitioners often rely on grid search to select hyperparameters that control over-fitting. This grid search has several disadvantages: the search is computationally expensive, requires carving out a validation set that reduces the available data for training, and requires users to specify candidate values. In this paper, we propose an alternative: directly learning regularization hyperparameters on the full training set via the evidence lower bound ("ELBo") objective from variational methods. For deep neural networks with millions of parameters, we recommend a modified ELBo that upweights the influence of the data likelihood relative to the prior. Our proposed technique overcomes all three disadvantages of grid search. In a case study on transfer learning of image classifiers, we show how our method reduces the 88+ hour grid search of past work to under 3 hours while delivering comparable accuracy. We further demonstrate how our approach enables efficient yet accurate approximations of Gaussian processes with learnable length-scale kernels.
Learning the Regularization Strength for Deep Fine-Tuning via a Data-Emphasized Variational Objective
Oct 25, 2024



A number of popular transfer learning methods rely on grid search to select regularization hyperparameters that control over-fitting. This grid search requirement has several key disadvantages: the search is computationally expensive, requires carving out a validation set that reduces the size of available data for model training, and requires practitioners to specify candidate values. In this paper, we propose an alternative to grid search: directly learning regularization hyperparameters on the full training set via model selection techniques based on the evidence lower bound ("ELBo") objective from variational methods. For deep neural networks with millions of parameters, we specifically recommend a modified ELBo that upweights the influence of the data likelihood relative to the prior while remaining a valid bound on the evidence for Bayesian model selection. Our proposed technique overcomes all three disadvantages of grid search. We demonstrate effectiveness on image classification tasks on several datasets, yielding heldout accuracy comparable to existing approaches with far less compute time.
Transfer Learning with Informative Priors: Simple Baselines Better than Previously Reported
May 24, 2024
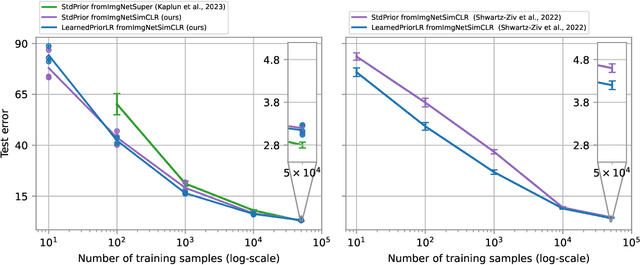


We pursue transfer learning to improve classifier accuracy on a target task with few labeled examples available for training. Recent work suggests that using a source task to learn a prior distribution over neural net weights, not just an initialization, can boost target task performance. In this study, we carefully compare transfer learning with and without source task informed priors across 5 datasets. We find that standard transfer learning informed by an initialization only performs far better than reported in previous comparisons. The relative gains of methods using informative priors over standard transfer learning vary in magnitude across datasets. For the scenario of 5-300 examples per class, we find negative or negligible gains on 2 datasets, modest gains (between 1.5-3 points of accuracy) on 2 other datasets, and substantial gains (>8 points) on one dataset. Among methods using informative priors, we find that an isotropic covariance appears competitive with learned low-rank covariance matrix while being substantially simpler to understand and tune. Further analysis suggests that the mechanistic justification for informed priors -- hypothesized improved alignment between train and test loss landscapes -- is not consistently supported due to high variability in empirical landscapes. We release code to allow independent reproduction of all experiments.
A Probabilistic Method to Predict Classifier Accuracy on Larger Datasets given Small Pilot Data
Nov 29, 2023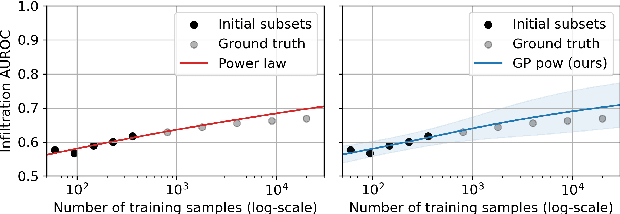

