 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogramless Time-Domain Sketched Fluorescence Lifetime Imaging
May 07, 2026We present a statistics-aware compression strategy that processes photon timestamps directly from time-correlated single-photon counting (TCSPC) modules for time-domain fluorescence lifetime imaging (FLIM). Rather than storing or transmitting the full histogram per pixel, timestamps are projected onto sparse, non-uniform one-dimensional spline sketches, with knot positions optimally allocated based on Fisher information. This knot allocation concentrates sketch channels where the decay signal exhibits the greatest statistical discriminability, rather than using a uniform allocation. The proposed approach is extensively validated on synthetic mono- and bi-exponential decay data and on experimental fluorescent dye data, demonstrating comparable accuracy to full-histogram non-linear least-squares fitting (NLSF) and Poisson maximum-likelihood estimation (MLE) at compression ratios of up to 256x. We further validate the feasibility of integrating the timestamp-to-sketch projection directly into firmware via fixed-point (FXP) lookup-table (LUT) simulation, targeting high-spatial-resolution single-photon avalanche diode (SPAD) arrays subject to significant data-throughput constraints.
Perspective-Equivariant Fine-tuning for Multispectral Demosaicing without Ground Truth
Mar 02, 2026Multispectral demosaicing is crucial to reconstruct full-resolution spectral images from snapshot mosaiced measurements, enabling real-time imaging from neurosurgery to autonomous driving. Classical methods are blurry, while supervised learning requires costly ground truth (GT) obtained from slow line-scanning systems. We propose Perspective-Equivariant Fine-tuning for Demosaicing (PEFD), a framework that learns multispectral demosaicing from mosaiced measurements alone. PEFD a) exploits the projective geometry of camera-based imaging systems to leverage a richer group structure than previous demosaicing methods to recover more null-space information, and b) learns efficiently without GT by adapting pretrained foundation models designed for 1-3 channel imaging. On intraoperative and automotive datasets, PEFD recovers fine details such as blood vessels and preserves spectral fidelity, substantially outperforming recent approaches, nearing supervised performance.
Efficient Plug-and-Play method for Dynamic Imaging Via Kalman Smoothing
Feb 13, 2026State-space models (SSM) are common in signal processing, where Kalman smoothing (KS) methods are state-of-the-art. However, traditional KS techniques lack expressivity as they do not incorporate spatial prior information. Recently, [1] proposed an ADMM algorithm that handles the state-space fidelity term with KS while regularizing the object via a sparsity-based prior with proximity operators. Plug-and-Play (PnP) methods are a popular type of iterative algorithms that replace proximal operators encoding prior knowledge with powerful denoisers such as deep neural networks. These methods are widely used in image processing, achieving state-of-the-art results. In this work, we build on the KS-ADMM method, combining it with deep learning to achieve higher expressivity. We propose a PnP algorithm based on KS-ADMM iterations, efficiently handling the SSM through KS, while enabling the use of powerful denoising networks. Simulations on a 2D+t imaging problem show that the proposed PnP-KS-ADMM algorithm improves the computational efficiency over standard PnP-ADMM for large numbers of timesteps.
FPGA Implementation of Sketched LiDAR for a 192 x 128 SPAD Image Sensor
Feb 11, 2026This study presents an efficient field-programmable gate array (FPGA) implementation of a polynomial spline function-based statistical compression algorithm designed to address the critical challenge of massive data transfer bandwidth in emerging high-spatial-resolution single-photon avalanche diode (SPAD) arrays, where data rates can reach tens of gigabytes per second. In our experiments, the proposed hardware implementation achieves a compression ratio of 512x compared with conventional histogram-based outputs, with the potential for further improvement. The algorithm is first optimized in software using fixed-point (FXP) arithmetic and look-up tables (LUTs) to eliminate explicit additions, multiplications, and non-linear operations. This enables a careful balance between accuracy and hardware resource utilization. Guided by this trade-off analysis, online sketch processing elements (SPEs) are implemented on an FPGA to directly process time-stamp streams from the SPAD sensor. The implementation is validated using a customized LiDAR setup with a 192 x 128-pixel SPAD array. This work demonstrates histogram-free online depth reconstruction with high fidelity, effectively alleviating the time-stamp transfer bottleneck of SPAD arrays and offering scalability as pixel counts continue to increase for future SPADs.
SHARE: A Fully Unsupervised Framework for Single Hyperspectral Image Restoration
Jan 20, 2026Hyperspectral image (HSI) restoration is a fundamental challenge in computational imaging and computer vision. It involves ill-posed inverse problems, such as inpainting and super-resolution. Although deep learning methods have transformed the field through data-driven learning, their effectiveness hinges on access to meticulously curated ground-truth datasets. This fundamentally restricts their applicability in real-world scenarios where such data is unavailable. This paper presents SHARE (Single Hyperspectral Image Restoration with Equivariance), a fully unsupervised framework that unifies geometric equivariance principles with low-rank spectral modelling to eliminate the need for ground truth. SHARE's core concept is to exploit the intrinsic invariance of hyperspectral structures under differentiable geometric transformations (e.g. rotations and scaling) to derive self-supervision signals through equivariance consistency constraints. Our novel Dynamic Adaptive Spectral Attention (DASA) module further enhances this paradigm shift by explicitly encoding the global low-rank property of HSI and adaptively refining local spectral-spatial correlations through learnable attention mechanisms. Extensive experiments on HSI inpainting and super-resolution tasks demonstrate the effectiveness of SHARE. Our method outperforms many state-of-the-art unsupervised approaches and achieves performance comparable to that of supervised methods. We hope that our approach will shed new light on HSI restoration and broader scientific imaging scenarios. The code will be released at https://github.com/xuwayyy/SHARE.
Self-Supervised Learning from Noisy and Incomplete Data
Jan 06, 2026Many important problems in science and engineering involve inferring a signal from noisy and/or incomplete observations, where the observation process is known. Historically, this problem has been tackled using hand-crafted regularization (e.g., sparsity, total-variation) to obtain meaningful estimates. Recent data-driven methods often offer better solutions by directly learning a solver from examples of ground-truth signals and associated observations. However, in many real-world applications, obtaining ground-truth references for training is expensive or impossible. Self-supervised learning methods offer a promising alternative by learning a solver from measurement data alone, bypassing the need for ground-truth references. This manuscript provides a comprehensive summary of different self-supervised methods for inverse problems, with a special emphasis on their theoretical underpinnings, and presents practical applications in imaging inverse problems.
Benchmarking Self-Supervised Methods for Accelerated MRI Reconstruction
Feb 23, 2025


