 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSGBench: A Diverse Strategic Game Benchmark for Evaluating LLM-based Agents in Complex Decision-Making Environments
Mar 08, 2025



Large Language Model~(LLM) based agents have been increasingly popular in solving complex and dynamic tasks, which requires proper evaluation systems to assess their capabilities. Nevertheless, existing benchmarks usually either focus on single-objective tasks or use overly broad assessing metrics, failing to provide a comprehensive inspection of the actual capabilities of LLM-based agents in complicated decision-making tasks. To address these issues, we introduce DSGBench, a more rigorous evaluation platform for strategic decision-making. Firstly, it incorporates six complex strategic games which serve as ideal testbeds due to their long-term and multi-dimensional decision-making demands and flexibility in customizing tasks of various difficulty levels or multiple targets. Secondly, DSGBench employs a fine-grained evaluation scoring system which examines the decision-making capabilities by looking into the performance in five specific dimensions and offering a comprehensive assessment in a well-designed way. Furthermore, DSGBench also incorporates an automated decision-tracking mechanism which enables in-depth analysis of agent behaviour patterns and the changes in their strategies. We demonstrate the advances of DSGBench by applying it to multiple popular LLM-based agents and our results suggest that DSGBench provides valuable insights in choosing LLM-based agents as well as improving their future development. DSGBench is available at https://github.com/DeciBrain-Group/DSGBench.
PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning
Feb 23, 2025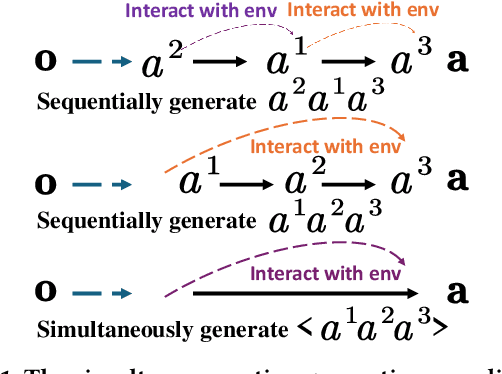
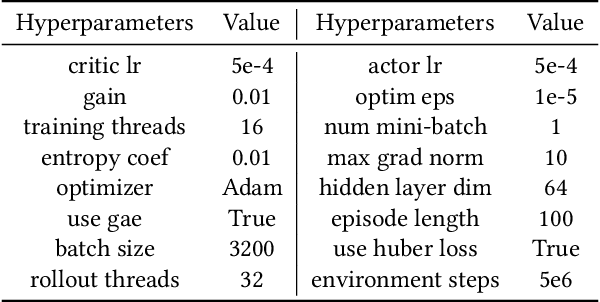
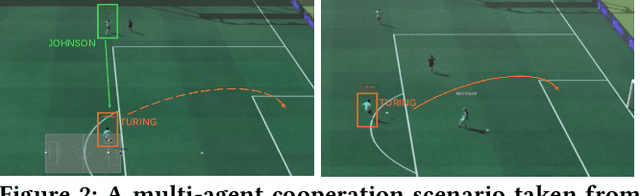
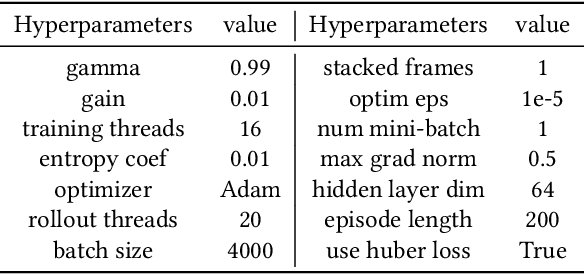
Multi-agent reinforcement learning (MARL) faces challenges in coordinating agents due to complex interdependencies within multi-agent systems. Most MARL algorithms use the simultaneous decision-making paradigm but ignore the action-level dependencies among agents, which reduces coordination efficiency. In contrast, the sequential decision-making paradigm provides finer-grained supervision for agent decision order, presenting the potential for handling dependencies via better decision order management. However, determining the optimal decision order remains a challenge. In this paper, we introduce Action Generation with Plackett-Luce Sampling (AGPS), a novel mechanism for agent decision order optimization. We model the order determination task as a Plackett-Luce sampling process to address issues such as ranking instability and vanishing gradient during the network training process. AGPS realizes credit-based decision order determination by establishing a bridge between the significance of agents' local observations and their decision credits, thus facilitating order optimization and dependency management. Integrating AGPS with the Multi-Agent Transformer, we propose the Prioritized Multi-Agent Transformer (PMAT), a sequential decision-making MARL algorithm with decision order optimization. Experiments on benchmarks including StarCraft II Multi-Agent Challenge, Google Research Football, and Multi-Agent MuJoCo show that PMAT outperforms state-of-the-art algorithms, greatly enhancing coordination efficiency.
