 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Template Initialization for Part-Aware Person Re-ID
Aug 24, 2022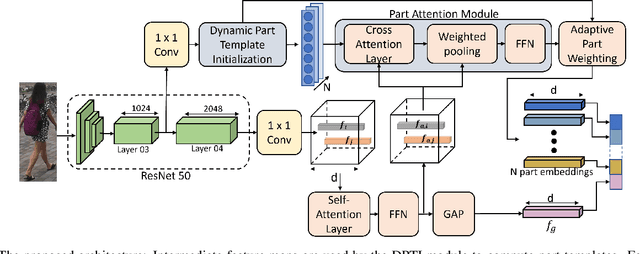
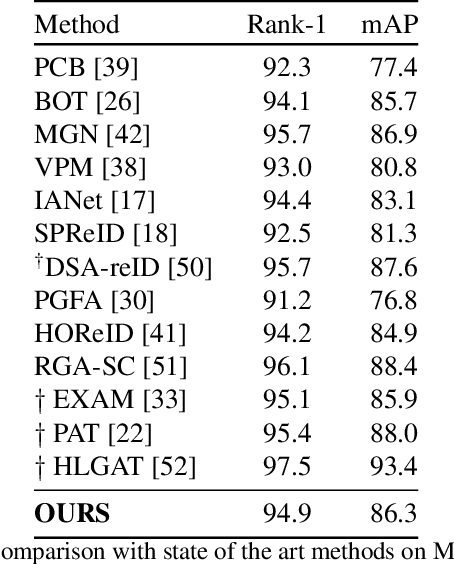
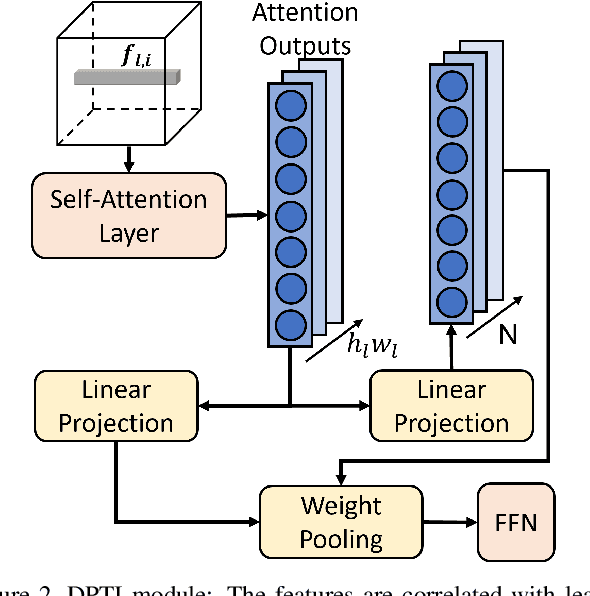
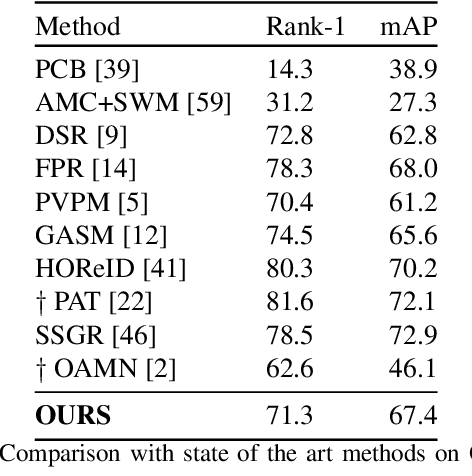
Many of the existing Person Re-identification (Re-ID) approaches depend on feature maps which are either partitioned to localize parts of a person or reduced to create a global representation. While part localization has shown significant success, it uses either na{\i}ve position-based partitions or static feature templates. These, however, hypothesize the pre-existence of the parts in a given image or their positions, ignoring the input image-specific information which limits their usability in challenging scenarios such as Re-ID with partial occlusions and partial probe images. In this paper, we introduce a spatial attention-based Dynamic Part Template Initialization module that dynamically generates part-templates using mid-level semantic features at the earlier layers of the backbone. Following a self-attention layer, human part-level features of the backbone are used to extract the templates of diverse human body parts using a simplified cross-attention scheme which will then be used to identify and collate representations of various human parts from semantically rich features, increasing the discriminative ability of the entire model. We further explore adaptive weighting of part descriptors to quantify the absence or occlusion of local attributes and suppress the contribution of the corresponding part descriptors to the matching criteria. Extensive experiments on holistic, occluded, and partial Re-ID task benchmarks demonstrate that our proposed architecture is able to achieve competitive performance. Codes will be included in the supplementary material and will be made publicly available.