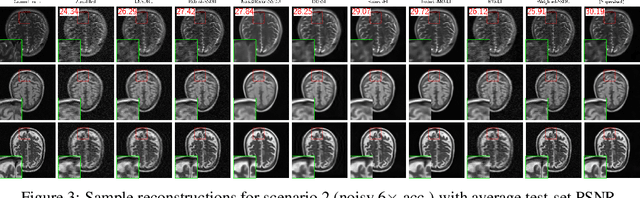
Reconstructing MRI from highly undersampled measurements is crucial for accelerating medical imaging, but is challenging due to the ill-posedness of the inverse problem. While supervised deep learning approaches have shown remarkable success, they rely on fully-sampled ground truth data, which is often impractical or impossible to obtain. Recently, numerous self-supervised methods have emerged that do not require ground truth, however, the lack of systematic comparison and standard experimental setups have hindered research. We present the first comprehensive review of loss functions from all feedforward self-supervised methods and the first benchmark on accelerated MRI reconstruction without ground truth, showing that there is a wide range in performance across methods. In addition, we propose Multi-Operator Equivariant Imaging (MO-EI), a novel framework that builds on the imaging model considered in existing methods to outperform all state-of-the-art and approaches supervised performance. Finally, to facilitate reproducible benchmarking, we provide implementations of all methods in the DeepInverse library (https://deepinv.github.io) and easy-to-use demo code at https://andrewwango.github.io/deepinv-selfsup-fastmri.
Fully Unsupervised Dynamic MRI Reconstruction via Diffeo-Temporal Equivariance
Oct 11, 2024



Reconstructing dynamic MRI image sequences from undersampled accelerated measurements is crucial for faster and higher spatiotemporal resolution real-time imaging of cardiac motion, free breathing motion and many other applications. Classical paradigms, such as gated cine MRI, assume periodicity, disallowing imaging of true motion. Supervised deep learning methods are fundamentally flawed as, in dynamic imaging, ground truth fully-sampled videos are impossible to truly obtain. We propose an unsupervised framework to learn to reconstruct dynamic MRI sequences from undersampled measurements alone by leveraging natural geometric spatiotemporal equivariances of MRI. Dynamic Diffeomorphic Equivariant Imaging (DDEI) significantly outperforms state-of-the-art unsupervised methods such as SSDU on highly accelerated dynamic cardiac imaging. Our method is agnostic to the underlying neural network architecture and can be used to adapt the latest models and post-processing approaches. Our code and video demos are at https://github.com/Andrewwango/ddei.
UNSURE: Unknown Noise level Stein's Unbiased Risk Estimator
Sep 03, 2024

