 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA
Apr 10, 2024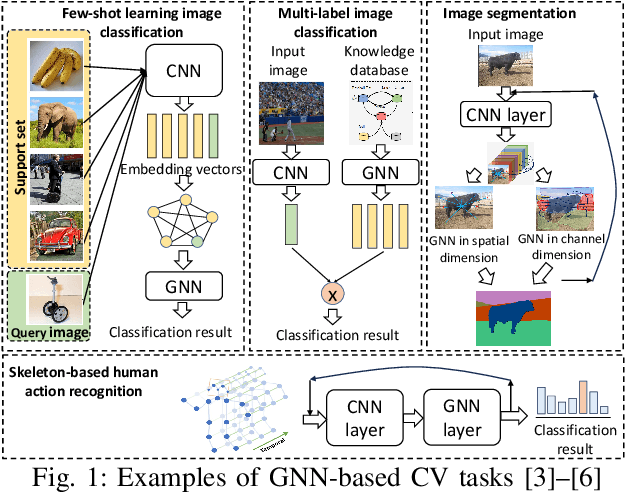
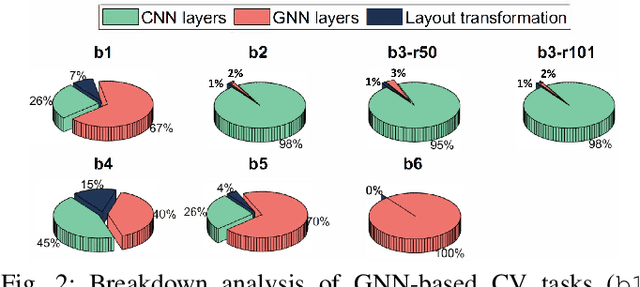
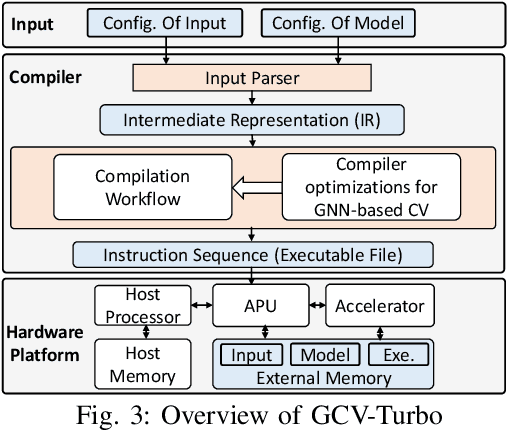
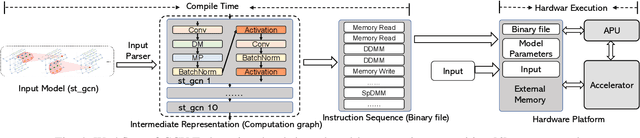
Graph neural networks (GNNs) have recently empowered various novel computer vision (CV) tasks. In GNN-based CV tasks, a combination of CNN layers and GNN layers or only GNN layers are employed. This paper introduces GCV-Turbo, a domain-specific accelerator on FPGA for end-to-end acceleration of GNN-based CV tasks. GCV-Turbo consists of two key components: (1) a \emph{novel} hardware architecture optimized for the computation kernels in both CNNs and GNNs using the same set of computation resources. (2) a PyTorch-compatible compiler that takes a user-defined model as input, performs end-to-end optimization for the computation graph of a given GNN-based CV task, and produces optimized code for hardware execution. The hardware architecture and the compiler work synergistically to support a variety of GNN-based CV tasks. We implement GCV-Turbo on a state-of-the-art FPGA and evaluate its performance across six representative GNN-based CV tasks with diverse input data modalities (e.g., image, human skeleton, point cloud). Compared with state-of-the-art CPU (GPU) implementations, GCV-Turbo achieves an average latency reduction of $68.4\times$ ($4.1\times$) on these six GNN-based CV tasks. Moreover, GCV-Turbo supports the execution of the standalone CNNs or GNNs, achieving performance comparable to that of state-of-the-art CNN (GNN) accelerators for widely used CNN-only (GNN-only) models.
VTR: An Optimized Vision Transformer for SAR ATR Acceleration on FPGA
Apr 06, 2024Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is a key technique used in military applications like remote-sensing image recognition. Vision Transformers (ViTs) are the current state-of-the-art in various computer vision applications, outperforming their CNN counterparts. However, using ViTs for SAR ATR applications is challenging due to (1) standard ViTs require extensive training data to generalize well due to their low locality; the standard SAR datasets, however, have a limited number of labeled training data which reduces the learning capability of ViTs; (2) ViTs have a high parameter count and are computation intensive which makes their deployment on resource-constrained SAR platforms difficult. In this work, we develop a lightweight ViT model that can be trained directly on small datasets without any pre-training by utilizing the Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) modules. We directly train this model on SAR datasets which have limited training samples to evaluate its effectiveness for SAR ATR applications. We evaluate our proposed model, that we call VTR (ViT for SAR ATR), on three widely used SAR datasets: MSTAR, SynthWakeSAR, and GBSAR. Further, we propose a novel FPGA accelerator for VTR, in order to enable deployment for real-time SAR ATR applications.
Accelerating ViT Inference on FPGA through Static and Dynamic Pruning
Mar 21, 2024Vision Transformers (ViTs) have achieved state-of-the-art accuracy on various computer vision tasks. However, their high computational complexity prevents them from being applied to many real-world applications. Weight and token pruning are two well-known methods for reducing complexity: weight pruning reduces the model size and associated computational demands, while token pruning further dynamically reduces the computation based on the input. Combining these two techniques should significantly reduce computation complexity and model size; however, naively integrating them results in irregular computation patterns, leading to significant accuracy drops and difficulties in hardware acceleration. Addressing the above challenges, we propose a comprehensive algorithm-hardware codesign for accelerating ViT on FPGA through simultaneous pruning -combining static weight pruning and dynamic token pruning. For algorithm design, we systematically combine a hardware-aware structured block-pruning method for pruning model parameters and a dynamic token pruning method for removing unimportant token vectors. Moreover, we design a novel training algorithm to recover the model's accuracy. For hardware design, we develop a novel hardware accelerator for executing the pruned model. The proposed hardware design employs multi-level parallelism with load balancing strategy to efficiently deal with the irregular computation pattern led by the two pruning approaches. Moreover, we develop an efficient hardware mechanism for efficiently executing the on-the-fly token pruning.
A Single Graph Convolution Is All You Need: Efficient Grayscale Image Classification
Feb 01, 2024

