 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-VLN: Zero-Shot Vision-and-Language Navigation With Explicit Spatial Perception and Exploration
Jan 19, 2026Zero-shot Vision-and-Language Navigation (VLN) agents leveraging Large Language Models (LLMs) excel in generalization but suffer from insufficient spatial perception. Focusing on complex continuous environments, we categorize key perceptual bottlenecks into three spatial challenges: door interaction,multi-room navigation, and ambiguous instruction execution, where existing methods consistently suffer high failure rates. We present Spatial-VLN, a perception-guided exploration framework designed to overcome these challenges. The framework consists of two main modules. The Spatial Perception Enhancement (SPE) module integrates panoramic filtering with specialized door and region experts to produce spatially coherent, cross-view consistent perceptual representations. Building on this foundation, our Explored Multi-expert Reasoning (EMR) module uses parallel LLM experts to address waypoint-level semantics and region-level spatial transitions. When discrepancies arise between expert predictions, a query-and-explore mechanism is activated, prompting the agent to actively probe critical areas and resolve perceptual ambiguities. Experiments on VLN-CE demonstrate that Spatial VLN achieves state-of-the-art performance using only low-cost LLMs. Furthermore, to validate real-world applicability, we introduce a value-based waypoint sampling strategy that effectively bridges the Sim2Real gap. Extensive real-world evaluations confirm that our framework delivers superior generalization and robustness in complex environments. Our codes and videos are available at https://yueluhhxx.github.io/Spatial-VLN-web/.
MetaBGM: Dynamic Soundtrack Transformation For Continuous Multi-Scene Experiences With Ambient Awareness And Personalization
Sep 05, 2024



This paper introduces MetaBGM, a groundbreaking framework for generating background music that adapts to dynamic scenes and real-time user interactions. We define multi-scene as variations in environmental contexts, such as transitions in game settings or movie scenes. To tackle the challenge of converting backend data into music description texts for audio generation models, MetaBGM employs a novel two-stage generation approach that transforms continuous scene and user state data into these texts, which are then fed into an audio generation model for real-time soundtrack creation. Experimental results demonstrate that MetaBGM effectively generates contextually relevant and dynamic background music for interactive applications.
Security Code Review by LLMs: A Deep Dive into Responses
Jan 29, 2024Security code review aims to combine automated tools and manual efforts to detect security defects during development. The rapid development of Large Language Models (LLMs) has shown promising potential in software development, as well as opening up new possibilities in automated security code review. To explore the challenges of applying LLMs in practical code review for security defect detection, this study compared the detection performance of three state-of-the-art LLMs (Gemini Pro, GPT-4, and GPT-3.5) under five prompts on 549 code files that contain security defects from real-world code reviews. Through analyzing 82 responses generated by the best-performing LLM-prompt combination based on 100 randomly selected code files, we extracted and categorized quality problems present in these responses into 5 themes and 16 categories. Our results indicate that the responses produced by LLMs often suffer from verbosity, vagueness, and incompleteness, highlighting the necessity to enhance their conciseness, understandability, and compliance to security defect detection. This work reveals the deficiencies of LLM-generated responses in security code review and paves the way for future optimization of LLMs towards this task.
MonoGAE: Roadside Monocular 3D Object Detection with Ground-Aware Embeddings
Sep 30, 2023Although the majority of recent autonomous driving systems concentrate on developing perception methods based on ego-vehicle sensors, there is an overlooked alternative approach that involves leveraging intelligent roadside cameras to help extend the ego-vehicle perception ability beyond the visual range. We discover that most existing monocular 3D object detectors rely on the ego-vehicle prior assumption that the optical axis of the camera is parallel to the ground. However, the roadside camera is installed on a pole with a pitched angle, which makes the existing methods not optimal for roadside scenes. In this paper, we introduce a novel framework for Roadside Monocular 3D object detection with ground-aware embeddings, named MonoGAE. Specifically, the ground plane is a stable and strong prior knowledge due to the fixed installation of cameras in roadside scenarios. In order to reduce the domain gap between the ground geometry information and high-dimensional image features, we employ a supervised training paradigm with a ground plane to predict high-dimensional ground-aware embeddings. These embeddings are subsequently integrated with image features through cross-attention mechanisms. Furthermore, to improve the detector's robustness to the divergences in cameras' installation poses, we replace the ground plane depth map with a novel pixel-level refined ground plane equation map. Our approach demonstrates a substantial performance advantage over all previous monocular 3D object detectors on widely recognized 3D detection benchmarks for roadside cameras. The code and pre-trained models will be released soon.
Relation-Specific Attentions over Entity Mentions for Enhanced Document-Level Relation Extraction
May 28, 2022
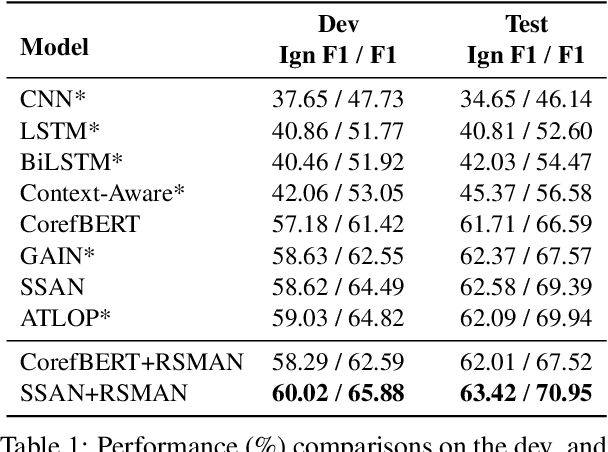
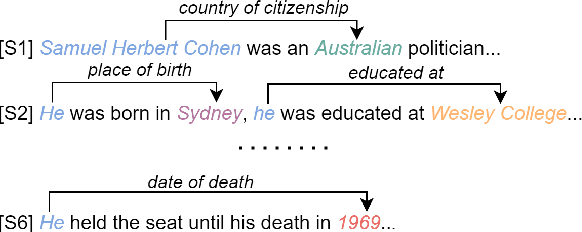

Compared with traditional sentence-level relation extraction, document-level relation extraction is a more challenging task where an entity in a document may be mentioned multiple times and associated with multiple relations. However, most methods of document-level relation extraction do not distinguish between mention-level features and entity-level features, and just apply simple pooling operation for aggregating mention-level features into entity-level features. As a result, the distinct semantics between the different mentions of an entity are overlooked. To address this problem, we propose RSMAN in this paper which performs selective attentions over different entity mentions with respect to candidate relations. In this manner, the flexible and relation-specific representations of entities are obtained which indeed benefit relation classification. Our extensive experiments upon two benchmark datasets show that our RSMAN can bring significant improvements for some backbone models to achieve state-of-the-art performance, especially when an entity have multiple mentions in the document.