 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Paper and Code
Feb 10, 2025
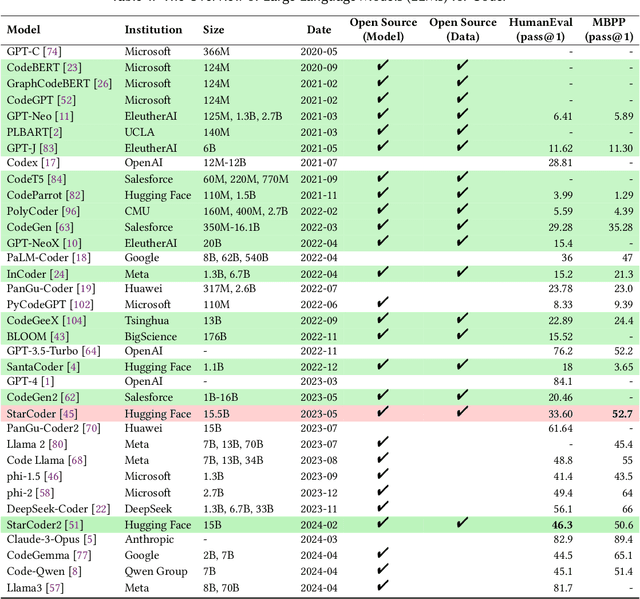

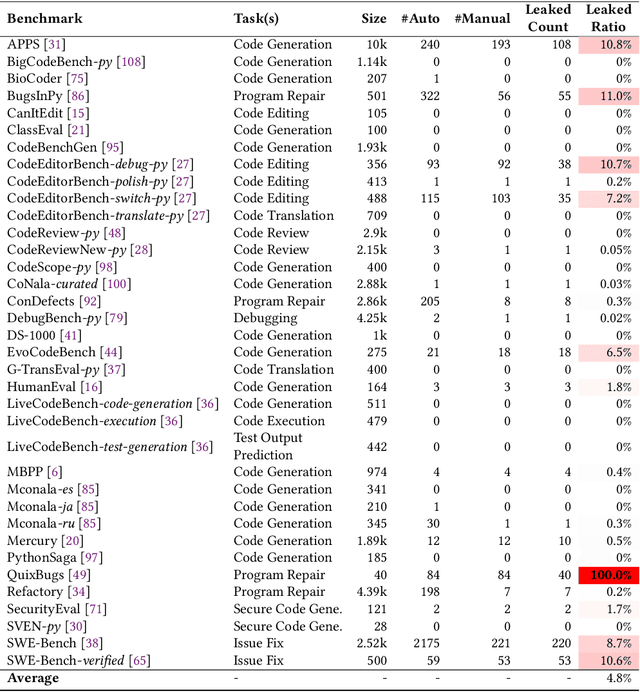
Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.