 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
Apr 01, 2025In this work, we undertake the challenge of augmenting the existing generative capabilities of pre-trained text-only large language models (LLMs) with multi-modal generation capability while satisfying two core constraints: C1 preserving the preservation of original language generative capabilities with negligible performance degradation, and C2 adhering to a small parameter budget to learn the new modality, ensuring scalability and efficiency. In contrast to current approaches that add dedicated modules, thereby significantly increasing the parameter count, we propose a method that leverages the underutilized capacity inherent in deep models. Specifically, we exploit the parameter redundancy within Mixture-of-Experts (MoEs) as a source of additional capacity for learning a new modality, enabling better parameter efficiency (C1). Moreover, we preserve the original language generation capabilities by applying low-rank adaptation exclusively to the tokens of the new modality (C2). Furthermore, we introduce a novel parameter initialization scheme based on the Gromov-Wasserstein distance to improve convergence and training stability. Through an extensive analysis of the routing mechanism, we uncover the emergence of modality-specific pathways and decreased redundancy within the experts that can efficiently unlock multi-modal generative capabilities. Overall, our method can be seamlessly applied to a wide range of contemporary LLMs, providing a new pathway for transitioning from uni-modal to multi-modal architectures.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Mar 14, 2024
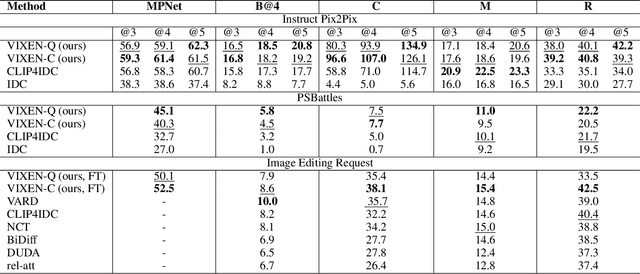
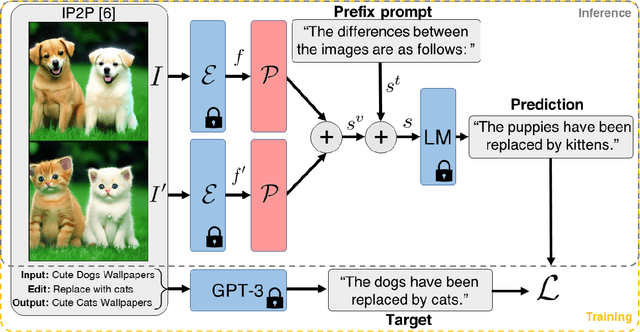
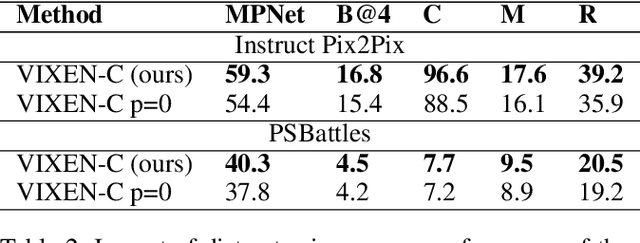
We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen
VADER: Video Alignment Differencing and Retrieval
Mar 25, 2023



We propose VADER, a spatio-temporal matching, alignment, and change summarization method to help fight misinformation spread via manipulated videos. VADER matches and coarsely aligns partial video fragments to candidate videos using a robust visual descriptor and scalable search over adaptively chunked video content. A transformer-based alignment module then refines the temporal localization of the query fragment within the matched video. A space-time comparator module identifies regions of manipulation between aligned content, invariant to any changes due to any residual temporal misalignments or artifacts arising from non-editorial changes of the content. Robustly matching video to a trusted source enables conclusions to be drawn on video provenance, enabling informed trust decisions on content encountered.
Audio-Visual Contrastive Learning with Temporal Self-Supervision
Feb 15, 2023