A Game-Theoretic Approach to Multi-Agent Trust Region Optimization
Jun 12, 2021


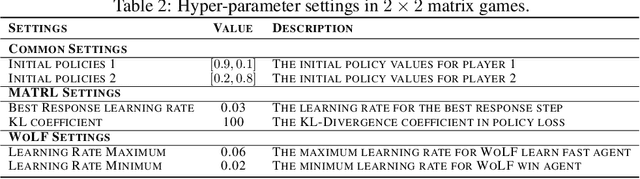
Trust region methods are widely applied in single-agent reinforcement learning problems due to their monotonic performance-improvement guarantee at every iteration. Nonetheless, when applied in multi-agent settings, the guarantee of trust region methods no longer holds because an agent's payoff is also affected by other agents' adaptive behaviors. To tackle this problem, we conduct a game-theoretical analysis in the policy space, and propose a multi-agent trust region learning method (MATRL), which enables trust region optimization for multi-agent learning. Specifically, MATRL finds a stable improvement direction that is guided by the solution concept of Nash equilibrium at the meta-game level. We derive the monotonic improvement guarantee in multi-agent settings and empirically show the local convergence of MATRL to stable fixed points in the two-player rotational differential game. To test our method, we evaluate MATRL in both discrete and continuous multiplayer general-sum games including checker and switch grid worlds, multi-agent MuJoCo, and Atari games. Results suggest that MATRL significantly outperforms strong multi-agent reinforcement learning baselines.
Causal World Models by Unsupervised Deconfounding of Physical Dynamics
Dec 28, 2020
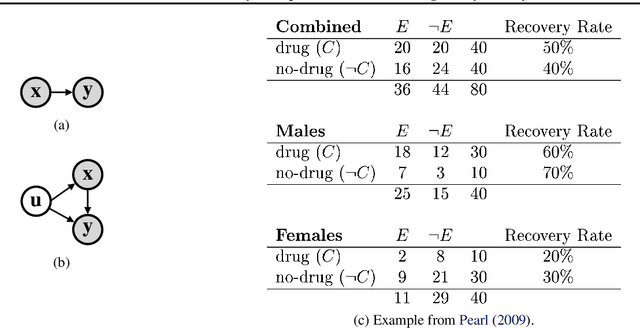
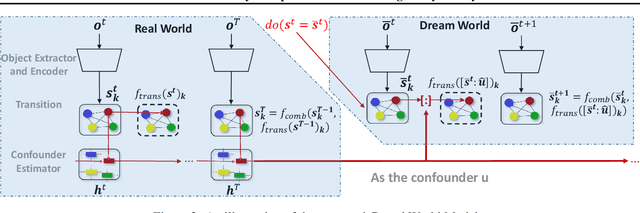
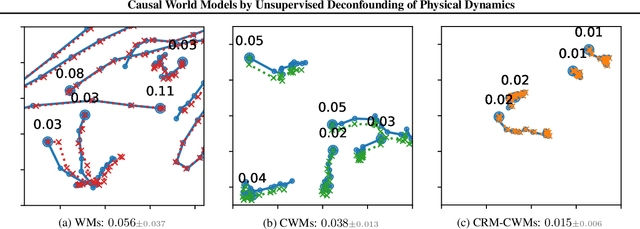
The capability of imagining internally with a mental model of the world is vitally important for human cognition. If a machine intelligent agent can learn a world model to create a "dream" environment, it can then internally ask what-if questions -- simulate the alternative futures that haven't been experienced in the past yet -- and make optimal decisions accordingly. Existing world models are established typically by learning spatio-temporal regularities embedded from the past sensory signal without taking into account confounding factors that influence state transition dynamics. As such, they fail to answer the critical counterfactual questions about "what would have happened" if a certain action policy was taken. In this paper, we propose Causal World Models (CWMs) that allow unsupervised modeling of relationships between the intervened observations and the alternative futures by learning an estimator of the latent confounding factors. We empirically evaluate our method and demonstrate its effectiveness in a variety of physical reasoning environments. Specifically, we show reductions in sample complexity for reinforcement learning tasks and improvements in counterfactual physical reasoning.