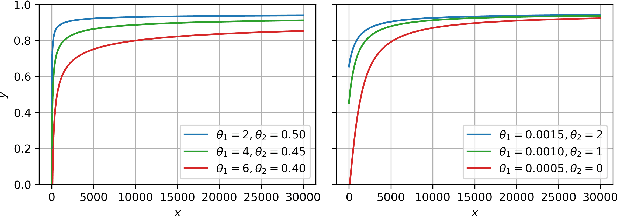
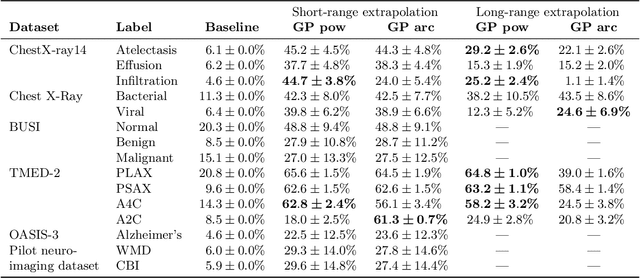
Practitioners building classifiers often start with a smaller pilot dataset and plan to grow to larger data in the near future. Such projects need a toolkit for extrapolating how much classifier accuracy may improve from a 2x, 10x, or 50x increase in data size. While existing work has focused on finding a single "best-fit" curve using various functional forms like power laws, we argue that modeling and assessing the uncertainty of predictions is critical yet has seen less attention. In this paper, we propose a Gaussian process model to obtain probabilistic extrapolations of accuracy or similar performance metrics as dataset size increases. We evaluate our approach in terms of error, likelihood, and coverage across six datasets. Though we focus on medical tasks and image modalities, our open source approach generalizes to any kind of classifier.
A Comparative Analysis of Machine Learning Models for Early Detection of Hospital-Acquired Infections
Nov 15, 2023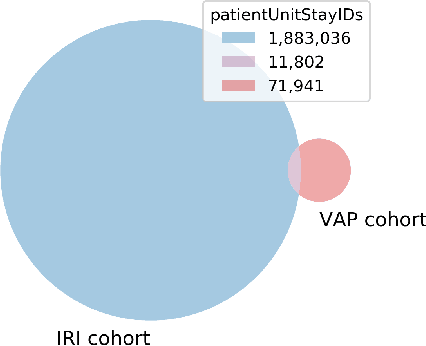

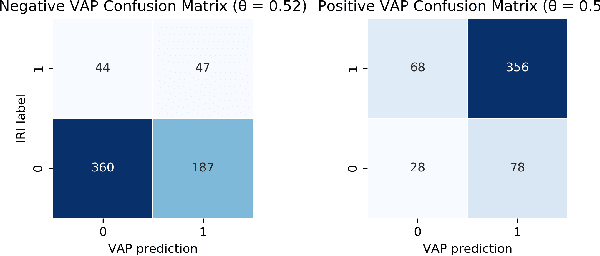

As more and more infection-specific machine learning models are developed and planned for clinical deployment, simultaneously running predictions from different models may provide overlapping or even conflicting information. It is important to understand the concordance and behavior of parallel models in deployment. In this study, we focus on two models for the early detection of hospital-acquired infections (HAIs): 1) the Infection Risk Index (IRI) and 2) the Ventilator-Associated Pneumonia (VAP) prediction model. The IRI model was built to predict all HAIs, whereas the VAP model identifies patients at risk of developing ventilator-associated pneumonia. These models could make important improvements in patient outcomes and hospital management of infections through early detection of infections and in turn, enable early interventions. The two models vary in terms of infection label definition, cohort selection, and prediction schema. In this work, we present a comparative analysis between the two models to characterize concordances and confusions in predicting HAIs by these models. The learnings from this study will provide important findings for how to deploy multiple concurrent disease-specific models in the future.