 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
Apr 01, 2026Traditional scientific discovery relies on an iterative hypothesise-experiment-refine cycle that has driven progress for centuries, but its intuitive, ad-hoc implementation often wastes resources, yields inefficient designs, and misses critical insights. This tutorial presents Bayesian Optimisation (BO), a principled probability-driven framework that formalises and automates this core scientific cycle. BO uses surrogate models (e.g., Gaussian processes) to model empirical observations as evolving hypotheses, and acquisition functions to guide experiment selection, balancing exploitation of known knowledge and exploration of uncharted domains to eliminate guesswork and manual trial-and-error. We first frame scientific discovery as an optimisation problem, then unpack BO's core components, end-to-end workflows, and real-world efficacy via case studies in catalysis, materials science, organic synthesis, and molecule discovery. We also cover critical technical extensions for scientific applications, including batched experimentation, heteroscedasticity, contextual optimisation, and human-in-the-loop integration. Tailored for a broad audience, this tutorial bridges AI advances in BO with practical natural science applications, offering tiered content to empower cross-disciplinary researchers to design more efficient experiments and accelerate principled scientific discovery.
The $\mathbf{Y}$-Combinator for LLMs: Solving Long-Context Rot with $λ$-Calculus
Mar 20, 2026LLMs are increasingly used as general-purpose reasoners, but long inputs remain bottlenecked by a fixed context window. Recursive Language Models (RLMs) address this by externalising the prompt and recursively solving subproblems. Yet existing RLMs depend on an open-ended read-eval-print loop (REPL) in which the model generates arbitrary control code, making execution difficult to verify, predict, and analyse. We introduce $λ$-RLM, a framework for long-context reasoning that replaces free-form recursive code generation with a typed functional runtime grounded in $λ$-calculus. It executes a compact library of pre-verified combinators and uses neural inference only on bounded leaf subproblems, turning recursive reasoning into a structured functional program with explicit control flow. We show that $λ$-RLM admits formal guarantees absent from standard RLMs, including termination, closed-form cost bounds, controlled accuracy scaling with recursion depth, and an optimal partition rule under a simple cost model. Empirically, across four long-context reasoning tasks and nine base models, $λ$-RLM outperforms standard RLM in 29 of 36 model-task comparisons, improves average accuracy by up to +21.9 points across model tiers, and reduces latency by up to 4.1x. These results show that typed symbolic control yields a more reliable and efficient foundation for long-context reasoning than open-ended recursive code generation. The complete implementation of $λ$-RLM, is open-sourced for the community at: https://github.com/lambda-calculus-LLM/lambda-RLM.
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening
Jan 29, 2026Reinforcement learning (RL) post-training is a dominant approach for improving the reasoning performance of large language models (LLMs), yet growing evidence suggests that its gains arise primarily from distribution sharpening rather than the acquisition of new capabilities. Recent work has shown that sampling from the power distribution of LLMs using Markov chain Monte Carlo (MCMC) can recover performance comparable to RL post-training without relying on external rewards; however, the high computational cost of MCMC makes such approaches impractical for widespread adoption. In this work, we propose a theoretically grounded alternative that eliminates the need for iterative MCMC. We derive a novel formulation showing that the global power distribution can be approximated by a token-level scaled low-temperature one, where the scaling factor captures future trajectory quality. Leveraging this insight, we introduce a training-free and verifier-free algorithm that sharpens the base model's generative distribution autoregressively. Empirically, we evaluate our method on math, QA, and code tasks across four LLMs, and show that our method matches or surpasses one-shot GRPO without relying on any external rewards, while reducing inference latency by over 10x compared to MCMC-based sampling.
Bourbaki: Self-Generated and Goal-Conditioned MDPs for Theorem Proving
Jul 03, 2025Reasoning remains a challenging task for large language models (LLMs), especially within the logically constrained environment of automated theorem proving (ATP), due to sparse rewards and the vast scale of proofs. These challenges are amplified in benchmarks like PutnamBench, which contains university-level problems requiring complex, multi-step reasoning. To address this, we introduce self-generated goal-conditioned MDPs (sG-MDPs), a new framework in which agents generate and pursue their subgoals based on the evolving proof state. Given this more structured generation of goals, the resulting problem becomes more amenable to search. We then apply Monte Carlo Tree Search (MCTS)-like algorithms to solve the sG-MDP, instantiating our approach in Bourbaki (7B), a modular system that can ensemble multiple 7B LLMs for subgoal generation and tactic synthesis. On PutnamBench, Bourbaki (7B) solves 26 problems, achieving new state-of-the-art results with models at this scale.
