 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Evaluation of Code LLMs with Round-Trip Correctness
Feb 13, 2024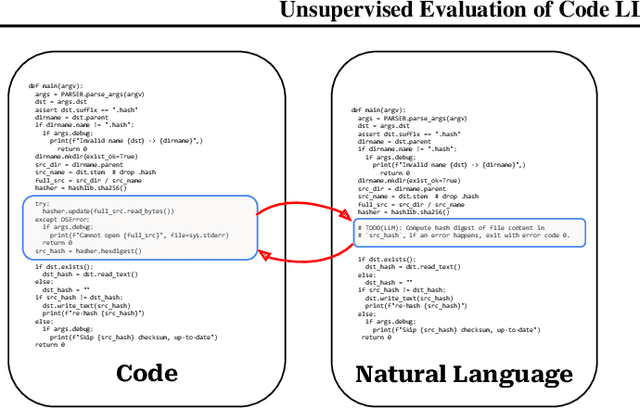

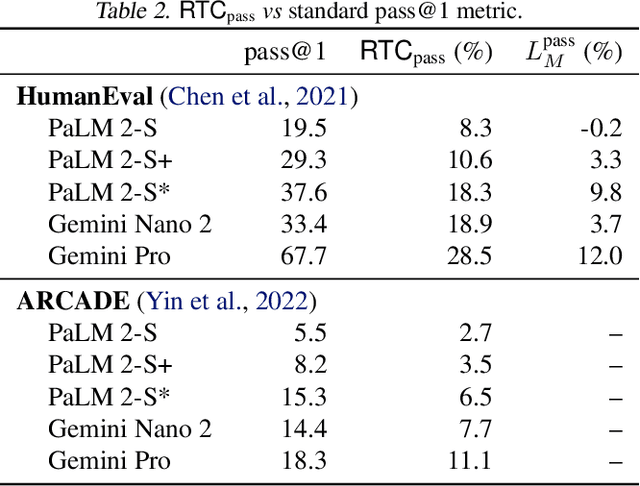
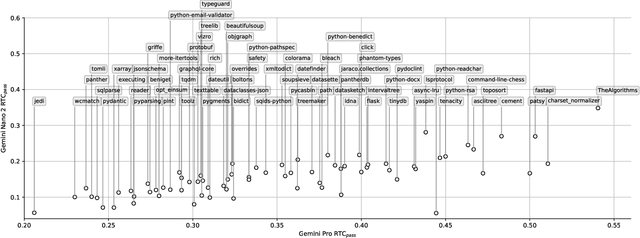
To evaluate code large language models (LLMs), research has relied on a few small manually curated benchmarks, such as HumanEval and MBPP, which represent a narrow part of the real-world software domains. In this work, we introduce round-trip correctness (RTC) as an alternative evaluation method. RTC allows Code LLM evaluation on a broader spectrum of real-world software domains without the need for costly human curation. RTC rests on the idea that we can ask a model to make a prediction (e.g., describe some code using natural language), feed that prediction back (e.g., synthesize code from the predicted description), and check if this round-trip leads to code that is semantically equivalent to the original input. We show how to employ RTC to evaluate code synthesis and editing. We find that RTC strongly correlates with model performance on existing narrow-domain code synthesis benchmarks while allowing us to expand to a much broader set of domains and tasks which was not previously possible without costly human annotations.
Using Developer Discussions to Guide Fixing Bugs in Software
Nov 11, 2022



Automatically fixing software bugs is a challenging task. While recent work showed that natural language context is useful in guiding bug-fixing models, the approach required prompting developers to provide this context, which was simulated through commit messages written after the bug-fixing code changes were made. We instead propose using bug report discussions, which are available before the task is performed and are also naturally occurring, avoiding the need for any additional information from developers. For this, we augment standard bug-fixing datasets with bug report discussions. Using these newly compiled datasets, we demonstrate that various forms of natural language context derived from such discussions can aid bug-fixing, even leading to improved performance over using commit messages corresponding to the oracle bug-fixing commits.
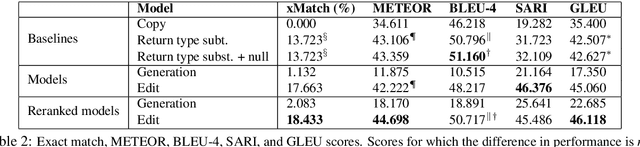
CoditT5: Pretraining for Source Code and Natural Language Editing
Aug 10, 2022