Compositional ADAM: An Adaptive Compositional Solver
Feb 10, 2020

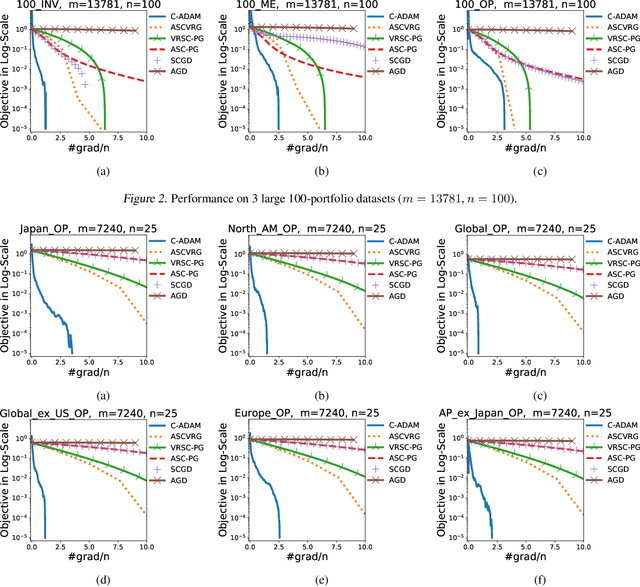
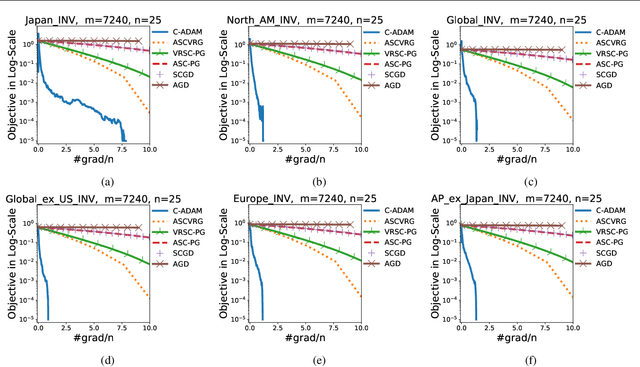
In this paper, we present C-ADAM, the first adaptive solver for compositional problems involving a non-linear functional nesting of expected values. We proof that C-ADAM converges to a stationary point in $\mathcal{O}(\delta^{-2.25})$ with $\delta$ being a precision parameter. Moreover, we demonstrate the importance of our results by bridging, for the first time, model-agnostic meta-learning (MAML) and compositional optimisation showing fastest known rates for deep network adaptation to-date. Finally, we validate our findings in a set of experiments from portfolio optimisation and meta-learning. Our results manifest significant sample complexity reductions compared to both standard and compositional solvers.
Multi-View Reinforcement Learning
Oct 18, 2019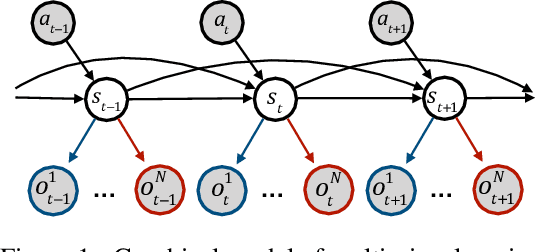

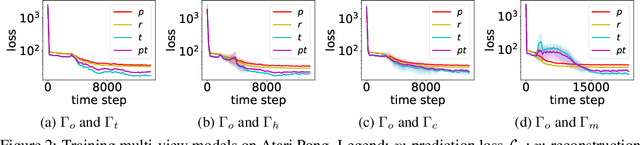
This paper is concerned with multi-view reinforcement learning (MVRL), which allows for decision making when agents share common dynamics but adhere to different observation models. We define the MVRL framework by extending partially observable Markov decision processes (POMDPs) to support more than one observation model and propose two solution methods through observation augmentation and cross-view policy transfer. We empirically evaluate our method and demonstrate its effectiveness in a variety of environments. Specifically, we show reductions in sample complexities and computational time for acquiring policies that handle multi-view environments.