Why Can Large Language Models Generate Correct Chain-of-Thoughts?
Oct 30, 2023This paper delves into the capabilities of large language models (LLMs), specifically focusing on advancing the theoretical comprehension of chain-of-thought prompting. We investigate how LLMs can be effectively induced to generate a coherent chain of thoughts. To achieve this, we introduce a two-level hierarchical graphical model tailored for natural language generation. Within this framework, we establish a compelling geometrical convergence rate that gauges the likelihood of an LLM-generated chain of thoughts compared to those originating from the true language. Our findings provide a theoretical justification for the ability of LLMs to produce the correct sequence of thoughts (potentially) explaining performance gains in tasks demanding reasoning skills.
Sample-Efficient Optimisation with Probabilistic Transformer Surrogates
May 30, 2022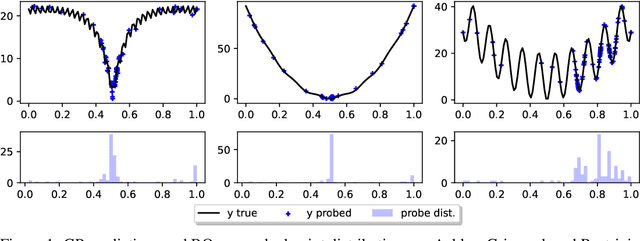
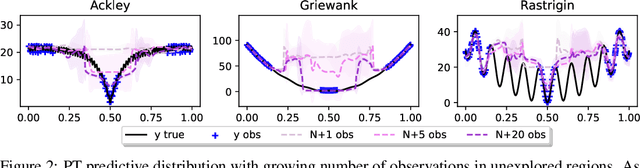
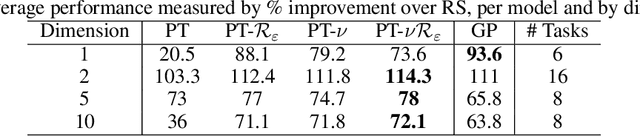
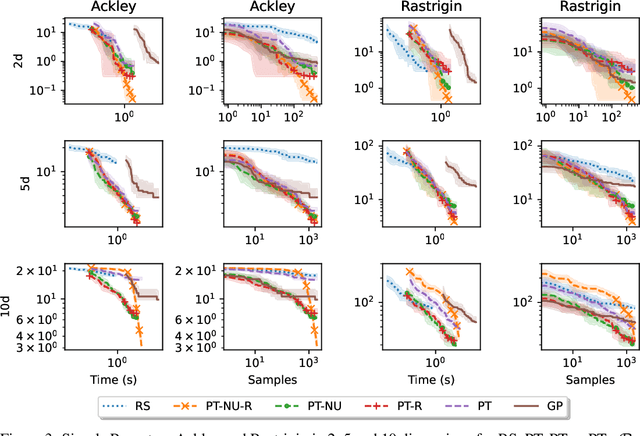
Faced with problems of increasing complexity, recent research in Bayesian Optimisation (BO) has focused on adapting deep probabilistic models as flexible alternatives to Gaussian Processes (GPs). In a similar vein, this paper investigates the feasibility of employing state-of-the-art probabilistic transformers in BO. Upon further investigation, we observe two drawbacks stemming from their training procedure and loss definition, hindering their direct deployment as proxies in black-box optimisation. First, we notice that these models are trained on uniformly distributed inputs, which impairs predictive accuracy on non-uniform data - a setting arising from any typical BO loop due to exploration-exploitation trade-offs. Second, we realise that training losses (e.g., cross-entropy) only asymptotically guarantee accurate posterior approximations, i.e., after arriving at the global optimum, which generally cannot be ensured. At the stationary points of the loss function, however, we observe a degradation in predictive performance especially in exploratory regions of the input space. To tackle these shortcomings we introduce two components: 1) a BO-tailored training prior supporting non-uniformly distributed points, and 2) a novel approximate posterior regulariser trading-off accuracy and input sensitivity to filter favourable stationary points for improved predictive performance. In a large panel of experiments, we demonstrate, for the first time, that one transformer pre-trained on data sampled from random GP priors produces competitive results on 16 benchmark black-boxes compared to GP-based BO. Since our model is only pre-trained once and used in all tasks without any retraining and/or fine-tuning, we report an order of magnitude time-reduction, while matching and sometimes outperforming GPs.
