 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniISR: A Unified Framework for Centralized and Federated Learning via Intermediate Supervision and Regularization
May 19, 2026The global deployment of edge intelligence operates across heterogeneous legal frameworks. While some regions permit centralized learning (CL) via cloud data aggregation, others enforce strict data localization, necessitating federated learning (FL). This operational dichotomy introduces two incompatible optimization regimes (i.e., unbiased global gradients yet coupled with internal covariate shift in CL versus biased, drift-prone local updates in FL), resulting in that any naive integration of the two lacks rigorous theoretical guarantees. To fill this gap, we propose OmniISR, a unified framework that fuses pure CL, pure FL, and hybrid CL-FL training modes via equipping intermediate supervision and regularization (ISR) signals at multiple hidden layers. Specifically, we propose (i) to use mutual-information (MI) as intermediate supervision to align shifting internal covariate in CL and client-drifting representations in FL, and (ii) to adopt negative-entropy (NE) as intermediate regularizer to penalize overconfident prediction, preserve representational uncertainty, and avoid device-specific collapse. On the theory side, we derive (i) a unified, ISR-agnostic, and non-asymptotic O(1/sqrt(T)) convergence bound that shows the introduced ISR does not violate standard SGD convergence, (ii) a federated drift-bound that quantifies the ISR-reduced client drift, (iii) a gradient-alignment guarantee that ensures non-conflicting CL and FL updates under mild bias, and (iv) an explicit escape-time bound that indicates that CL-FL hybrid mixing enlarges effective stochasticity and accelerates escape from strict saddles. Extensive experiments demonstrate that OmniISR consistently improves model performance in both centralized and federated paradigms, reduces the CL-FL gap by 22.60%, and yields 37/48 paired metric wins across multiple FL algorithms.
Goal Exploration via Adaptive Skill Distribution for Goal-Conditioned Reinforcement Learning
Apr 19, 2024
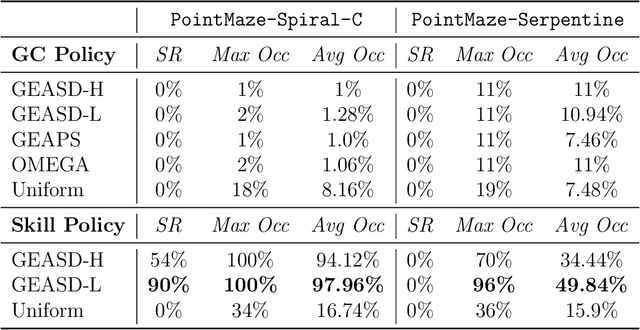
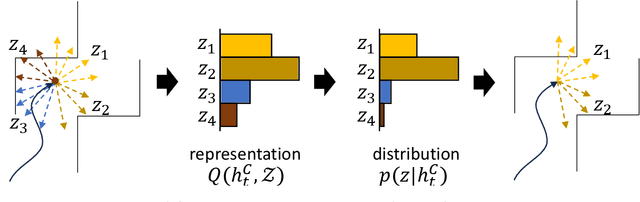
Exploration efficiency poses a significant challenge in goal-conditioned reinforcement learning (GCRL) tasks, particularly those with long horizons and sparse rewards. A primary limitation to exploration efficiency is the agent's inability to leverage environmental structural patterns. In this study, we introduce a novel framework, GEASD, designed to capture these patterns through an adaptive skill distribution during the learning process. This distribution optimizes the local entropy of achieved goals within a contextual horizon, enhancing goal-spreading behaviors and facilitating deep exploration in states containing familiar structural patterns. Our experiments reveal marked improvements in exploration efficiency using the adaptive skill distribution compared to a uniform skill distribution. Additionally, the learned skill distribution demonstrates robust generalization capabilities, achieving substantial exploration progress in unseen tasks containing similar local structures.
Bias Resilient Multi-Step Off-Policy Goal-Conditioned Reinforcement Learning
Nov 29, 2023