Reconfigurable co-processor architecture with limited numerical precision to accelerate deep convolutional neural networks
Aug 21, 2021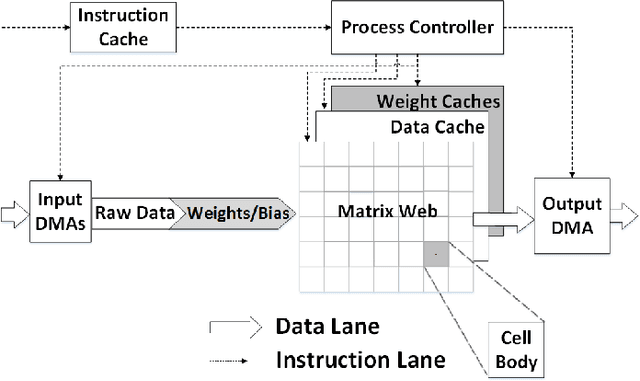
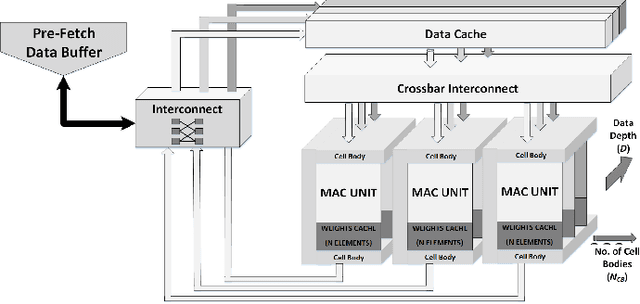
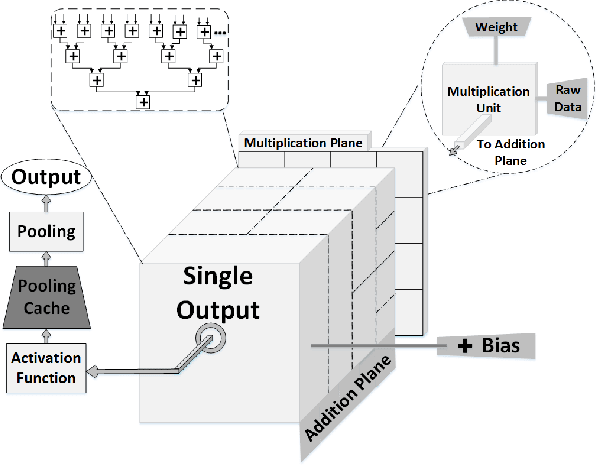

Convolutional Neural Networks (CNNs) are widely used in deep learning applications, e.g. visual systems, robotics etc. However, existing software solutions are not efficient. Therefore, many hardware accelerators have been proposed optimizing performance, power and resource utilization of the implementation. Amongst existing solutions, Field Programmable Gate Array (FPGA) based architecture provides better cost-energy-performance trade-offs as well as scalability and minimizing development time. In this paper, we present a model-independent reconfigurable co-processing architecture to accelerate CNNs. Our architecture consists of parallel Multiply and Accumulate (MAC) units with caching techniques and interconnection networks to exploit maximum data parallelism. In contrast to existing solutions, we introduce limited precision 32 bit Q-format fixed point quantization for arithmetic representations and operations. As a result, our architecture achieved significant reduction in resource utilization with competitive accuracy. Furthermore, we developed an assembly-type microinstructions to access the co-processing fabric to manage layer-wise parallelism, thereby making re-use of limited resources. Finally, we have tested our architecture up to 9x9 kernel size on Xilinx Virtex 7 FPGA, achieving a throughput of up to 226.2 GOp/S for 3x3 kernel size.