 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025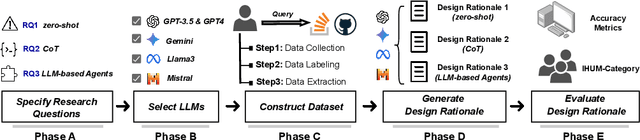
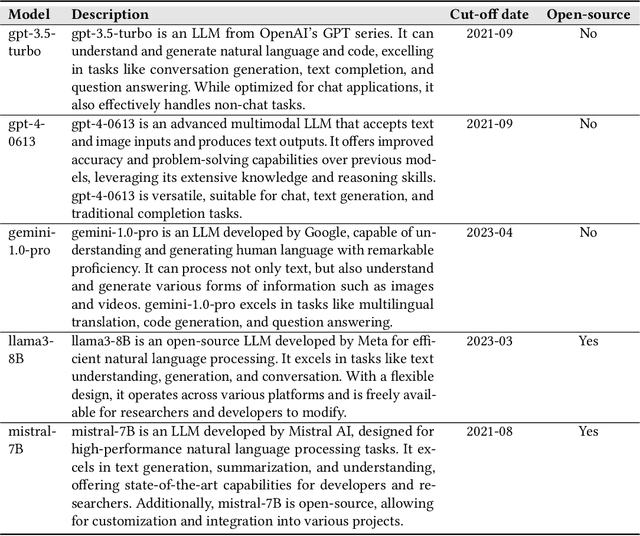
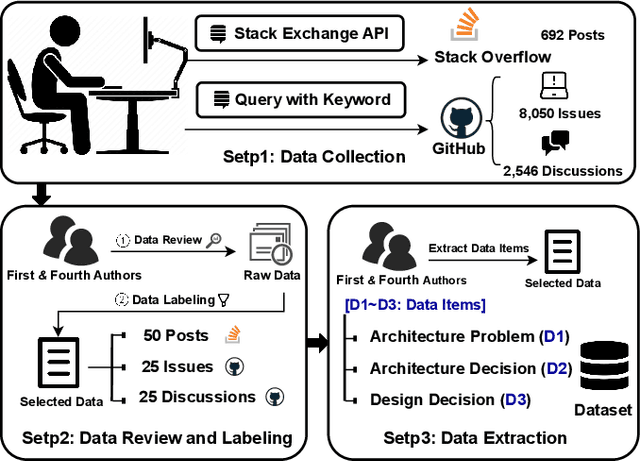
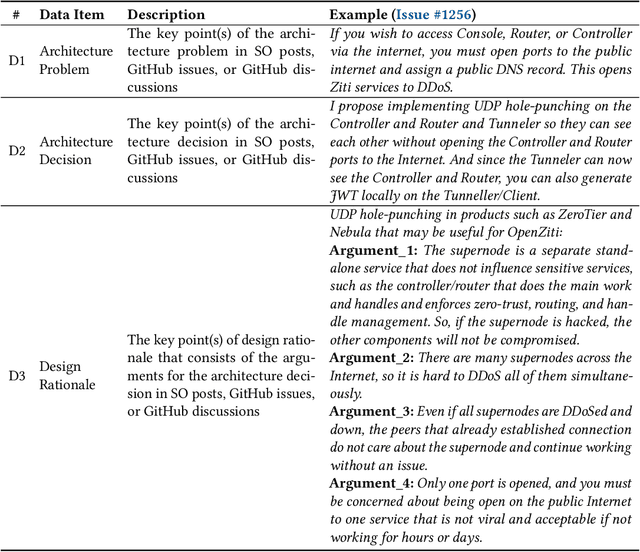
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.
LessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Feb 10, 2025
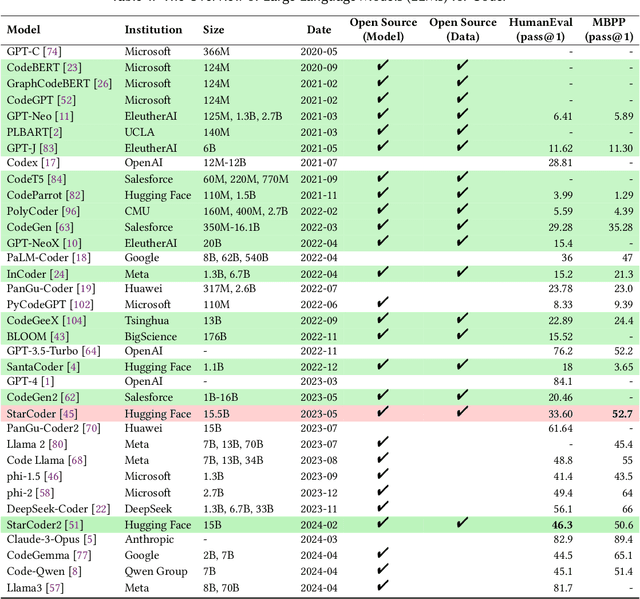

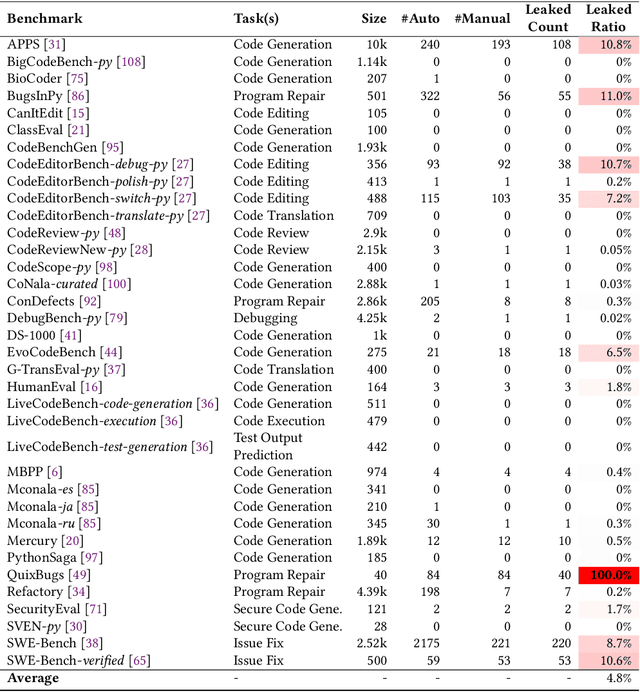
Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.
Copilot Refinement: Addressing Code Smells in Copilot-Generated Python Code
Jan 25, 2024



As one of the most popular dynamic languages, Python experiences a decrease in readability and maintainability when code smells are present. Recent advancements in Large Language Models have sparked growing interest in AI-enabled tools for both code generation and refactoring. GitHub Copilot is one such tool that has gained widespread usage. Copilot Chat, released on September 2023, functions as an interactive tool aims at facilitating natural language-powered coding. However, limited attention has been given to understanding code smells in Copilot-generated Python code and Copilot's ability to fix the code smells it generates. To this end, we built a dataset comprising 102 code smells in Copilot-generated Python code. Our aim is to first explore the occurrence of code smells in Copilot-generated Python code and then evaluate the effectiveness of Copilot in fixing these code smells employing different prompts. The results show that 8 out of 10 types of Python smells can be detected in Copilot-generated Python code, among which Multiply-Nested Container is the most common one. For these code smells, Copilot Chat achieves a highest fixing rate of 87.1%, showing promise in fixing Python code smells generated by Copilot itself. Besides, the effectiveness of Copilot Chat in fixing these smells can be improved with the provision of more detailed prompts. However, using Copilot Chat to fix these smells might introduce new code smells.