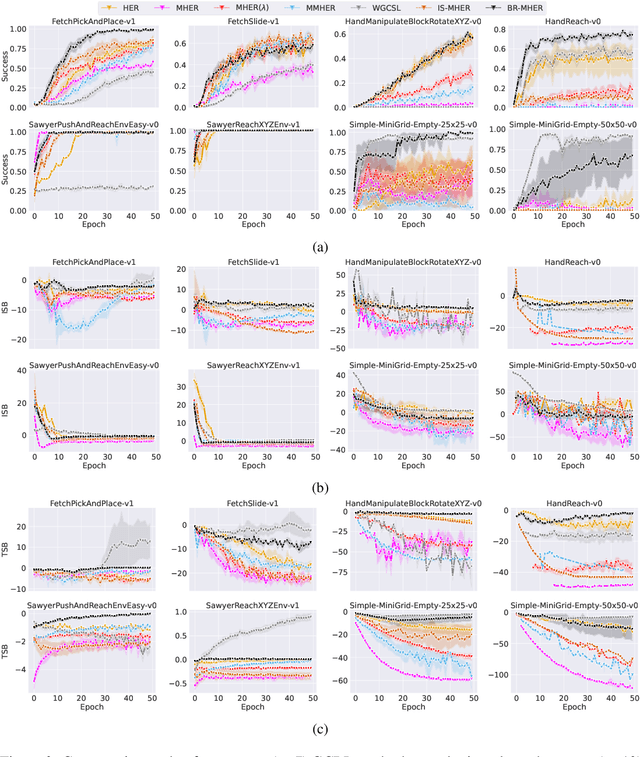

In goal-conditioned reinforcement learning (GCRL), sparse rewards present significant challenges, often obstructing efficient learning. Although multi-step GCRL can boost this efficiency, it can also lead to off-policy biases in target values. This paper dives deep into these biases, categorizing them into two distinct categories: "shooting" and "shifting". Recognizing that certain behavior policies can hasten policy refinement, we present solutions designed to capitalize on the positive aspects of these biases while minimizing their drawbacks, enabling the use of larger step sizes to speed up GCRL. An empirical study demonstrates that our approach ensures a resilient and robust improvement, even in ten-step learning scenarios, leading to superior learning efficiency and performance that generally surpass the baseline and several state-of-the-art multi-step GCRL benchmarks.
Goal Exploration Augmentation via Pre-trained Skills for Sparse-Reward Long-Horizon Goal-Conditioned Reinforcement Learning
Oct 28, 2022


Reinforcement learning (RL) often struggles to accomplish a sparse-reward long-horizon task in a complex environment. Goal-conditioned reinforcement learning (GCRL) has been employed to tackle this difficult problem via a curriculum of easy-to-reach sub-goals. In GCRL, exploring novel sub-goals is essential for the agent to ultimately find the pathway to the desired goal. How to explore novel sub-goals efficiently is one of the most challenging issues in GCRL. Several goal exploration methods have been proposed to address this issue but still struggle to find the desired goals efficiently. In this paper, we propose a novel learning objective by optimizing the entropy of both achieved and new goals to be explored for more efficient goal exploration in sub-goal selection based GCRL. To optimize this objective, we first explore and exploit the frequently occurring goal-transition patterns mined in the environments similar to the current task to compose skills via skill learning. Then, the pretrained skills are applied in goal exploration. Evaluation on a variety of spare-reward long-horizon benchmark tasks suggests that incorporating our method into several state-of-the-art GCRL baselines significantly boosts their exploration efficiency while improving or maintaining their performance. The source code is available at: https://github.com/GEAPS/GEAPS.
Multi-View Reinforcement Learning
Oct 18, 2019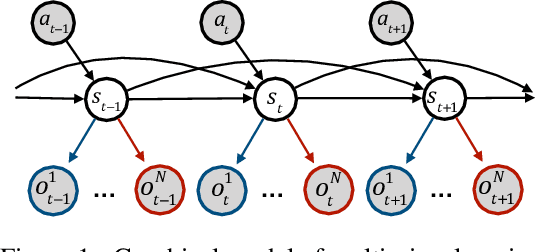

This paper is concerned with multi-view reinforcement learning (MVRL), which allows for decision making when agents share common dynamics but adhere to different observation models. We define the MVRL framework by extending partially observable Markov decision processes (POMDPs) to support more than one observation model and propose two solution methods through observation augmentation and cross-view policy transfer. We empirically evaluate our method and demonstrate its effectiveness in a variety of environments. Specifically, we show reductions in sample complexities and computational time for acquiring policies that handle multi-view environments.
Learning Shared Dynamics with Meta-World Models
Nov 05, 2018