AntBO: Towards Real-World Automated Antibody Design with Combinatorial Bayesian Optimisation
Feb 16, 2022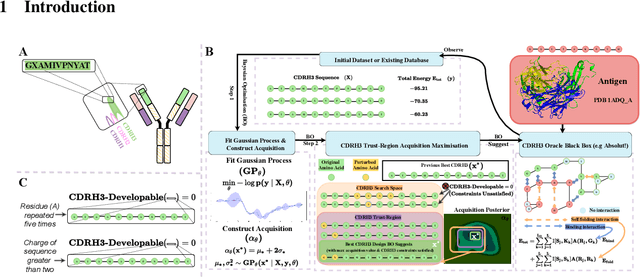
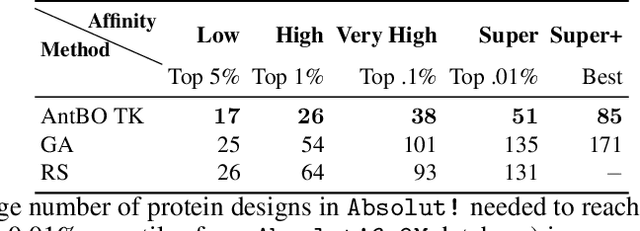
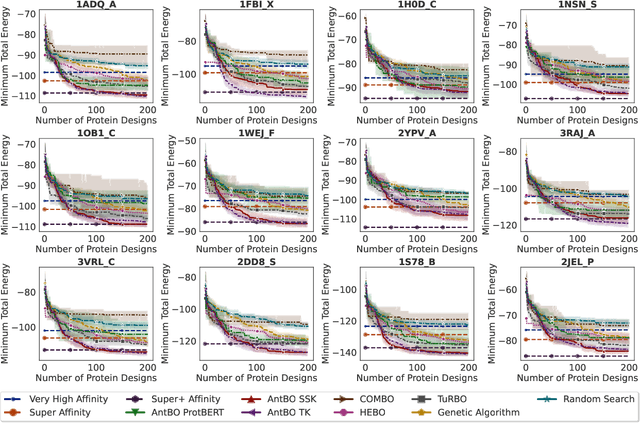
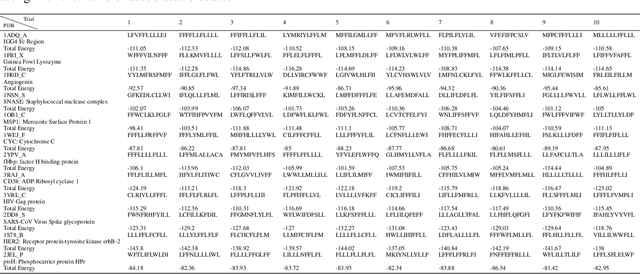
Antibodies are canonically Y-shaped multimeric proteins capable of highly specific molecular recognition. The CDRH3 region located at the tip of variable chains of an antibody dominates antigen-binding specificity. Therefore, it is a priority to design optimal antigen-specific CDRH3 regions to develop therapeutic antibodies to combat harmful pathogens. However, the combinatorial nature of CDRH3 sequence space makes it impossible to search for an optimal binding sequence exhaustively and efficiently, especially not experimentally. Here, we present AntBO: a Combinatorial Bayesian Optimisation framework enabling efficient in silico design of the CDRH3 region. Ideally, antibodies should bind to their target antigen and be free from any harmful outcomes. Therefore, we introduce the CDRH3 trust region that restricts the search to sequences with feasible developability scores. To benchmark AntBO, we use the Absolut! software suite as a black-box oracle because it can score the target specificity and affinity of designed antibodies in silico in an unconstrained fashion. The results across 188 antigens demonstrate the benefit of AntBO in designing CDRH3 regions with diverse biophysical properties. In under 200 protein designs, AntBO can suggest antibody sequences that outperform the best binding sequence drawn from 6.9 million experimentally obtained CDRH3s and a commonly used genetic algorithm baseline. Additionally, AntBO finds very-high affinity CDRH3 sequences in only 38 protein designs whilst requiring no domain knowledge. We conclude AntBO brings automated antibody design methods closer to what is practically viable for in vitro experimentation.