We propose a self-supervised learning approach for videos that learns representations of both the RGB frames and the accompanying audio without human supervision. In contrast to images that capture the static scene appearance, videos also contain sound and temporal scene dynamics. To leverage the temporal and aural dimension inherent to videos, our method extends temporal self-supervision to the audio-visual setting and integrates it with multi-modal contrastive objectives. As temporal self-supervision, we pose playback speed and direction recognition in both modalities and propose intra- and inter-modal temporal ordering tasks. Furthermore, we design a novel contrastive objective in which the usual pairs are supplemented with additional sample-dependent positives and negatives sampled from the evolving feature space. In our model, we apply such losses among video clips and between videos and their temporally corresponding audio clips. We verify our model design in extensive ablation experiments and evaluate the video and audio representations in transfer experiments to action recognition and retrieval on UCF101 and HMBD51, audio classification on ESC50, and robust video fingerprinting on VGG-Sound, with state-of-the-art results.
SImProv: Scalable Image Provenance Framework for Robust Content Attribution
Jun 28, 2022

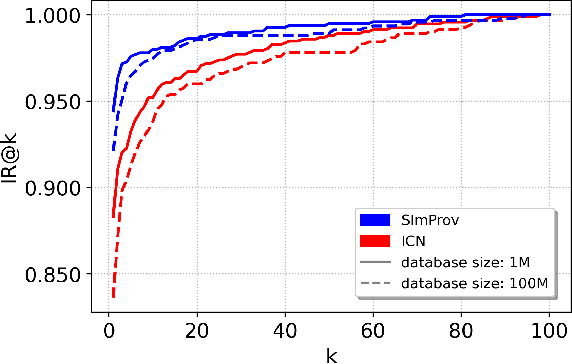

We present SImProv - a scalable image provenance framework to match a query image back to a trusted database of originals and identify possible manipulations on the query. SImProv consists of three stages: a scalable search stage for retrieving top-k most similar images; a re-ranking and near-duplicated detection stage for identifying the original among the candidates; and finally a manipulation detection and visualization stage for localizing regions within the query that may have been manipulated to differ from the original. SImProv is robust to benign image transformations that commonly occur during online redistribution, such as artifacts due to noise and recompression degradation, as well as out-of-place transformations due to image padding, warping, and changes in size and shape. Robustness towards out-of-place transformations is achieved via the end-to-end training of a differentiable warping module within the comparator architecture. We demonstrate effective retrieval and manipulation detection over a dataset of 100 million images.
VPN: Video Provenance Network for Robust Content Attribution
Sep 21, 2021


We present VPN - a content attribution method for recovering provenance information from videos shared online. Platforms, and users, often transform video into different quality, codecs, sizes, shapes, etc. or slightly edit its content such as adding text or emoji, as they are redistributed online. We learn a robust search embedding for matching such video, invariant to these transformations, using full-length or truncated video queries. Once matched against a trusted database of video clips, associated information on the provenance of the clip is presented to the user. We use an inverted index to match temporal chunks of video using late-fusion to combine both visual and audio features. In both cases, features are extracted via a deep neural network trained using contrastive learning on a dataset of original and augmented video clips. We demonstrate high accuracy recall over a corpus of 100,000 videos.
Compositional Sketch Search
Jun 15, 2021


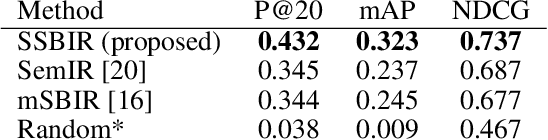
We present an algorithm for searching image collections using free-hand sketches that describe the appearance and relative positions of multiple objects. Sketch based image retrieval (SBIR) methods predominantly match queries containing a single, dominant object invariant to its position within an image. Our work exploits drawings as a concise and intuitive representation for specifying entire scene compositions. We train a convolutional neural network (CNN) to encode masked visual features from sketched objects, pooling these into a spatial descriptor encoding the spatial relationships and appearances of objects in the composition. Training the CNN backbone as a Siamese network under triplet loss yields a metric search embedding for measuring compositional similarity which may be efficiently leveraged for visual search by applying product quantization.