 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAHD: Perception-Action based Human Decision Making using Explainable Graph Neural Networks on SAR Images
Jan 05, 2024Synthetic Aperture Radar (SAR) images are commonly utilized in military applications for automatic target recognition (ATR). Machine learning (ML) methods, such as Convolutional Neural Networks (CNN) and Graph Neural Networks (GNN), are frequently used to identify ground-based objects, including battle tanks, personnel carriers, and missile launchers. Determining the vehicle class, such as the BRDM2 tank, BMP2 tank, BTR60 tank, and BTR70 tank, is crucial, as it can help determine whether the target object is an ally or an enemy. While the ML algorithm provides feedback on the recognized target, the final decision is left to the commanding officers. Therefore, providing detailed information alongside the identified target can significantly impact their actions. This detailed information includes the SAR image features that contributed to the classification, the classification confidence, and the probability of the identified object being classified as a different object type or class. We propose a GNN-based ATR framework that provides the final classified class and outputs the detailed information mentioned above. This is the first study to provide a detailed analysis of the classification class, making final decisions more straightforward. Moreover, our GNN framework achieves an overall accuracy of 99.2\% when evaluated on the MSTAR dataset, improving over previous state-of-the-art GNN methods.
Exploiting On-chip Heterogeneity of Versal Architecture for GNN Inference Acceleration
Aug 04, 2023



Graph Neural Networks (GNNs) have revolutionized many Machine Learning (ML) applications, such as social network analysis, bioinformatics, etc. GNN inference can be accelerated by exploiting data sparsity in the input graph, vertex features, and intermediate data in GNN computations. For dynamic sparsity exploitation, we leverage the heterogeneous computing capabilities of AMD Versal ACAP architecture to accelerate GNN inference. We develop a custom hardware module that executes the sparse primitives of the computation kernel on the Programmable Logic (PL) and efficiently computes the dense primitives using the AI Engine (AIE). To exploit data sparsity during inference, we devise a runtime kernel mapping strategy that dynamically assigns computation tasks to the PL and AIE based on data sparsity. Our implementation on the VCK5000 ACAP platform leads to superior performance compared with the state-of-the-art implementations on CPU, GPU, ACAP, and other custom GNN accelerators. Compared with these implementations, we achieve significant average runtime speedup across various models and datasets of 162.42x, 17.01x, 9.90x, and 27.23x, respectively. Furthermore, for Graph Convolutional Network (GCN) inference, our approach leads to a speedup of 3.9-96.7x compared to designs using PL only on the same ACAP device.
Graph Neural Network for Accurate and Low-complexity SAR ATR
May 11, 2023



Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is the key technique for remote sensing image recognition. The state-of-the-art works exploit the deep convolutional neural networks (CNNs) for SAR ATR, leading to high computation costs. These deep CNN models are unsuitable to be deployed on resource-limited platforms. In this work, we propose a graph neural network (GNN) model to achieve accurate and low-latency SAR ATR. We transform the input SAR image into the graph representation. The proposed GNN model consists of a stack of GNN layers that operates on the input graph to perform target classification. Unlike the state-of-the-art CNNs, which need heavy convolution operations, the proposed GNN model has low computation complexity and achieves comparable high accuracy. The GNN-based approach enables our proposed \emph{input pruning} strategy. By filtering out the irrelevant vertices in the input graph, we can reduce the computation complexity. Moreover, we propose the \emph{model pruning} strategy to sparsify the model weight matrices which further reduces the computation complexity. We evaluate the proposed GNN model on the MSTAR dataset and ship discrimination dataset. The evaluation results show that the proposed GNN model achieves 99.38\% and 99.7\% classification accuracy on the above two datasets, respectively. The proposed pruning strategies can prune 98.6\% input vertices and 97\% weight entries with negligible accuracy loss. Compared with the state-of-the-art CNNs, the proposed GNN model has only 1/3000 computation cost and 1/80 model size.
Towards Programmable Memory Controller for Tensor Decomposition
Jul 17, 2022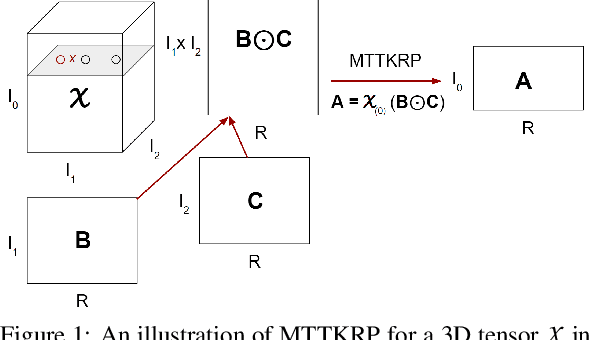