Self-consistent Gradient-like Eigen Decomposition in Solving Schrödinger Equations
Feb 03, 2022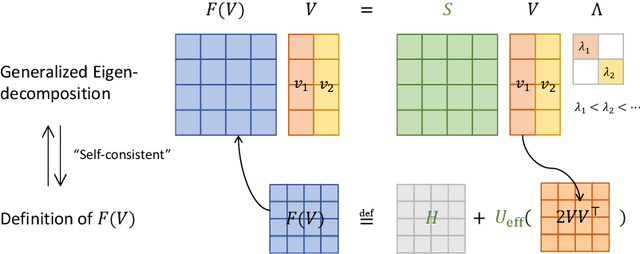

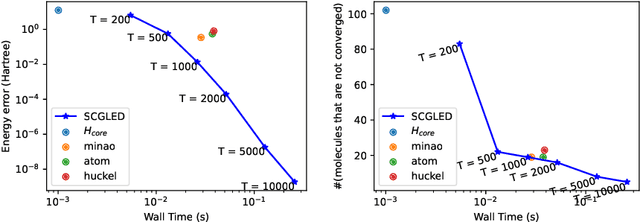
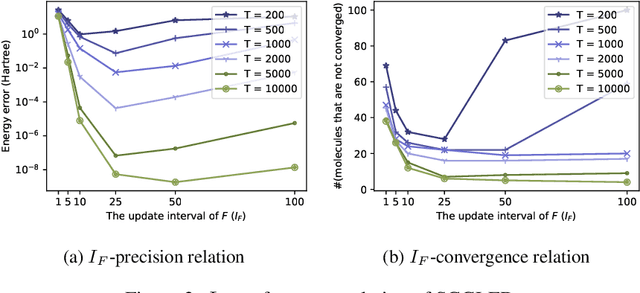
The Schr\"odinger equation is at the heart of modern quantum mechanics. Since exact solutions of the ground state are typically intractable, standard approaches approximate Schr\"odinger equation as forms of nonlinear generalized eigenvalue problems $F(V)V = SV\Lambda$ in which $F(V)$, the matrix to be decomposed, is a function of its own top-$k$ smallest eigenvectors $V$, leading to a "self-consistency problem". Traditional iterative methods heavily rely on high-quality initial guesses of $V$ generated via domain-specific heuristics methods based on quantum mechanics. In this work, we eliminate such a need for domain-specific heuristics by presenting a novel framework, Self-consistent Gradient-like Eigen Decomposition (SCGLED) that regards $F(V)$ as a special "online data generator", thus allows gradient-like eigendecomposition methods in streaming $k$-PCA to approach the self-consistency of the equation from scratch in an iterative way similar to online learning. With several critical numerical improvements, SCGLED is robust to initial guesses, free of quantum-mechanism-based heuristics designs, and neat in implementation. Our experiments show that it not only can simply replace traditional heuristics-based initial guess methods with large performance advantage (achieved averagely 25x more precise than the best baseline in similar wall time), but also is capable of finding highly precise solutions independently without any traditional iterative methods.
BOiLS: Bayesian Optimisation for Logic Synthesis
Nov 11, 2021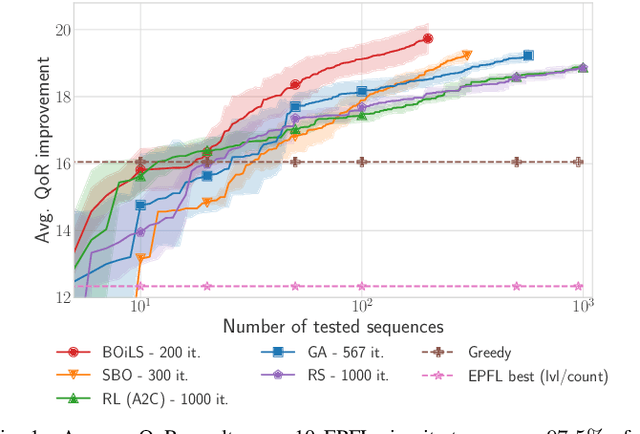
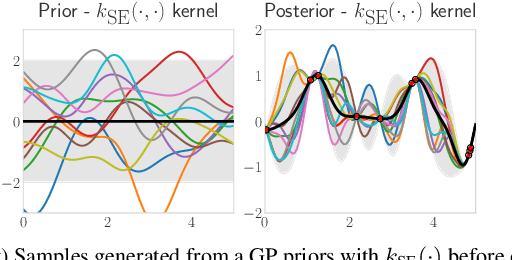
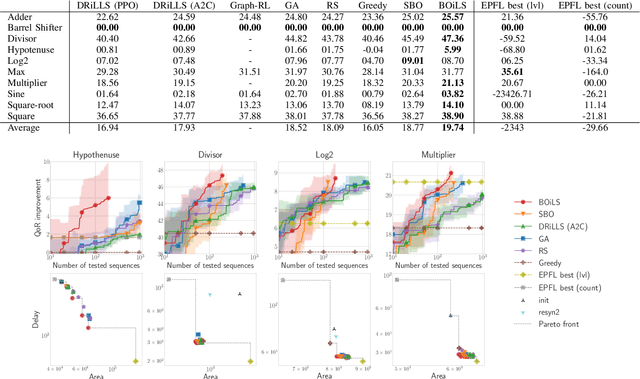
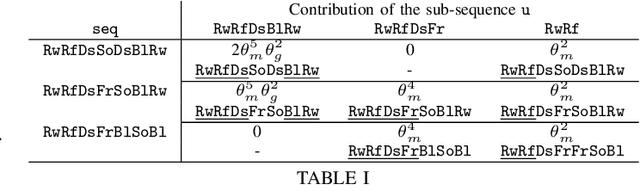
