 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Caption Detailness for Data-Efficient Text-to-Image Generation
May 21, 2025Training text-to-image (T2I) models with detailed captions can significantly improve their generation quality. Existing methods often rely on simplistic metrics like caption length to represent the detailness of the caption in the T2I training set. In this paper, we propose a new metric to estimate caption detailness based on two aspects: image coverage rate (ICR), which evaluates whether the caption covers all regions/objects in the image, and average object detailness (AOD), which quantifies the detailness of each object's description. Through experiments on the COCO dataset using ShareGPT4V captions, we demonstrate that T2I models trained on high-ICR and -AOD captions achieve superior performance on DPG and other benchmarks. Notably, our metric enables more effective data selection-training on only 20% of full data surpasses both full-dataset training and length-based selection method, improving alignment and reconstruction ability. These findings highlight the critical role of detail-aware metrics over length-based heuristics in caption selection for T2I tasks.
Evaluating Attribute Comprehension in Large Vision-Language Models
Aug 25, 2024



Currently, large vision-language models have gained promising progress on many downstream tasks. However, they still suffer many challenges in fine-grained visual understanding tasks, such as object attribute comprehension. Besides, there have been growing efforts on the evaluations of large vision-language models, but lack of in-depth study of attribute comprehension and the visual language fine-tuning process. In this paper, we propose to evaluate the attribute comprehension ability of large vision-language models from two perspectives: attribute recognition and attribute hierarchy understanding. We evaluate three vision-language interactions, including visual question answering, image-text matching, and image-text cosine similarity. Furthermore, we explore the factors affecting attribute comprehension during fine-tuning. Through a series of quantitative and qualitative experiments, we introduce three main findings: (1) Large vision-language models possess good attribute recognition ability, but their hierarchical understanding ability is relatively limited. (2) Compared to ITC, ITM exhibits superior capability in capturing finer details, making it more suitable for attribute understanding tasks. (3) The attribute information in the captions used for fine-tuning plays a crucial role in attribute understanding. We hope this work can help guide future progress in fine-grained visual understanding of large vision-language models.
BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
Jun 25, 2023



The rapid developments of mobile robotics and autonomous navigation over the years are largely empowered by public datasets for testing and upgrading, such as SLAM and localization tasks. Impressive demos and benchmark results have arisen, indicating the establishment of a mature technical framework. However, from the view point of real-world deployments, there are still critical defects of robustness in challenging environments, especially in large-scale, GNSS-denied, textural-monotonous, and unstructured scenarios. To meet the pressing validation demands in such scope, we build a novel challenging robot navigation dataset in a large botanic garden of more than 48000m2. Comprehensive sensors are employed, including high-res/rate stereo Gray&RGB cameras, rotational and forward 3D LiDARs, and low-cost and industrial-grade IMUs, all of which are well calibrated and accurately hardware-synchronized. An all-terrain wheeled robot is configured to mount the sensor suite and provide odometry data. A total of 32 long and short sequences of 2.3 million images are collected, covering scenes of thick woods, riversides, narrow paths, bridges, and grasslands that rarely appeared in previous resources. Excitedly, both highly-accurate ego-motions and 3D map ground truth are provided, along with fine-annotated vision semantics. Our goal is to contribute a high-quality dataset to advance robot navigation and sensor fusion research to a higher level.
