 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeNN: A RISC-V vector processor for Spiking Neural Network acceleration
Jun 13, 2025Spiking Neural Networks (SNNs) have the potential to drastically reduce the energy requirements of AI systems. However, mainstream accelerators like GPUs and TPUs are designed for the high arithmetic intensity of standard ANNs so are not well-suited to SNN simulation. FPGAs are well-suited to applications with low arithmetic intensity as they have high off-chip memory bandwidth and large amounts of on-chip memory. Here, we present a novel RISC-V-based soft vector processor (FeNN), tailored to simulating SNNs on FPGAs. Unlike most dedicated neuromorphic hardware, FeNN is fully programmable and designed to be integrated with applications running on standard computers from the edge to the cloud. We demonstrate that, by using stochastic rounding and saturation, FeNN can achieve high numerical precision with low hardware utilisation and that a single FeNN core can simulate an SNN classifier faster than both an embedded GPU and the Loihi neuromorphic system.
Eventprop training for efficient neuromorphic applications
Mar 06, 2025Neuromorphic computing can reduce the energy requirements of neural networks and holds the promise to `repatriate' AI workloads back from the cloud to the edge. However, training neural networks on neuromorphic hardware has remained elusive. Here, we instead present a pipeline for training spiking neural networks on GPUs, using the efficient event-driven Eventprop algorithm implemented in mlGeNN, and deploying them on Intel's Loihi 2 neuromorphic chip. Our benchmarking on keyword spotting tasks indicates that there is almost no loss in accuracy between GPU and Loihi 2 implementations and that classifying a sample on Loihi 2 is up to 10X faster and uses 200X less energy than on an NVIDIA Jetson Orin Nano.
Efficient Event-based Delay Learning in Spiking Neural Networks
Jan 13, 2025
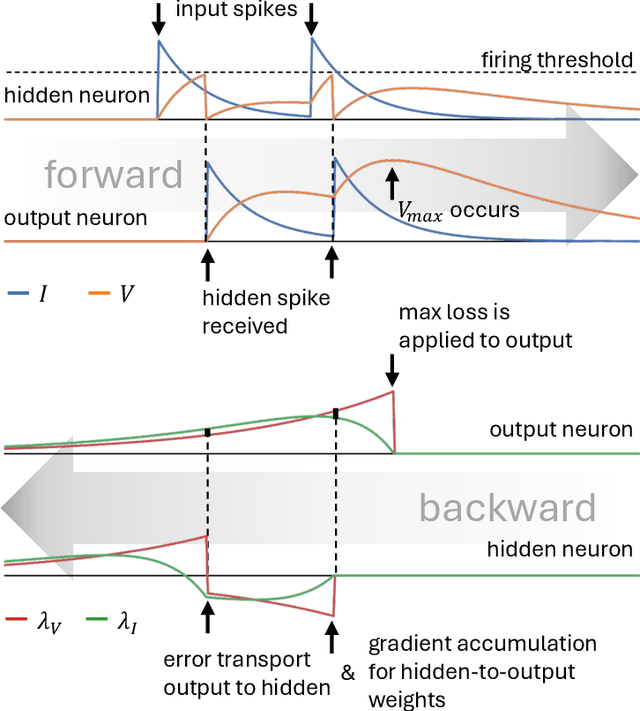
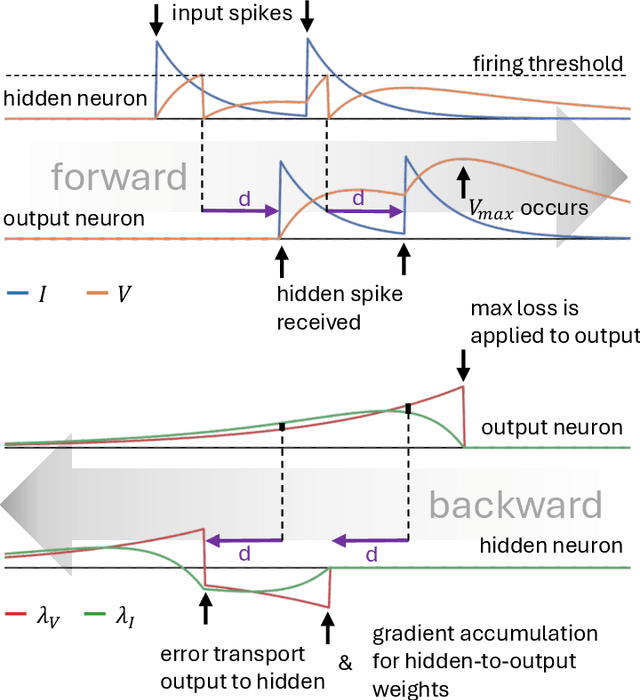
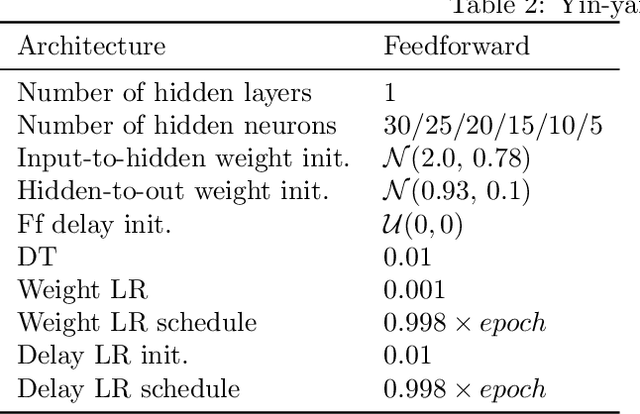