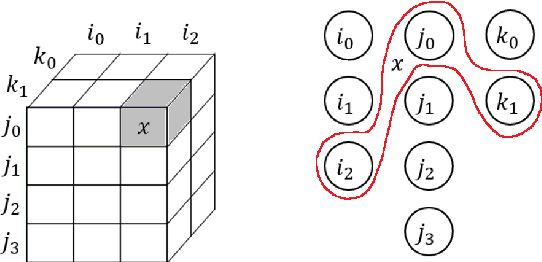
Tensor decomposition has become an essential tool in many data science applications. Sparse Matricized Tensor Times Khatri-Rao Product (MTTKRP) is the pivotal kernel in tensor decomposition algorithms that decompose higher-order real-world large tensors into multiple matrices. Accelerating MTTKRP can speed up the tensor decomposition process immensely. Sparse MTTKRP is a challenging kernel to accelerate due to its irregular memory access characteristics. Implementing accelerators on Field Programmable Gate Array (FPGA) for kernels such as MTTKRP is attractive due to the energy efficiency and the inherent parallelism of FPGA. This paper explores the opportunities, key challenges, and an approach for designing a custom memory controller on FPGA for MTTKRP while exploring the parameter space of such a custom memory controller.
Reconfigurable Low-latency Memory System for Sparse Matricized Tensor Times Khatri-Rao Product on FPGA
Sep 18, 2021



Tensor decomposition has become an essential tool in many applications in various domains, including machine learning. Sparse Matricized Tensor Times Khatri-Rao Product (MTTKRP) is one of the most computationally expensive kernels in tensor computations. Despite having significant computational parallelism, MTTKRP is a challenging kernel to optimize due to its irregular memory access characteristics. This paper focuses on a multi-faceted memory system, which explores the spatial and temporal locality of the data structures of MTTKRP. Further, users can reconfigure our design depending on the behavior of the compute units used in the FPGA accelerator. Our system efficiently accesses all the MTTKRP data structures while reducing the total memory access time, using a distributed cache and Direct Memory Access (DMA) subsystem. Moreover, our work improves the memory access time by 3.5x compared with commercial memory controller IPs. Also, our system shows 2x and 1.26x speedups compared with cache-only and DMA-only memory systems, respectively.
Programmable FPGA-based Memory Controller
Aug 21, 2021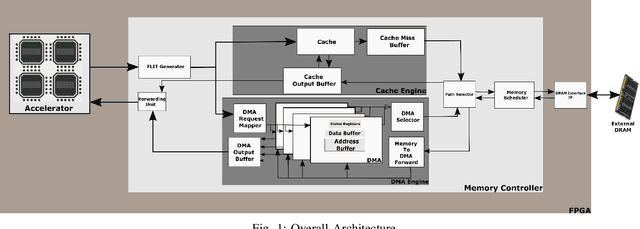

