 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Mapping of Neural Networks to Spatial Accelerators
Feb 04, 2026Spatial accelerators, composed of arrays of compute-memory integrated units, offer an attractive platform for deploying inference workloads with low latency and low energy consumption. However, fully exploiting their architectural advantages typically requires careful, expert-driven mapping of computational graphs to distributed processing elements. In this work, we automate this process by framing the mapping challenge as a black-box optimization problem. We introduce the first evolutionary, hardware-in-the-loop mapping framework for neuromorphic accelerators, enabling users without deep hardware knowledge to deploy workloads more efficiently. We evaluate our approach on Intel Loihi 2, a representative spatial accelerator featuring 152 cores per chip in a 2D mesh. Our method achieves up to 35% reduction in total latency compared to default heuristics on two sparse multi-layer perceptron networks. Furthermore, we demonstrate the scalability of our approach to multi-chip systems and observe an up to 40% improvement in energy efficiency, without explicitly optimizing for it.
A Compute and Communication Runtime Model for Loihi 2
Jan 15, 2026Neuromorphic computers hold the potential to vastly improve the speed and efficiency of a wide range of computational kernels with their asynchronous, compute-memory co-located, spatially distributed, and scalable nature. However, performance models that are simple yet sufficiently expressive to predict runtime on actual neuromorphic hardware are lacking, posing a challenge for researchers and developers who strive to design fast algorithms and kernels. As breaking the memory bandwidth wall of conventional von-Neumann architectures is a primary neuromorphic advantage, modeling communication time is especially important. At the same time, modeling communication time is difficult, as complex congestion patterns arise in a heavily-loaded Network-on-Chip. In this work, we introduce the first max-affine lower-bound runtime model -- a multi-dimensional roofline model -- for Intel's Loihi 2 neuromorphic chip that quantitatively accounts for both compute and communication based on a suite of microbenchmarks. Despite being a lower-bound model, we observe a tight correspondence (Pearson correlation coefficient greater than or equal to 0.97) between our model's estimated runtime and the measured runtime on Loihi 2 for a neural network linear layer, i.e., matrix-vector multiplication, and for an example application, a Quadratic Unconstrained Binary Optimization solver. Furthermore, we derive analytical expressions for communication-bottlenecked runtime to study scalability of the linear layer, revealing an area-runtime tradeoff for different spatial workload configurations with linear to superliner runtime scaling in layer size with a variety of constant factors. Our max-affine runtime model helps empower the design of high-speed algorithms and kernels for Loihi 2.
Accelerating Linear Recurrent Neural Networks for the Edge with Unstructured Sparsity
Feb 03, 2025



Linear recurrent neural networks enable powerful long-range sequence modeling with constant memory usage and time-per-token during inference. These architectures hold promise for streaming applications at the edge, but deployment in resource-constrained environments requires hardware-aware optimizations to minimize latency and energy consumption. Unstructured sparsity offers a compelling solution, enabling substantial reductions in compute and memory requirements--when accelerated by compatible hardware platforms. In this paper, we conduct a scaling study to investigate the Pareto front of performance and efficiency across inference compute budgets. We find that highly sparse linear RNNs consistently achieve better efficiency-performance trade-offs than dense baselines, with 2x less compute and 36% less memory at iso-accuracy. Our models achieve state-of-the-art results on a real-time streaming task for audio denoising. By quantizing our sparse models to fixed-point arithmetic and deploying them on the Intel Loihi 2 neuromorphic chip for real-time processing, we translate model compression into tangible gains of 42x lower latency and 149x lower energy consumption compared to a dense model on an edge GPU. Our findings showcase the transformative potential of unstructured sparsity, paving the way for highly efficient recurrent neural networks in real-world, resource-constrained environments.
Solving QUBO on the Loihi 2 Neuromorphic Processor
Aug 06, 2024In this article, we describe an algorithm for solving Quadratic Unconstrained Binary Optimization problems on the Intel Loihi 2 neuromorphic processor. The solver is based on a hardware-aware fine-grained parallel simulated annealing algorithm developed for Intel's neuromorphic research chip Loihi 2. Preliminary results show that our approach can generate feasible solutions in as little as 1 ms and up to 37x more energy efficient compared to two baseline solvers running on a CPU. These advantages could be especially relevant for size-, weight-, and power-constrained edge computing applications.
Mamba-PTQ: Outlier Channels in Recurrent Large Language Models
Jul 17, 2024Modern recurrent layers are emerging as a promising path toward edge deployment of foundation models, especially in the context of large language models (LLMs). Compressing the whole input sequence in a finite-dimensional representation enables recurrent layers to model long-range dependencies while maintaining a constant inference cost for each token and a fixed memory requirement. However, the practical deployment of LLMs in resource-limited environments often requires further model compression, such as quantization and pruning. While these techniques are well-established for attention-based models, their effects on recurrent layers remain underexplored. In this preliminary work, we focus on post-training quantization for recurrent LLMs and show that Mamba models exhibit the same pattern of outlier channels observed in attention-based LLMs. We show that the reason for the difficulty of quantizing SSMs is caused by activation outliers, similar to those observed in transformer-based LLMs. We report baseline results for post-training quantization of Mamba that do not take into account the activation outliers and suggest first steps for outlier-aware quantization.