Datasets and Evaluation for Simultaneous Localization and Mapping Related Problems: A Comprehensive Survey
Feb 08, 2021
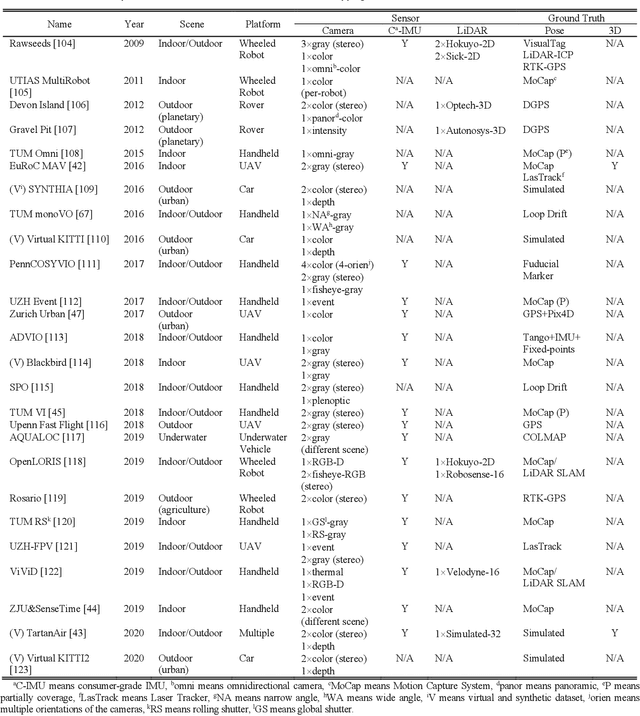
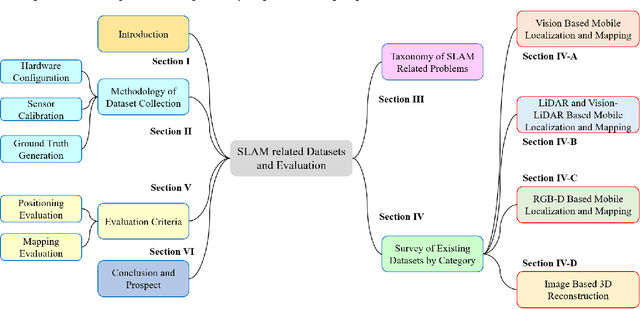
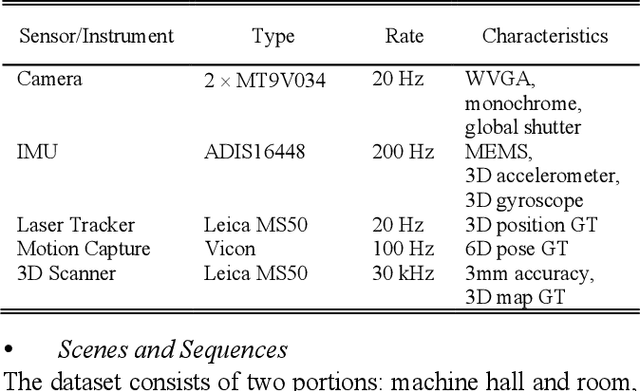
Simultaneous Localization and Mapping (SLAM) has found an increasing utilization lately, such as self-driving cars, robot navigation, 3D mapping, virtual reality (VR) and augmented reality (AR), etc., empowering both industry and daily life. Although the state-of-the-art algorithms where developers have spared no effort are source of intelligence, it is the datasets that dedicate behind and raise us higher. The employment of datasets is essentially a kind of simulation but profits many aspects - capacity of drilling algorithm hourly, exemption of costly hardware and ground truth system, and equitable benchmark for evaluation. However, as a branch of great significance, still the datasets have not drawn wide attention nor been reviewed thoroughly. Hence in this article, we strive to give a comprehensive and open access review of SLAM related datasets and evaluation, which are scarcely surveyed while highly demanded by researchers and engineers, looking forward to serving as not only a dictionary but also a development proposal. The paper starts with the methodology of dataset collection, and a taxonomy of SLAM related tasks. Then followed with the main portion - comprehensively survey the existing SLAM related datasets by category with our considerate introductions and insights. Furthermore, we talk about the evaluation criteria, which are necessary to quantify the algorithm performance on the dataset and inspect the defects. At the end, we summarize the weakness of datasets and evaluation - which could well result in the weakness of topical algorithms - to promote bridging the gap fundamentally.