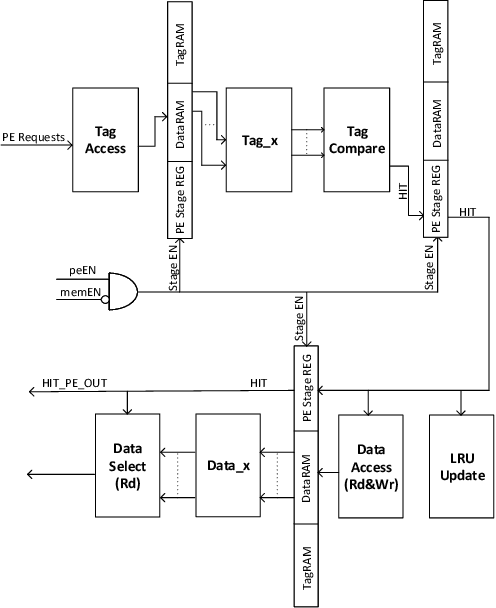
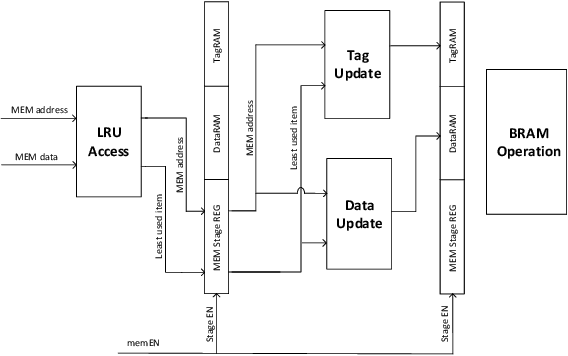
Even with generational improvements in DRAM technology, memory access latency still remains the major bottleneck for application accelerators, primarily due to limitations in memory interface IPs which cannot fully account for variations in target applications, the algorithms used, and accelerator architectures. Since developing memory controllers for different applications is time-consuming, this paper introduces a modular and programmable memory controller that can be configured for different target applications on available hardware resources. The proposed memory controller efficiently supports cache-line accesses along with bulk memory transfers. The user can configure the controller depending on the available logic resources on the FPGA, memory access pattern, and external memory specifications. The modular design supports various memory access optimization techniques including, request scheduling, internal caching, and direct memory access. These techniques contribute to reducing the overall latency while maintaining high sustained bandwidth. We implement the system on a state-of-the-art FPGA and evaluate its performance using two widely studied domains: graph analytics and deep learning workloads. We show improved overall memory access time up to 58% on CNN and GCN workloads compared with commercial memory controller IPs.
Reconfigurable co-processor architecture with limited numerical precision to accelerate deep convolutional neural networks
Aug 21, 2021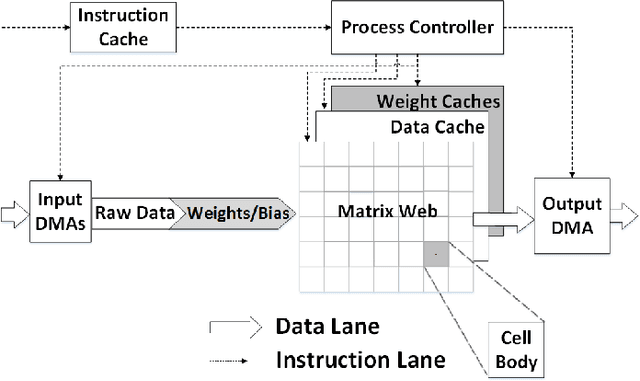
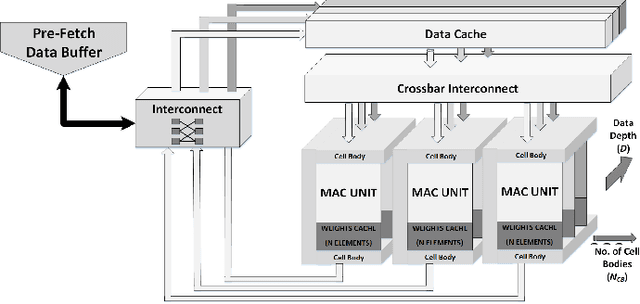
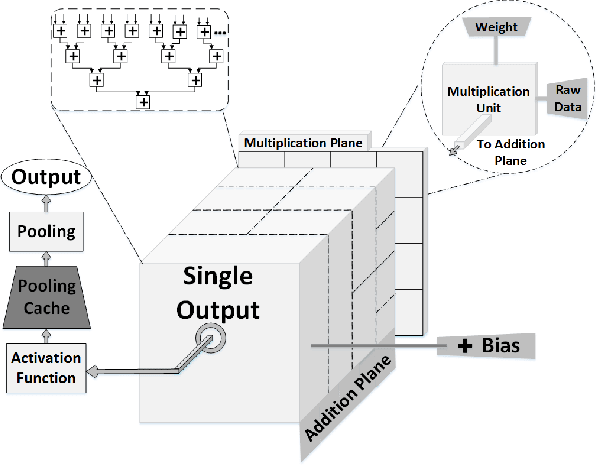

Convolutional Neural Networks (CNNs) are widely used in deep learning applications, e.g. visual systems, robotics etc. However, existing software solutions are not efficient. Therefore, many hardware accelerators have been proposed optimizing performance, power and resource utilization of the implementation. Amongst existing solutions, Field Programmable Gate Array (FPGA) based architecture provides better cost-energy-performance trade-offs as well as scalability and minimizing development time. In this paper, we present a model-independent reconfigurable co-processing architecture to accelerate CNNs. Our architecture consists of parallel Multiply and Accumulate (MAC) units with caching techniques and interconnection networks to exploit maximum data parallelism. In contrast to existing solutions, we introduce limited precision 32 bit Q-format fixed point quantization for arithmetic representations and operations. As a result, our architecture achieved significant reduction in resource utilization with competitive accuracy. Furthermore, we developed an assembly-type microinstructions to access the co-processing fabric to manage layer-wise parallelism, thereby making re-use of limited resources. Finally, we have tested our architecture up to 9x9 kernel size on Xilinx Virtex 7 FPGA, achieving a throughput of up to 226.2 GOp/S for 3x3 kernel size.