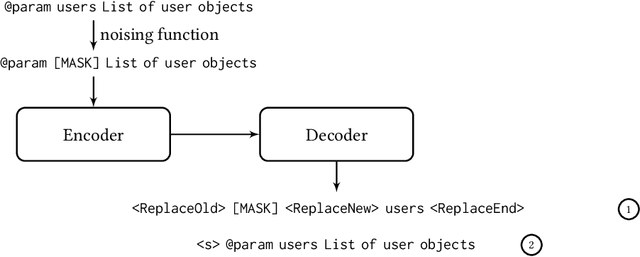
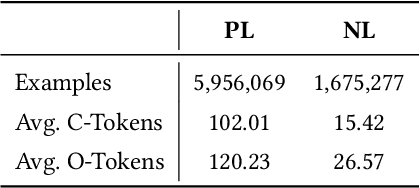
Pretrained language models have been shown to be effective in many software-related generation tasks; however, they are not well-suited for editing tasks as they are not designed to reason about edits. To address this, we propose a novel pretraining objective which explicitly models edits and use it to build CoditT5, a large language model for software-related editing tasks that is pretrained on large amounts of source code and natural language comments. We fine-tune it on various downstream editing tasks, including comment updating, bug fixing, and automated code review. By outperforming pure generation-based models, we demonstrate the generalizability of our approach and its suitability for editing tasks. We also show how a pure generation model and our edit-based model can complement one another through simple reranking strategies, with which we achieve state-of-the-art performance for the three downstream editing tasks.
Learning to Describe Solutions for Bug Reports Based on Developer Discussions
Oct 08, 2021
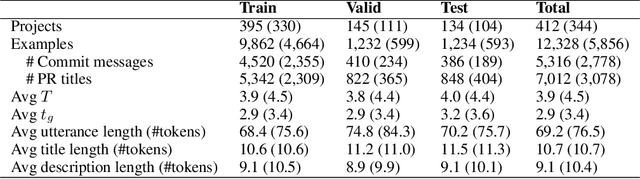

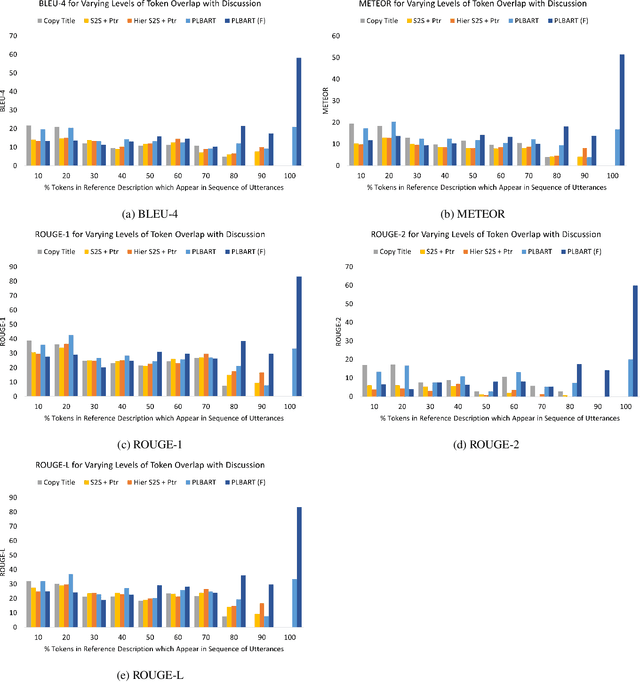
When a software bug is reported, developers engage in a discussion to collaboratively resolve it. While the solution is likely formulated within the discussion, it is often buried in a large amount of text, making it difficult to comprehend, which delays its implementation. To expedite bug resolution, we propose generating a concise natural language description of the solution by synthesizing relevant content within the discussion, which encompasses both natural language and source code. Furthermore, to support generating an informative description during an ongoing discussion, we propose a secondary task of determining when sufficient context about the solution emerges in real-time. We construct a dataset for these tasks with a novel technique for obtaining noisy supervision from repository changes linked to bug reports. We establish baselines for generating solution descriptions, and develop a classifier which makes a prediction following each new utterance on whether or not the necessary context for performing generation is available. Through automated and human evaluation, we find these tasks to form an ideal testbed for complex reasoning in long, bimodal dialogue context.
Learning to Generate Code Comments from Class Hierarchies
Apr 17, 2021
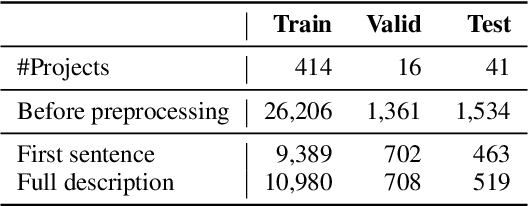