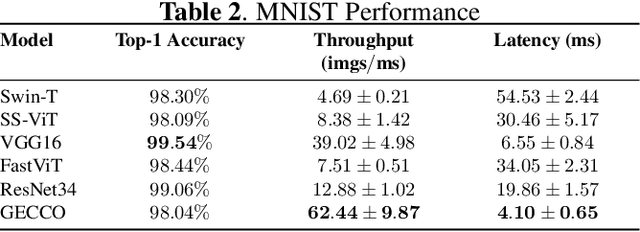

Image classifiers often rely on convolutional neural networks (CNN) for their tasks, which are inherently more heavyweight than multilayer perceptrons (MLPs), which can be problematic in real-time applications. Additionally, many image classification models work on both RGB and grayscale datasets. Classifiers that operate solely on grayscale images are much less common. Grayscale image classification has diverse applications, including but not limited to medical image classification and synthetic aperture radar (SAR) automatic target recognition (ATR). Thus, we present a novel grayscale (single channel) image classification approach using a vectorized view of images. We exploit the lightweightness of MLPs by viewing images as a vector and reducing our problem setting to the grayscale image classification setting. We find that using a single graph convolutional layer batch-wise increases accuracy and reduces variance in the performance of our model. Moreover, we develop a customized accelerator on FPGA for the proposed model with several optimizations to improve its performance. Our experimental results on benchmark grayscale image datasets demonstrate the effectiveness of the proposed model, achieving vastly lower latency (up to 16$\times$ less) and competitive or leading performance compared to other state-of-the-art image classification models on various domain-specific grayscale image classification datasets.
PAHD: Perception-Action based Human Decision Making using Explainable Graph Neural Networks on SAR Images
Jan 05, 2024Synthetic Aperture Radar (SAR) images are commonly utilized in military applications for automatic target recognition (ATR). Machine learning (ML) methods, such as Convolutional Neural Networks (CNN) and Graph Neural Networks (GNN), are frequently used to identify ground-based objects, including battle tanks, personnel carriers, and missile launchers. Determining the vehicle class, such as the BRDM2 tank, BMP2 tank, BTR60 tank, and BTR70 tank, is crucial, as it can help determine whether the target object is an ally or an enemy. While the ML algorithm provides feedback on the recognized target, the final decision is left to the commanding officers. Therefore, providing detailed information alongside the identified target can significantly impact their actions. This detailed information includes the SAR image features that contributed to the classification, the classification confidence, and the probability of the identified object being classified as a different object type or class. We propose a GNN-based ATR framework that provides the final classified class and outputs the detailed information mentioned above. This is the first study to provide a detailed analysis of the classification class, making final decisions more straightforward. Moreover, our GNN framework achieves an overall accuracy of 99.2\% when evaluated on the MSTAR dataset, improving over previous state-of-the-art GNN methods.
Exploiting On-chip Heterogeneity of Versal Architecture for GNN Inference Acceleration
Aug 04, 2023



Graph Neural Networks (GNNs) have revolutionized many Machine Learning (ML) applications, such as social network analysis, bioinformatics, etc. GNN inference can be accelerated by exploiting data sparsity in the input graph, vertex features, and intermediate data in GNN computations. For dynamic sparsity exploitation, we leverage the heterogeneous computing capabilities of AMD Versal ACAP architecture to accelerate GNN inference. We develop a custom hardware module that executes the sparse primitives of the computation kernel on the Programmable Logic (PL) and efficiently computes the dense primitives using the AI Engine (AIE). To exploit data sparsity during inference, we devise a runtime kernel mapping strategy that dynamically assigns computation tasks to the PL and AIE based on data sparsity. Our implementation on the VCK5000 ACAP platform leads to superior performance compared with the state-of-the-art implementations on CPU, GPU, ACAP, and other custom GNN accelerators. Compared with these implementations, we achieve significant average runtime speedup across various models and datasets of 162.42x, 17.01x, 9.90x, and 27.23x, respectively. