 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Mapping of Neural Networks to Spatial Accelerators
Feb 04, 2026Spatial accelerators, composed of arrays of compute-memory integrated units, offer an attractive platform for deploying inference workloads with low latency and low energy consumption. However, fully exploiting their architectural advantages typically requires careful, expert-driven mapping of computational graphs to distributed processing elements. In this work, we automate this process by framing the mapping challenge as a black-box optimization problem. We introduce the first evolutionary, hardware-in-the-loop mapping framework for neuromorphic accelerators, enabling users without deep hardware knowledge to deploy workloads more efficiently. We evaluate our approach on Intel Loihi 2, a representative spatial accelerator featuring 152 cores per chip in a 2D mesh. Our method achieves up to 35% reduction in total latency compared to default heuristics on two sparse multi-layer perceptron networks. Furthermore, we demonstrate the scalability of our approach to multi-chip systems and observe an up to 40% improvement in energy efficiency, without explicitly optimizing for it.
A Compute and Communication Runtime Model for Loihi 2
Jan 15, 2026Neuromorphic computers hold the potential to vastly improve the speed and efficiency of a wide range of computational kernels with their asynchronous, compute-memory co-located, spatially distributed, and scalable nature. However, performance models that are simple yet sufficiently expressive to predict runtime on actual neuromorphic hardware are lacking, posing a challenge for researchers and developers who strive to design fast algorithms and kernels. As breaking the memory bandwidth wall of conventional von-Neumann architectures is a primary neuromorphic advantage, modeling communication time is especially important. At the same time, modeling communication time is difficult, as complex congestion patterns arise in a heavily-loaded Network-on-Chip. In this work, we introduce the first max-affine lower-bound runtime model -- a multi-dimensional roofline model -- for Intel's Loihi 2 neuromorphic chip that quantitatively accounts for both compute and communication based on a suite of microbenchmarks. Despite being a lower-bound model, we observe a tight correspondence (Pearson correlation coefficient greater than or equal to 0.97) between our model's estimated runtime and the measured runtime on Loihi 2 for a neural network linear layer, i.e., matrix-vector multiplication, and for an example application, a Quadratic Unconstrained Binary Optimization solver. Furthermore, we derive analytical expressions for communication-bottlenecked runtime to study scalability of the linear layer, revealing an area-runtime tradeoff for different spatial workload configurations with linear to superliner runtime scaling in layer size with a variety of constant factors. Our max-affine runtime model helps empower the design of high-speed algorithms and kernels for Loihi 2.
Eventprop training for efficient neuromorphic applications
Mar 06, 2025Neuromorphic computing can reduce the energy requirements of neural networks and holds the promise to `repatriate' AI workloads back from the cloud to the edge. However, training neural networks on neuromorphic hardware has remained elusive. Here, we instead present a pipeline for training spiking neural networks on GPUs, using the efficient event-driven Eventprop algorithm implemented in mlGeNN, and deploying them on Intel's Loihi 2 neuromorphic chip. Our benchmarking on keyword spotting tasks indicates that there is almost no loss in accuracy between GPU and Loihi 2 implementations and that classifying a sample on Loihi 2 is up to 10X faster and uses 200X less energy than on an NVIDIA Jetson Orin Nano.
Accelerating Linear Recurrent Neural Networks for the Edge with Unstructured Sparsity
Feb 03, 2025



Linear recurrent neural networks enable powerful long-range sequence modeling with constant memory usage and time-per-token during inference. These architectures hold promise for streaming applications at the edge, but deployment in resource-constrained environments requires hardware-aware optimizations to minimize latency and energy consumption. Unstructured sparsity offers a compelling solution, enabling substantial reductions in compute and memory requirements--when accelerated by compatible hardware platforms. In this paper, we conduct a scaling study to investigate the Pareto front of performance and efficiency across inference compute budgets. We find that highly sparse linear RNNs consistently achieve better efficiency-performance trade-offs than dense baselines, with 2x less compute and 36% less memory at iso-accuracy. Our models achieve state-of-the-art results on a real-time streaming task for audio denoising. By quantizing our sparse models to fixed-point arithmetic and deploying them on the Intel Loihi 2 neuromorphic chip for real-time processing, we translate model compression into tangible gains of 42x lower latency and 149x lower energy consumption compared to a dense model on an edge GPU. Our findings showcase the transformative potential of unstructured sparsity, paving the way for highly efficient recurrent neural networks in real-world, resource-constrained environments.
Efficient Video and Audio processing with Loihi 2
Oct 05, 2023Loihi 2 is an asynchronous, brain-inspired research processor that generalizes several fundamental elements of neuromorphic architecture, such as stateful neuron models communicating with event-driven spikes, in order to address limitations of the first generation Loihi. Here we explore and characterize some of these generalizations, such as sigma-delta encapsulation, resonate-and-fire neurons, and integer-valued spikes, as applied to standard video, audio, and signal processing tasks. We find that these new neuromorphic approaches can provide orders of magnitude gains in combined efficiency and latency (energy-delay-product) for feed-forward and convolutional neural networks applied to video, audio denoising, and spectral transforms compared to state-of-the-art solutions.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
The Intel Neuromorphic DNS Challenge
Mar 17, 2023A critical enabler for progress in neuromorphic computing research is the ability to transparently evaluate different neuromorphic solutions on important tasks and to compare them to state-of-the-art conventional solutions. The Intel Neuromorphic Deep Noise Suppression Challenge (Intel N-DNS Challenge), inspired by the Microsoft DNS Challenge, tackles a ubiquitous and commercially relevant task: real-time audio denoising. Audio denoising is likely to reap the benefits of neuromorphic computing due to its low-bandwidth, temporal nature and its relevance for low-power devices. The Intel N-DNS Challenge consists of two tracks: a simulation-based algorithmic track to encourage algorithmic innovation, and a neuromorphic hardware (Loihi 2) track to rigorously evaluate solutions. For both tracks, we specify an evaluation methodology based on energy, latency, and resource consumption in addition to output audio quality. We make the Intel N-DNS Challenge dataset scripts and evaluation code freely accessible, encourage community participation with monetary prizes, and release a neuromorphic baseline solution which shows promising audio quality, high power efficiency, and low resource consumption when compared to Microsoft NsNet2 and a proprietary Intel denoising model used in production. We hope the Intel N-DNS Challenge will hasten innovation in neuromorphic algorithms research, especially in the area of training tools and methods for real-time signal processing. We expect the winners of the challenge will demonstrate that for problems like audio denoising, significant gains in power and resources can be realized on neuromorphic devices available today compared to conventional state-of-the-art solutions.