Descriptive code comments are essential for supporting code comprehension and maintenance. We propose the task of automatically generating comments for overriding methods. We formulate a novel framework which accommodates the unique contextual and linguistic reasoning that is required for performing this task. Our approach features: (1) incorporating context from the class hierarchy; (2) conditioning on learned, latent representations of specificity to generate comments that capture the more specialized behavior of the overriding method; and (3) unlikelihood training to discourage predictions which do not conform to invariant characteristics of the comment corresponding to the overridden method. Our experiments show that the proposed approach is able to generate comments for overriding methods of higher quality compared to prevailing comment generation techniques.
Deep Just-In-Time Inconsistency Detection Between Comments and Source Code
Oct 04, 2020
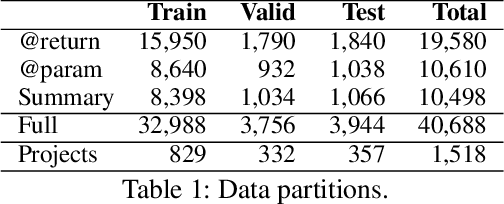
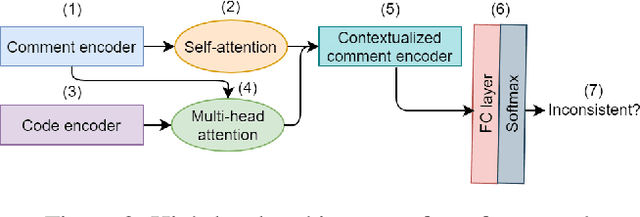
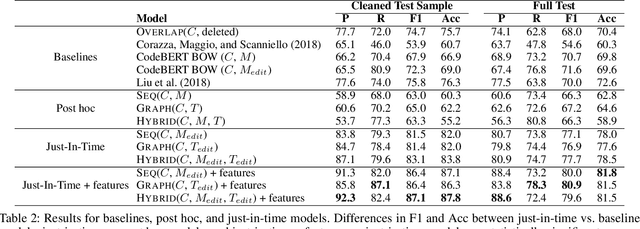
Natural language comments convey key aspects of source code such as implementation, usage, and pre- and post-conditions. Failure to update comments accordingly when the corresponding code is modified introduces inconsistencies, which is known to lead to confusion and software bugs. In this paper, we aim to detect whether a comment becomes inconsistent as a result of changes to the corresponding body of code, in order to catch potential inconsistencies just-in-time, i.e., before they are committed to a version control system. To achieve this, we develop a deep-learning approach that learns to correlate a comment with code changes. By evaluating on a large corpus of comment/code pairs spanning various comment types, we show that our model outperforms multiple baselines by significant margins. For extrinsic evaluation, we show the usefulness of our approach by combining it with a comment update model to build a more comprehensive automatic comment maintenance system which can both detect and resolve inconsistent comments based on code changes.
Copy that! Editing Sequences by Copying Spans
Jun 08, 2020