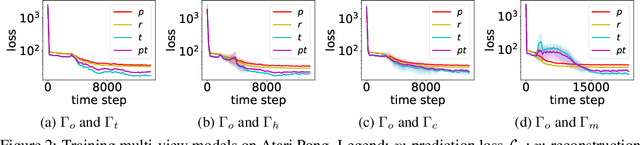
Humans have consciousness as the ability to perceive events and objects: a mental model of the world developed from the most impoverished of visual stimuli, enabling humans to make rapid decisions and take actions. Although spatial and temporal aspects of different scenes are generally diverse, the underlying physics among environments still work the same way, thus learning an abstract description of shared physical dynamics helps human to understand the world. In this paper, we explore building this mental world with neural network models through multi-task learning, namely the meta-world model. We show through extensive experiments that our proposed meta-world models successfully capture the common dynamics over the compact representations of visually different environments from Atari Games. We also demonstrate that agents equipped with our meta-world model possess the ability of visual self-recognition, i.e., recognize themselves from the reflected mirrored environment derived from the classic mirror self-recognition test (MSR).
Learning Multi-agent Implicit Communication Through Actions: A Case Study in Contract Bridge, a Collaborative Imperfect-Information Game
Oct 10, 2018



In situations where explicit communication is limited, a human collaborator is typically able to learn to: (i) infer the meaning behind their partner's actions and (ii) balance between taking actions that are exploitative given their current understanding of the state vs. those that can convey private information about the state to their partner. The first component of this learning process has been well-studied in multi-agent systems, whereas the second --- which is equally crucial for a successful collaboration --- has not. In this work, we complete the learning process and introduce our novel algorithm, Policy-Belief-Iteration ("P-BIT"), which mimics both components mentioned above. A belief module models the other agent's private information by observing their actions, whilst a policy module makes use of the inferred private information to return a distribution over actions. They are mutually reinforced with an EM-like algorithm. We use a novel auxiliary reward to encourage information exchange by actions. We evaluate our approach on the non-competitive bidding problem from contract bridge and show that by self-play agents are able to effectively collaborate with implicit communication, and P-BIT outperforms several meaningful baselines that have been considered.
Unsupervised Deep Domain Adaptation for Pedestrian Detection
Feb 09, 2018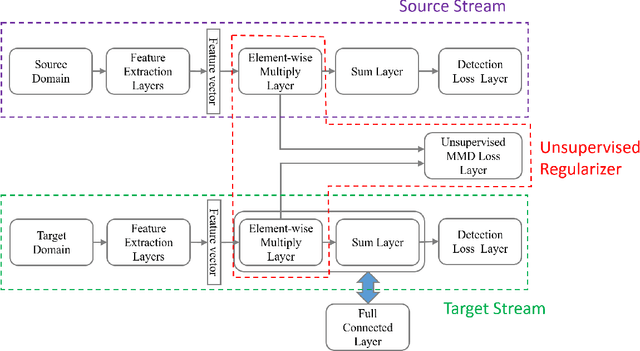
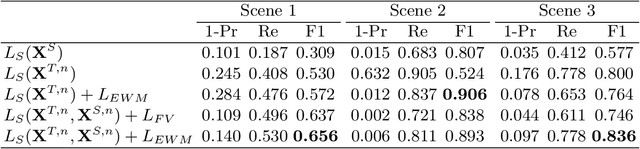
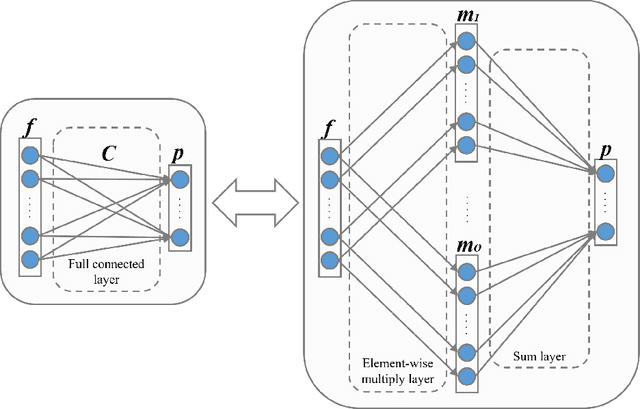

This paper addresses the problem of unsupervised domain adaptation on the task of pedestrian detection in crowded scenes. First, we utilize an iterative algorithm to iteratively select and auto-annotate positive pedestrian samples with high confidence as the training samples for the target domain. Meanwhile, we also reuse negative samples from the source domain to compensate for the imbalance between the amount of positive samples and negative samples. Second, based on the deep network we also design an unsupervised regularizer to mitigate influence from data noise. More specifically, we transform the last fully connected layer into two sub-layers - an element-wise multiply layer and a sum layer, and add the unsupervised regularizer to further improve the domain adaptation accuracy. In experiments for pedestrian detection, the proposed method boosts the recall value by nearly 30% while the precision stays almost the same. Furthermore, we perform our method on standard domain adaptation benchmarks on both supervised and unsupervised settings and also achieve state-of-the-art results.