Optimizing Object-based Perception and Control by Free-Energy Principle
Mar 04, 2019
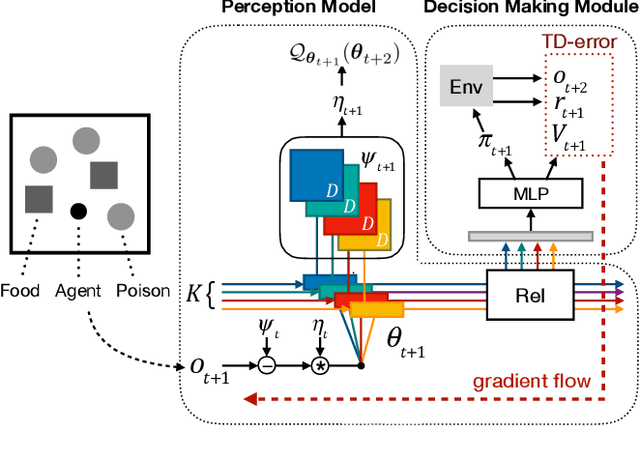


One of the well-known formulations of human perception is a hierarchical inference model based on the interaction between conceptual knowledge and sensory stimuli from the partially observable environment. This model helps human to learn inductive biases and guides their behaviors by minimizing their surprise of observations. However, most model-based reinforcement learning still lacks the support of object-based physical reasoning. In this paper, we propose Object-based Perception Control (OPC). It combines the learning of perceiving objects from the scene and that of control of the objects in the perceived environments by the free-energy principle. Extensive experiments on high-dimensional pixel environments show that OPC outperforms several strong baselines in accumulated rewards and the quality of perceptual grouping.
Learning Shared Dynamics with Meta-World Models
Nov 05, 2018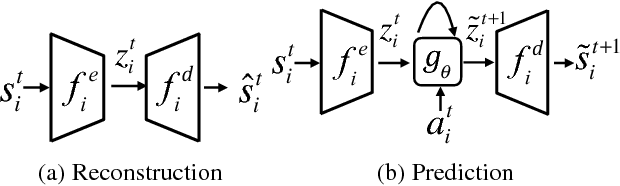



Humans have consciousness as the ability to perceive events and objects: a mental model of the world developed from the most impoverished of visual stimuli, enabling humans to make rapid decisions and take actions. Although spatial and temporal aspects of different scenes are generally diverse, the underlying physics among environments still work the same way, thus learning an abstract description of shared physical dynamics helps human to understand the world. In this paper, we explore building this mental world with neural network models through multi-task learning, namely the meta-world model. We show through extensive experiments that our proposed meta-world models successfully capture the common dynamics over the compact representations of visually different environments from Atari Games. We also demonstrate that agents equipped with our meta-world model possess the ability of visual self-recognition, i.e., recognize themselves from the reflected mirrored environment derived from the classic mirror self-recognition test (MSR).