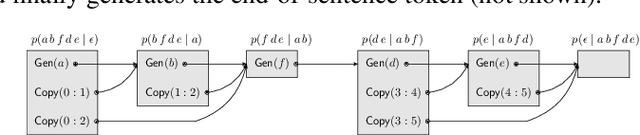
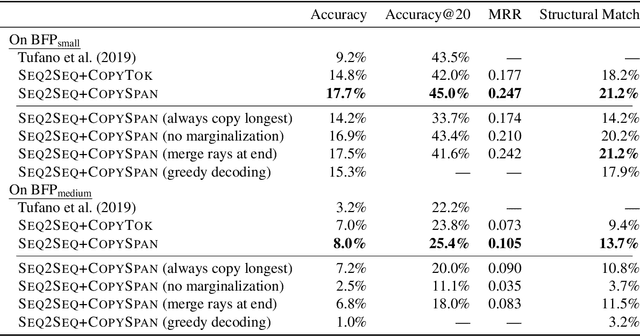
Neural sequence-to-sequence models are finding increasing use in editing of documents, for example in correcting a text document or repairing source code. In this paper, we argue that common seq2seq models (with a facility to copy single tokens) are not a natural fit for such tasks, as they have to explicitly copy each unchanged token. We present an extension of seq2seq models capable of copying entire spans of the input to the output in one step, greatly reducing the number of decisions required during inference. This extension means that there are now many ways of generating the same output, which we handle by deriving a new objective for training and a variation of beam search for inference that explicitly handle this problem. In our experiments on a range of editing tasks of natural language and source code, we show that our new model consistently outperforms simpler baselines.
Learning to Update Natural Language Comments Based on Code Changes
Apr 28, 2020
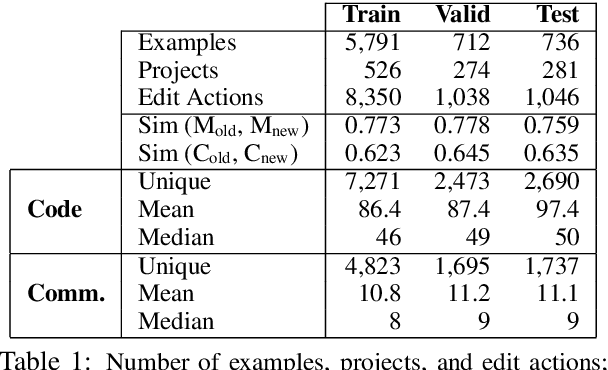

We formulate the novel task of automatically updating an existing natural language comment based on changes in the body of code it accompanies. We propose an approach that learns to correlate changes across two distinct language representations, to generate a sequence of edits that are applied to the existing comment to reflect the source code modifications. We train and evaluate our model using a dataset that we collected from commit histories of open-source software projects, with each example consisting of a concurrent update to a method and its corresponding comment. We compare our approach against multiple baselines using both automatic metrics and human evaluation. Results reflect the challenge of this task and that our model outperforms baselines with respect to making edits.
Associating Natural Language Comment and Source Code Entities
Dec 13, 2019
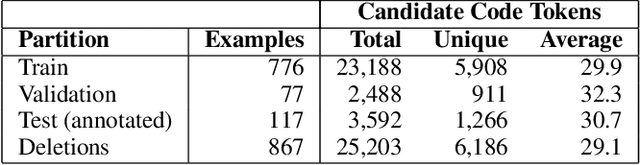
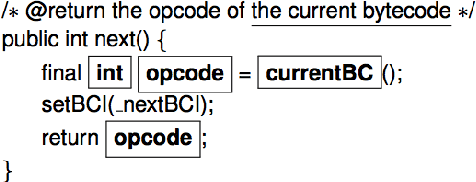
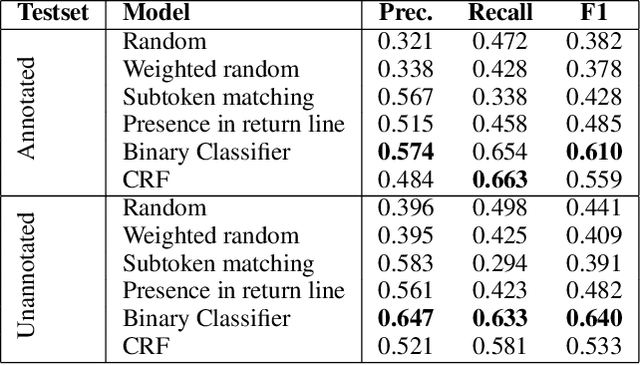
Comments are an integral part of software development; they are natural language descriptions associated with source code elements. Understanding explicit associations can be useful in improving code comprehensibility and maintaining the consistency between code and comments. As an initial step towards this larger goal, we address the task of associating entities in Javadoc comments with elements in Java source code. We propose an approach for automatically extracting supervised data using revision histories of open source projects and present a manually annotated evaluation dataset for this task. We develop a binary classifier and a sequence labeling model by crafting a rich feature set which encompasses various aspects of code, comments, and the relationships between them. Experiments show that our systems outperform several baselines learning from the proposed supervision.