PyMT5: multi-mode translation of natural language and Python code with transformers
Oct 07, 2020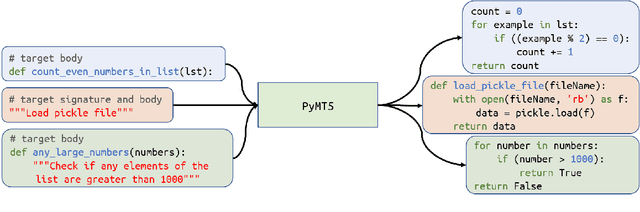
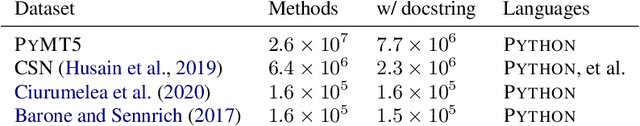
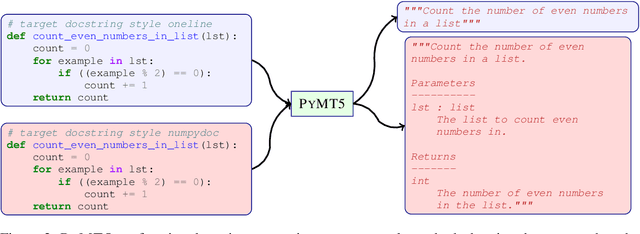
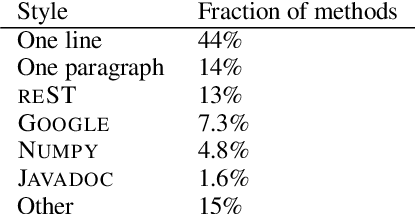
Simultaneously modeling source code and natural language has many exciting applications in automated software development and understanding. Pursuant to achieving such technology, we introduce PyMT5, the Python method text-to-text transfer transformer, which is trained to translate between all pairs of Python method feature combinations: a single model that can both predict whole methods from natural language documentation strings (docstrings) and summarize code into docstrings of any common style. We present an analysis and modeling effort of a large-scale parallel corpus of 26 million Python methods and 7.7 million method-docstring pairs, demonstrating that for docstring and method generation, PyMT5 outperforms similarly-sized auto-regressive language models (GPT2) which were English pre-trained or randomly initialized. On the CodeSearchNet test set, our best model predicts 92.1% syntactically correct method bodies, achieved a BLEU score of 8.59 for method generation and 16.3 for docstring generation (summarization), and achieved a ROUGE-L F-score of 24.8 for method generation and 36.7 for docstring generation.
Predictive coding in balanced neural networks with noise, chaos and delays
Jun 25, 2020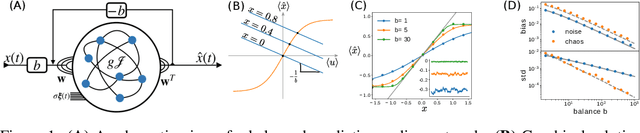
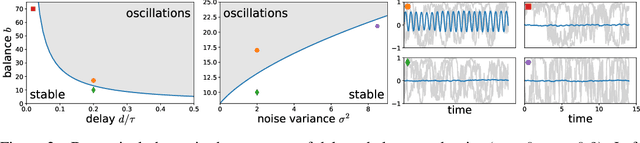

Biological neural networks face a formidable task: performing reliable computations in the face of intrinsic stochasticity in individual neurons, imprecisely specified synaptic connectivity, and nonnegligible delays in synaptic transmission. A common approach to combatting such biological heterogeneity involves averaging over large redundant networks of $N$ neurons resulting in coding errors that decrease classically as $1/\sqrt{N}$. Recent work demonstrated a novel mechanism whereby recurrent spiking networks could efficiently encode dynamic stimuli, achieving a superclassical scaling in which coding errors decrease as $1/N$. This specific mechanism involved two key ideas: predictive coding, and a tight balance, or cancellation between strong feedforward inputs and strong recurrent feedback. However, the theoretical principles governing the efficacy of balanced predictive coding and its robustness to noise, synaptic weight heterogeneity and communication delays remain poorly understood. To discover such principles, we introduce an analytically tractable model of balanced predictive coding, in which the degree of balance and the degree of weight disorder can be dissociated unlike in previous balanced network models, and we develop a mean field theory of coding accuracy. Overall, our work provides and solves a general theoretical framework for dissecting the differential contributions neural noise, synaptic disorder, chaos, synaptic delays, and balance to the fidelity of predictive neural codes, reveals the fundamental role that balance plays in achieving superclassical scaling, and unifies previously disparate models in theoretical neuroscience.