Spiking Neural Networks (SNNs) are attracting increased attention as a more energy-efficient alternative to traditional Artificial Neural Networks. Spiking neurons are stateful and intrinsically recurrent, making them well-suited for spatio-temporal tasks. However, this intrinsic memory is limited by synaptic and membrane time constants. A powerful additional mechanism are delays. In this paper, we propose a novel event-based training method for SNNs with delays, grounded in the EventProp formalism and enabling the calculation of exact gradients with respect to weights and delays. Our method supports multiple spikes per neuron and, to our best knowledge, is the first delay learning method applicable to recurrent connections. We evaluate our method on a simple sequence detection task, and the Yin-Yang, Spiking Heidelberg Digits and Spiking Speech Commands datasets, demonstrating that our algorithm can optimize delays from suboptimal initial conditions and enhance classification accuracy compared to architectures without delays. Finally, we show that our approach uses less than half the memory of the current state-of-the-art delay-learning method and is up to 26x faster.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Loss shaping enhances exact gradient learning with EventProp in Spiking Neural Networks
Dec 02, 2022In a recent paper Wunderlich and Pehle introduced the EventProp algorithm that enables training spiking neural networks by gradient descent on exact gradients. In this paper we present extensions of EventProp to support a wider class of loss functions and an implementation in the GPU enhanced neuronal networks framework which exploits sparsity. The GPU acceleration allows us to test EventProp extensively on more challenging learning benchmarks. We find that EventProp performs well on some tasks but for others there are issues where learning is slow or fails entirely. Here, we analyse these issues in detail and discover that they relate to the use of the exact gradient of the loss function, which by its nature does not provide information about loss changes due to spike creation or spike deletion. Depending on the details of the task and loss function, descending the exact gradient with EventProp can lead to the deletion of important spikes and so to an inadvertent increase of the loss and decrease of classification accuracy and hence a failure to learn. In other situations the lack of knowledge about the benefits of creating additional spikes can lead to a lack of gradient flow into earlier layers, slowing down learning. We eventually present a first glimpse of a solution to these problems in the form of `loss shaping', where we introduce a suitable weighting function into an integral loss to increase gradient flow from the output layer towards earlier layers.