Mean Field Multi-Agent Reinforcement Learning
Jul 19, 2018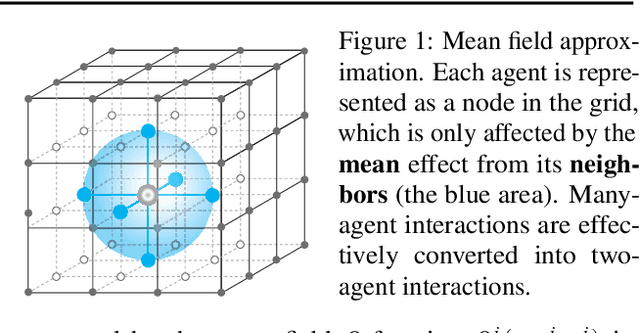
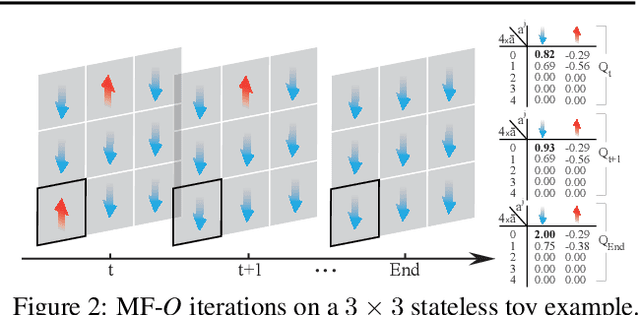


Existing multi-agent reinforcement learning methods are limited typically to a small number of agents. When the agent number increases largely, the learning becomes intractable due to the curse of the dimensionality and the exponential growth of agent interactions. In this paper, we present Mean Field Reinforcement Learning where the interactions within the population of agents are approximated by those between a single agent and the average effect from the overall population or neighboring agents; the interplay between the two entities is mutually reinforced: the learning of the individual agent's optimal policy depends on the dynamics of the population, while the dynamics of the population change according to the collective patterns of the individual policies. We develop practical mean field Q-learning and mean field Actor-Critic algorithms and analyze the convergence of the solution to Nash equilibrium. Experiments on Gaussian squeeze, Ising model, and battle games justify the learning effectiveness of our mean field approaches. In addition, we report the first result to solve the Ising model via model-free reinforcement learning methods.
S-OHEM: Stratified Online Hard Example Mining for Object Detection
Aug 15, 2017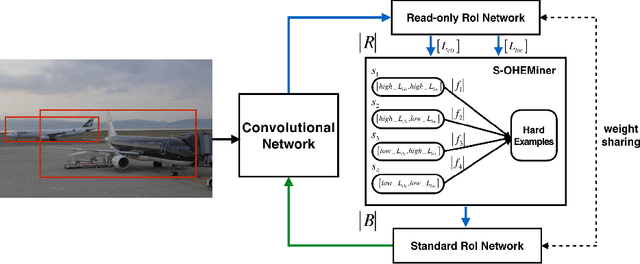

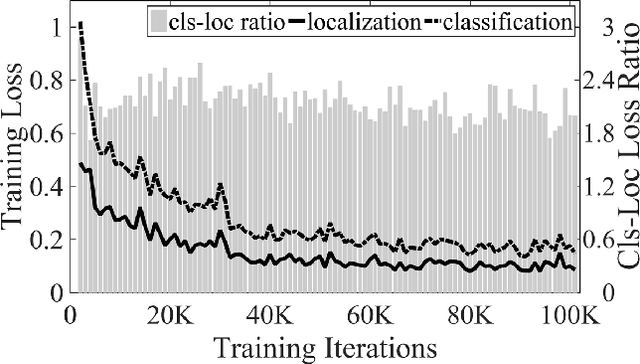
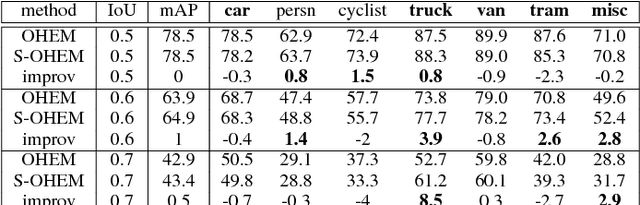
One of the major challenges in object detection is to propose detectors with highly accurate localization of objects. The online sampling of high-loss region proposals (hard examples) uses the multitask loss with equal weight settings across all loss types (e.g, classification and localization, rigid and non-rigid categories) and ignores the influence of different loss distributions throughout the training process, which we find essential to the training efficacy. In this paper, we present the Stratified Online Hard Example Mining (S-OHEM) algorithm for training higher efficiency and accuracy detectors. S-OHEM exploits OHEM with stratified sampling, a widely-adopted sampling technique, to choose the training examples according to this influence during hard example mining, and thus enhance the performance of object detectors. We show through systematic experiments that S-OHEM yields an average precision (AP) improvement of 0.5% on rigid categories of PASCAL VOC 2007 for both the IoU threshold of 0.6 and 0.7. For KITTI 2012, both results of the same metric are 1.6%. Regarding the mean average precision (mAP), a relative increase of 0.3% and 0.5% (1% and 0.5%) is observed for VOC07 (KITTI12) using the same set of IoU threshold. Also, S-OHEM is easy to integrate with existing region-based detectors and is capable of acting with post-recognition level regressors.