Q-S5: Towards Quantized State Space Models
Jun 13, 2024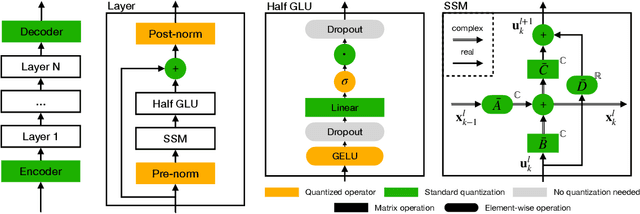
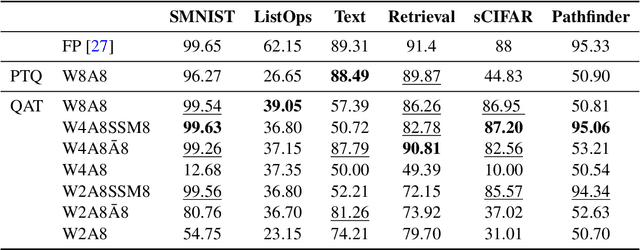
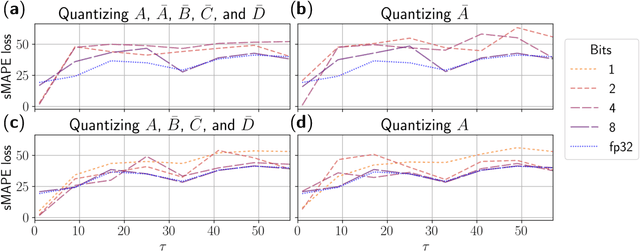
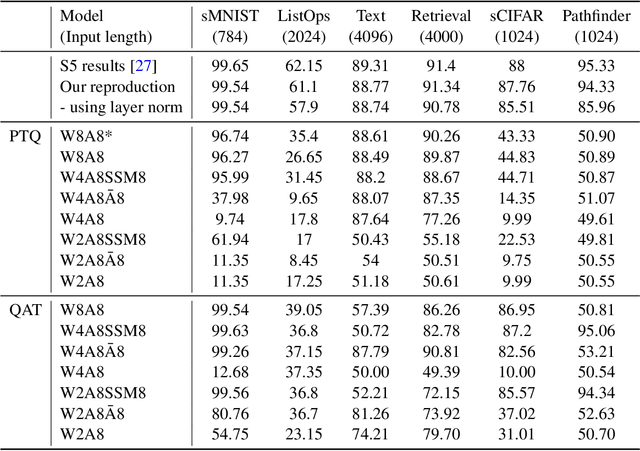
In the quest for next-generation sequence modeling architectures, State Space Models (SSMs) have emerged as a potent alternative to transformers, particularly for their computational efficiency and suitability for dynamical systems. This paper investigates the effect of quantization on the S5 model to understand its impact on model performance and to facilitate its deployment to edge and resource-constrained platforms. Using quantization-aware training (QAT) and post-training quantization (PTQ), we systematically evaluate the quantization sensitivity of SSMs across different tasks like dynamical systems modeling, Sequential MNIST (sMNIST) and most of the Long Range Arena (LRA). We present fully quantized S5 models whose test accuracy drops less than 1% on sMNIST and most of the LRA. We find that performance on most tasks degrades significantly for recurrent weights below 8-bit precision, but that other components can be compressed further without significant loss of performance. Our results further show that PTQ only performs well on language-based LRA tasks whereas all others require QAT. Our investigation provides necessary insights for the continued development of efficient and hardware-optimized SSMs.
Optimization of a Hydrodynamic Computational Reservoir through Evolution
Apr 20, 2023
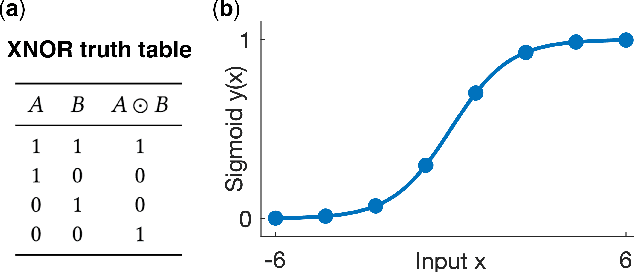


As demand for computational resources reaches unprecedented levels, research is expanding into the use of complex material substrates for computing. In this study, we interface with a model of a hydrodynamic system, under development by a startup, as a computational reservoir and optimize its properties using an evolution in materio approach. Input data are encoded as waves applied to our shallow water reservoir, and the readout wave height is obtained at a fixed detection point. We optimized the readout times and how inputs are mapped to the wave amplitude or frequency using an evolutionary search algorithm, with the objective of maximizing the system's ability to linearly separate observations in the training data by maximizing the readout matrix determinant. Applying evolutionary methods to this reservoir system substantially improved separability on an XNOR task, in comparison to implementations with hand-selected parameters. We also applied our approach to a regression task and show that our approach improves out-of-sample accuracy. Results from this study will inform how we interface with the physical reservoir in future work, and we will use these methods to continue to optimize other aspects of the physical implementation of this system as a computational reservoir.