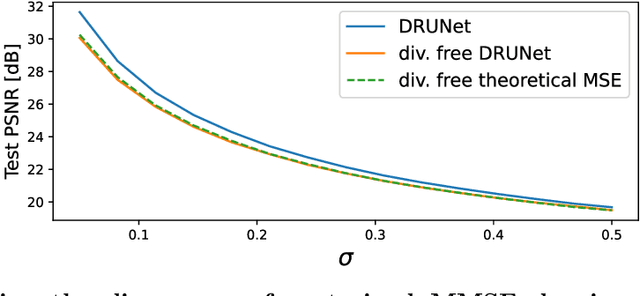

Recently, many self-supervised learning methods for image reconstruction have been proposed that can learn from noisy data alone, bypassing the need for ground-truth references. Most existing methods cluster around two classes: i) Noise2Self and similar cross-validation methods that require very mild knowledge about the noise distribution, and ii) Stein's Unbiased Risk Estimator (SURE) and similar approaches that assume full knowledge of the distribution. The first class of methods is often suboptimal compared to supervised learning, and the second class is often impractical, as the noise level is generally unknown in real-world applications. In this paper, we provide a theoretical framework that characterizes this expressivity-robustness trade-off and propose a new approach based on SURE, but unlike the standard SURE, does not require knowledge about the noise level. Throughout a series of experiments, we show that the proposed estimator outperforms other existing self-supervised methods on various imaging inverse problems.
Equivariant Imaging for Self-supervised Hyperspectral Image Inpainting
Apr 19, 2024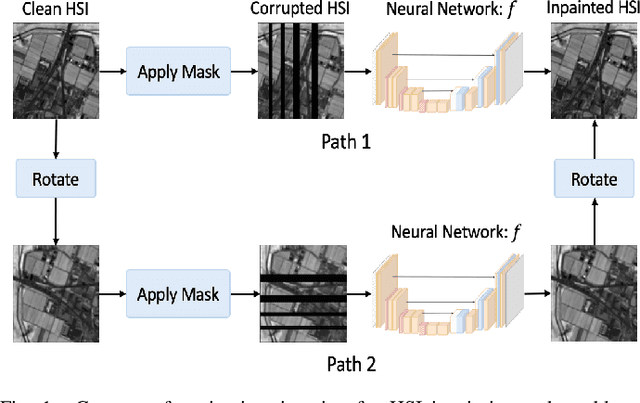
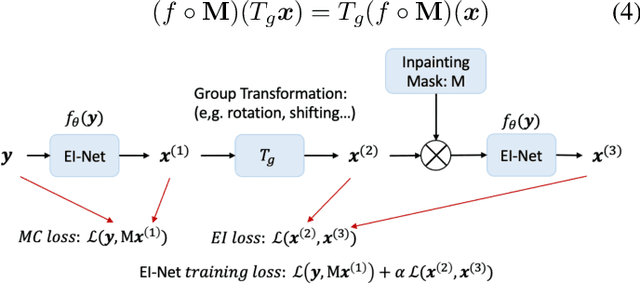
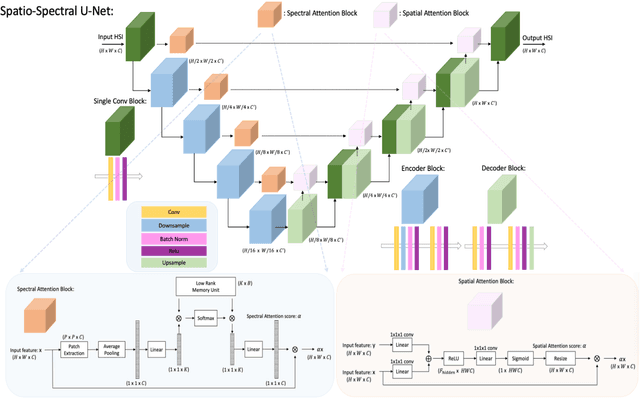

Hyperspectral imaging (HSI) is a key technology for earth observation, surveillance, medical imaging and diagnostics, astronomy and space exploration. The conventional technology for HSI in remote sensing applications is based on the push-broom scanning approach in which the camera records the spectral image of a stripe of the scene at a time, while the image is generated by the aggregation of measurements through time. In real-world airborne and spaceborne HSI instruments, some empty stripes would appear at certain locations, because platforms do not always maintain a constant programmed attitude, or have access to accurate digital elevation maps (DEM), and the travelling track is not necessarily aligned with the hyperspectral cameras at all times. This makes the enhancement of the acquired HS images from incomplete or corrupted observations an essential task. We introduce a novel HSI inpainting algorithm here, called Hyperspectral Equivariant Imaging (Hyper-EI). Hyper-EI is a self-supervised learning-based method which does not require training on extensive datasets or access to a pre-trained model. Experimental results show that the proposed method achieves state-of-the-art inpainting performance compared to the existing methods.