 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSGBench: A Diverse Strategic Game Benchmark for Evaluating LLM-based Agents in Complex Decision-Making Environments
Mar 08, 2025



Large Language Model~(LLM) based agents have been increasingly popular in solving complex and dynamic tasks, which requires proper evaluation systems to assess their capabilities. Nevertheless, existing benchmarks usually either focus on single-objective tasks or use overly broad assessing metrics, failing to provide a comprehensive inspection of the actual capabilities of LLM-based agents in complicated decision-making tasks. To address these issues, we introduce DSGBench, a more rigorous evaluation platform for strategic decision-making. Firstly, it incorporates six complex strategic games which serve as ideal testbeds due to their long-term and multi-dimensional decision-making demands and flexibility in customizing tasks of various difficulty levels or multiple targets. Secondly, DSGBench employs a fine-grained evaluation scoring system which examines the decision-making capabilities by looking into the performance in five specific dimensions and offering a comprehensive assessment in a well-designed way. Furthermore, DSGBench also incorporates an automated decision-tracking mechanism which enables in-depth analysis of agent behaviour patterns and the changes in their strategies. We demonstrate the advances of DSGBench by applying it to multiple popular LLM-based agents and our results suggest that DSGBench provides valuable insights in choosing LLM-based agents as well as improving their future development. DSGBench is available at https://github.com/DeciBrain-Group/DSGBench.
Communication Optimization Strategies for Distributed Deep Learning: A Survey
Mar 06, 2020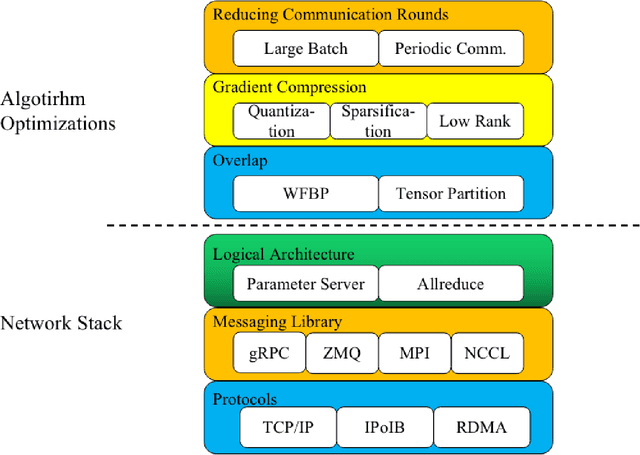

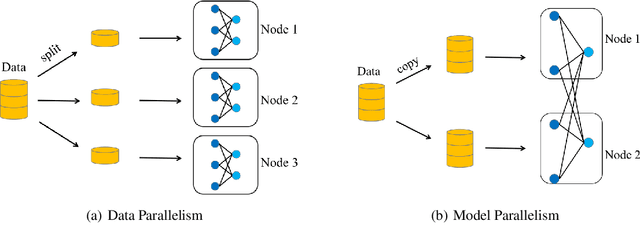

Recent trends in high-performance computing and deep learning lead to a proliferation of studies on large-scale deep neural network (DNN) training. However, the frequent communication requirements among computation nodes drastically slow down the overall training speed, which makes the bottleneck in distributed training, particularly in clusters with limited network bandwidth. To mitigate the drawbacks of distributed communication, researchers have proposed various optimization strategies. In this paper, we give a comprehensive survey of communication strategies from both algorithm and computer network perspectives. Algorithm optimizations focus on reducing the amount of communication in distributed training, while network optimizations focus on speeding up the communication between distributed devices. At the algorithm level, we describe how to reduce the number of communication rounds and transmitted bits per round, besides we shed light on how to overlap computation and communication. At the network level, we discuss the effect caused by network infrastructures, including communication schemes, network protocols, and topology. Finally, we extrapolate potential challenges and research directions for communication acceleration in distributed DNN training.