 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD-SGD: Distributed Stochastic Gradient Descent with Compression and Delay Compensation
Jun 21, 2021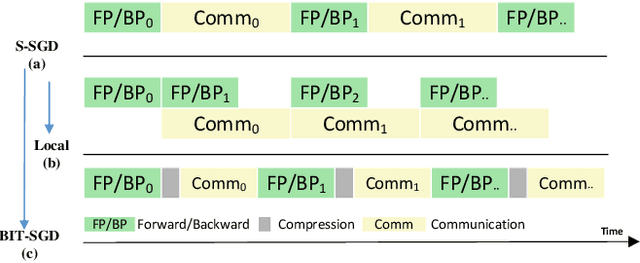



Communication overhead is the key challenge for distributed training. Gradient compression is a widely used approach to reduce communication traffic. When combining with parallel communication mechanism method like pipeline, gradient compression technique can greatly alleviate the impact of communication overhead. However, there exists two problems of gradient compression technique to be solved. Firstly, gradient compression brings in extra computation cost, which will delay the next training iteration. Secondly, gradient compression usually leads to the decrease of convergence accuracy.
Communication Optimization Strategies for Distributed Deep Learning: A Survey
Mar 06, 2020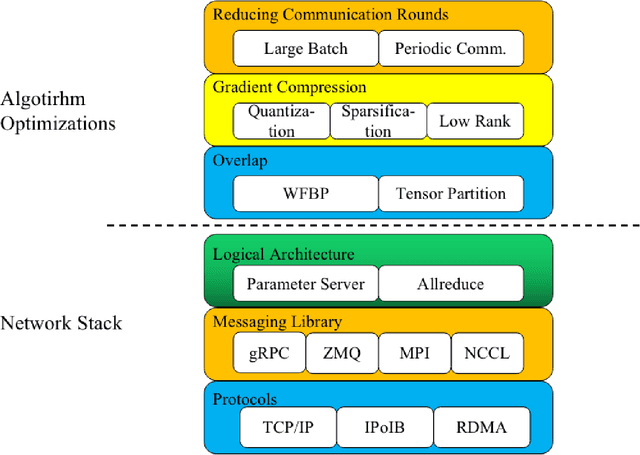

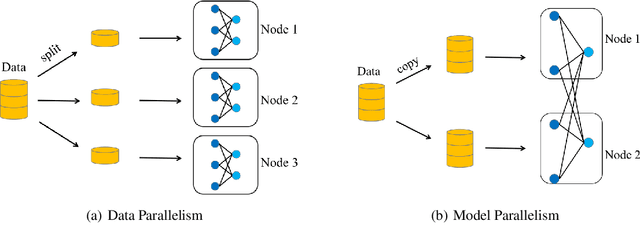

Recent trends in high-performance computing and deep learning lead to a proliferation of studies on large-scale deep neural network (DNN) training. However, the frequent communication requirements among computation nodes drastically slow down the overall training speed, which makes the bottleneck in distributed training, particularly in clusters with limited network bandwidth. To mitigate the drawbacks of distributed communication, researchers have proposed various optimization strategies. In this paper, we give a comprehensive survey of communication strategies from both algorithm and computer network perspectives. Algorithm optimizations focus on reducing the amount of communication in distributed training, while network optimizations focus on speeding up the communication between distributed devices. At the algorithm level, we describe how to reduce the number of communication rounds and transmitted bits per round, besides we shed light on how to overlap computation and communication. At the network level, we discuss the effect caused by network infrastructures, including communication schemes, network protocols, and topology. Finally, we extrapolate potential challenges and research directions for communication acceleration in distributed DNN training.