Optimising the quality-of-results (QoR) of circuits during logic synthesis is a formidable challenge necessitating the exploration of exponentially sized search spaces. While expert-designed operations aid in uncovering effective sequences, the increase in complexity of logic circuits favours automated procedures. Inspired by the successes of machine learning, researchers adapted deep learning and reinforcement learning to logic synthesis applications. However successful, those techniques suffer from high sample complexities preventing widespread adoption. To enable efficient and scalable solutions, we propose BOiLS, the first algorithm adapting modern Bayesian optimisation to navigate the space of synthesis operations. BOiLS requires no human intervention and effectively trades-off exploration versus exploitation through novel Gaussian process kernels and trust-region constrained acquisitions. In a set of experiments on EPFL benchmarks, we demonstrate BOiLS's superior performance compared to state-of-the-art in terms of both sample efficiency and QoR values.
High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric Learning
Jun 16, 2021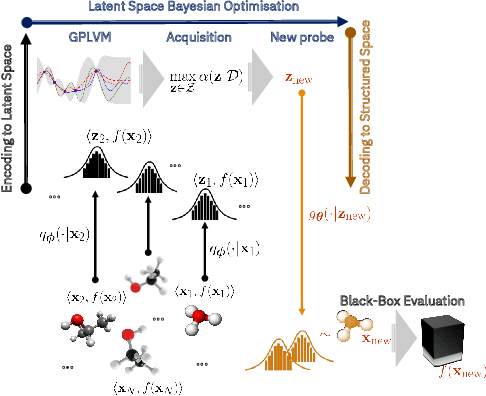

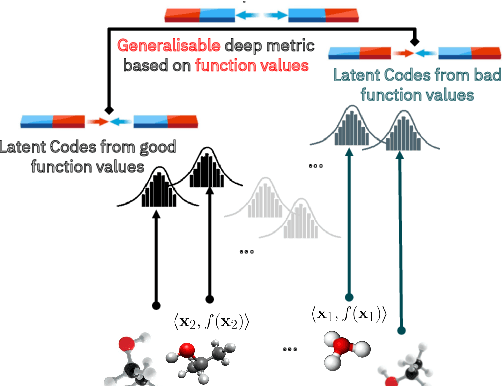

We introduce a method based on deep metric learning to perform Bayesian optimisation over high-dimensional, structured input spaces using variational autoencoders (VAEs). By extending ideas from supervised deep metric learning, we address a longstanding problem in high-dimensional VAE Bayesian optimisation, namely how to enforce a discriminative latent space as an inductive bias. Importantly, we achieve such an inductive bias using just 1% of the available labelled data relative to previous work, highlighting the sample efficiency of our approach. As a theoretical contribution, we present a proof of vanishing regret for our method. As an empirical contribution, we present state-of-the-art results on real-world high-dimensional black-box optimisation problems including property-guided molecule generation. It is the hope that the results presented in this paper can act as a guiding principle for realising effective high-dimensional Bayesian optimisation.