 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary Volumetric Refocusing of Dense and Sparse Light Fields
Feb 26, 2025A four-dimensional light field (LF) captures both textural and geometrical information of a scene in contrast to a two-dimensional image that captures only the textural information of a scene. Post-capture refocusing is an exciting application of LFs enabled by the geometric information captured. Previously proposed LF refocusing methods are mostly limited to the refocusing of single planar or volumetric region of a scene corresponding to a depth range and cannot simultaneously generate in-focus and out-of-focus regions having the same depth range. In this paper, we propose an end-to-end pipeline to simultaneously refocus multiple arbitrary planar or volumetric regions of a dense or a sparse LF. We employ pixel-dependent shifts with the typical shift-and-sum method to refocus an LF. The pixel-dependent shifts enables to refocus each pixel of an LF independently. For sparse LFs, the shift-and-sum method introduces ghosting artifacts due to the spatial undersampling. We employ a deep learning model based on U-Net architecture to almost completely eliminate the ghosting artifacts. The experimental results obtained with several LF datasets confirm the effectiveness of the proposed method. In particular, sparse LFs refocused with the proposed method archive structural similarity index higher than 0.9 despite having only 20% of data compared to dense LFs.
Dynamic Template Initialization for Part-Aware Person Re-ID
Aug 24, 2022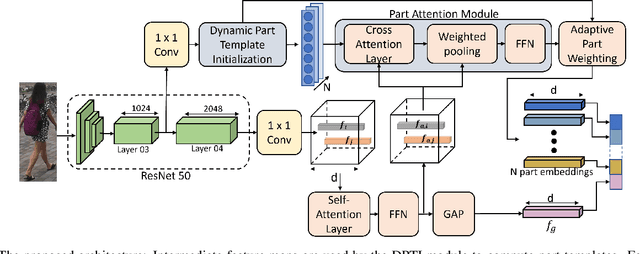
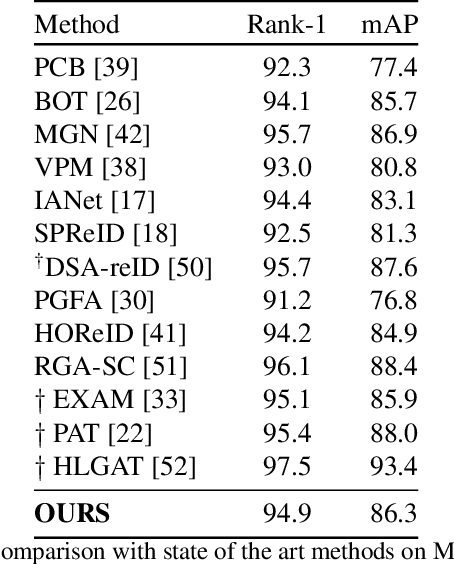
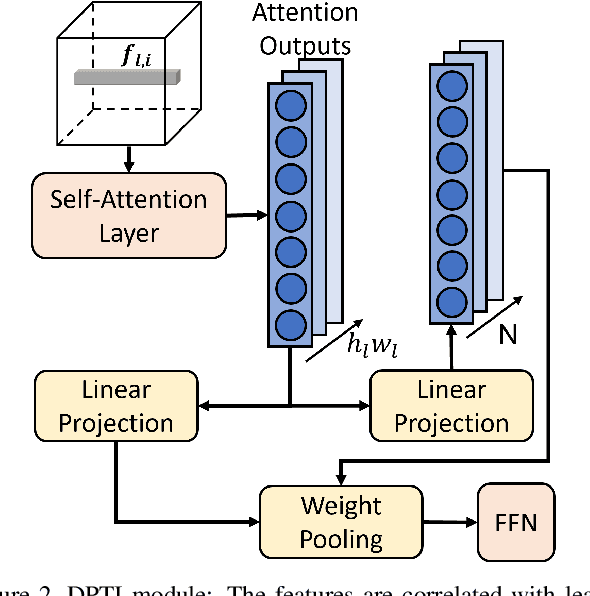
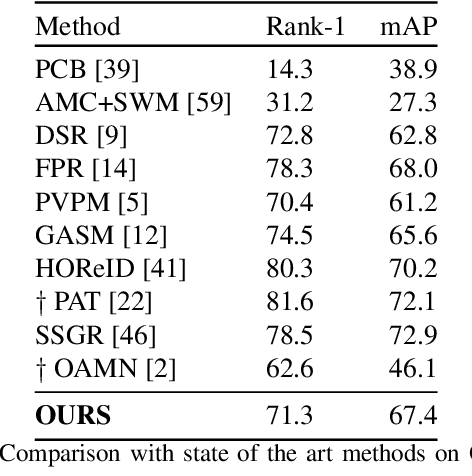
Many of the existing Person Re-identification (Re-ID) approaches depend on feature maps which are either partitioned to localize parts of a person or reduced to create a global representation. While part localization has shown significant success, it uses either na{\i}ve position-based partitions or static feature templates. These, however, hypothesize the pre-existence of the parts in a given image or their positions, ignoring the input image-specific information which limits their usability in challenging scenarios such as Re-ID with partial occlusions and partial probe images. In this paper, we introduce a spatial attention-based Dynamic Part Template Initialization module that dynamically generates part-templates using mid-level semantic features at the earlier layers of the backbone. Following a self-attention layer, human part-level features of the backbone are used to extract the templates of diverse human body parts using a simplified cross-attention scheme which will then be used to identify and collate representations of various human parts from semantically rich features, increasing the discriminative ability of the entire model. We further explore adaptive weighting of part descriptors to quantify the absence or occlusion of local attributes and suppress the contribution of the corresponding part descriptors to the matching criteria. Extensive experiments on holistic, occluded, and partial Re-ID task benchmarks demonstrate that our proposed architecture is able to achieve competitive performance. Codes will be included in the supplementary material and will be made publicly available.
