 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable co-processor architecture with limited numerical precision to accelerate deep convolutional neural networks
Paper and Code
Aug 21, 2021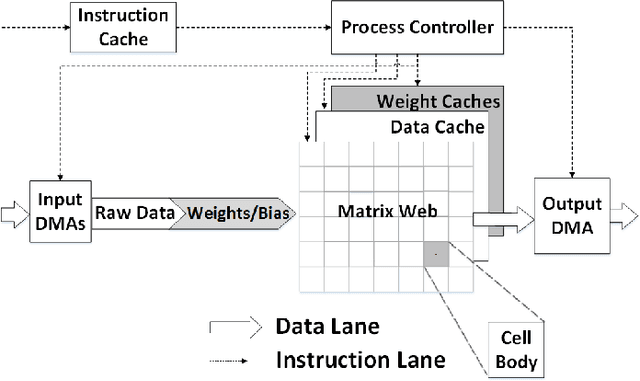
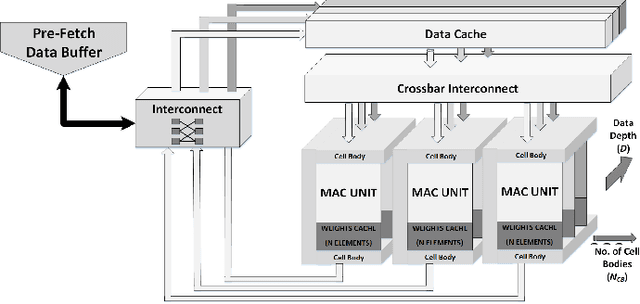
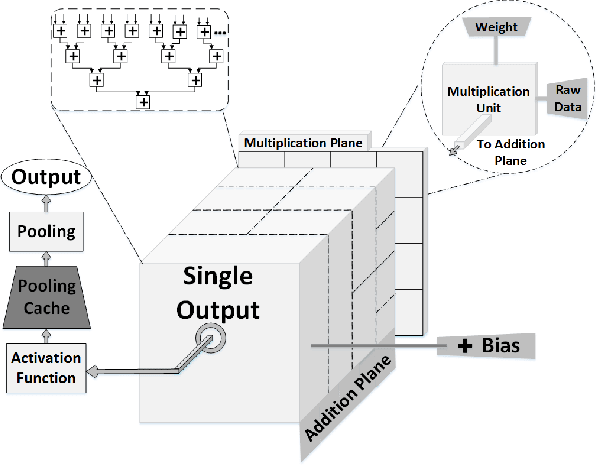

Convolutional Neural Networks (CNNs) are widely used in deep learning applications, e.g. visual systems, robotics etc. However, existing software solutions are not efficient. Therefore, many hardware accelerators have been proposed optimizing performance, power and resource utilization of the implementation. Amongst existing solutions, Field Programmable Gate Array (FPGA) based architecture provides better cost-energy-performance trade-offs as well as scalability and minimizing development time. In this paper, we present a model-independent reconfigurable co-processing architecture to accelerate CNNs. Our architecture consists of parallel Multiply and Accumulate (MAC) units with caching techniques and interconnection networks to exploit maximum data parallelism. In contrast to existing solutions, we introduce limited precision 32 bit Q-format fixed point quantization for arithmetic representations and operations. As a result, our architecture achieved significant reduction in resource utilization with competitive accuracy. Furthermore, we developed an assembly-type microinstructions to access the co-processing fabric to manage layer-wise parallelism, thereby making re-use of limited resources. Finally, we have tested our architecture up to 9x9 kernel size on Xilinx Virtex 7 FPGA, achieving a throughput of up to 226.2 GOp/S for 3x3 kernel size.