3D Human Motion Prediction: A Survey
Mar 07, 2022
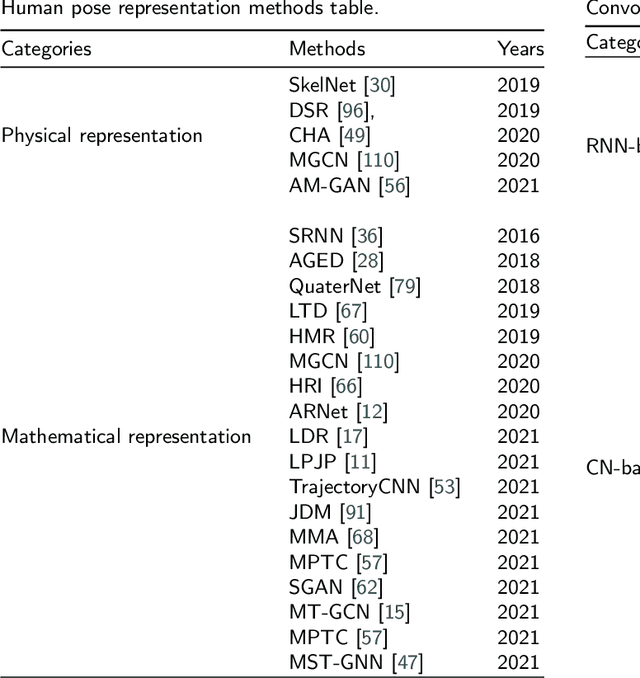
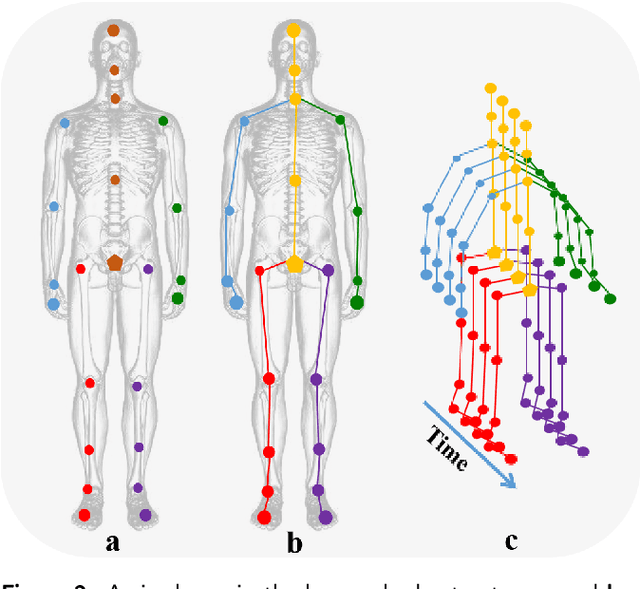
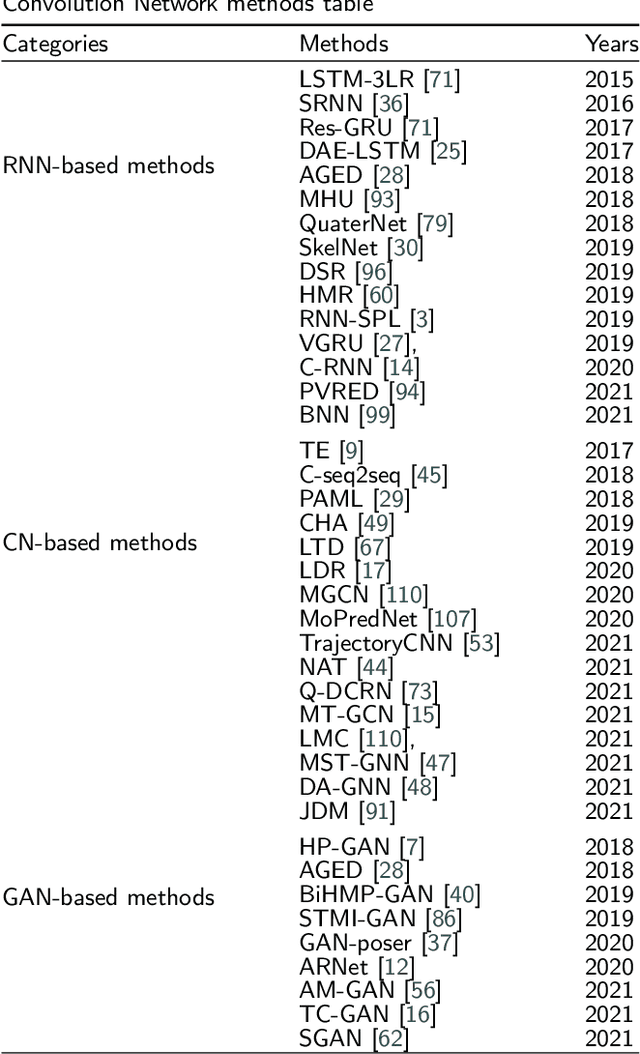
3D human motion prediction, predicting future poses from a given sequence, is an issue of great significance and challenge in computer vision and machine intelligence, which can help machines in understanding human behaviors. Due to the increasing development and understanding of Deep Neural Networks (DNNs) and the availability of large-scale human motion datasets, the human motion prediction has been remarkably advanced with a surge of interest among academia and industrial community. In this context, a comprehensive survey on 3D human motion prediction is conducted for the purpose of retrospecting and analyzing relevant works from existing released literature. In addition, a pertinent taxonomy is constructed to categorize these existing approaches for 3D human motion prediction. In this survey, relevant methods are categorized into three categories: human pose representation, network structure design, and \textit{prediction target}. We systematically review all relevant journal and conference papers in the field of human motion prediction since 2015, which are presented in detail based on proposed categorizations in this survey. Furthermore, the outline for the public benchmark datasets, evaluation criteria, and performance comparisons are respectively presented in this paper. The limitations of the state-of-the-art methods are discussed as well, hoping for paving the way for future explorations.