KORSAL: Key-point Detection based Online Real-Time Spatio-Temporal Action Localization
Nov 05, 2021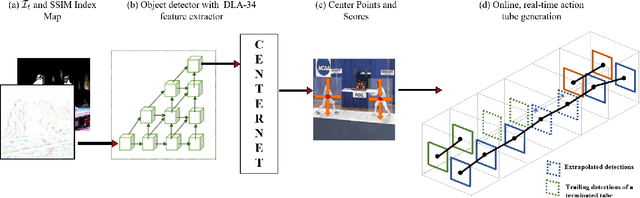
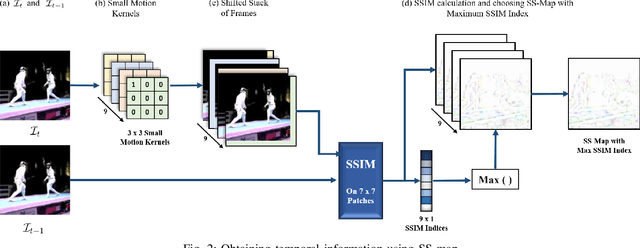

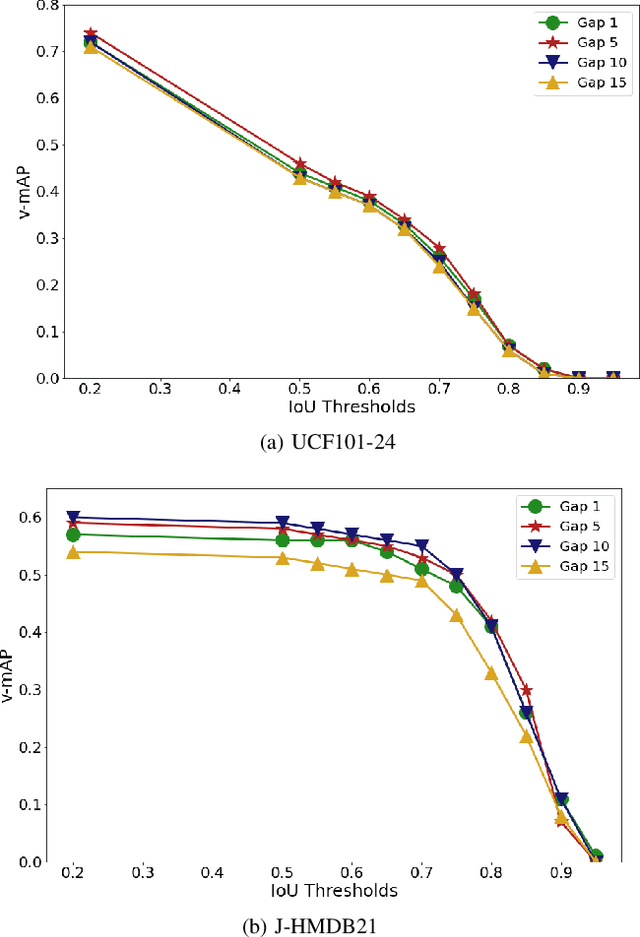
Real-time and online action localization in a video is a critical yet highly challenging problem. Accurate action localization requires the utilization of both temporal and spatial information. Recent attempts achieve this by using computationally intensive 3D CNN architectures or highly redundant two-stream architectures with optical flow, making them both unsuitable for real-time, online applications. To accomplish activity localization under highly challenging real-time constraints, we propose utilizing fast and efficient key-point based bounding box prediction to spatially localize actions. We then introduce a tube-linking algorithm that maintains the continuity of action tubes temporally in the presence of occlusions. Further, we eliminate the need for a two-stream architecture by combining temporal and spatial information into a cascaded input to a single network, allowing the network to learn from both types of information. Temporal information is efficiently extracted using a structural similarity index map as opposed to computationally intensive optical flow. Despite the simplicity of our approach, our lightweight end-to-end architecture achieves state-of-the-art frame-mAP of 74.7% on the challenging UCF101-24 dataset, demonstrating a performance gain of 6.4% over the previous best online methods. We also achieve state-of-the-art video-mAP results compared to both online and offline methods. Moreover, our model achieves a frame rate of 41.8 FPS, which is a 10.7% improvement over contemporary real-time methods.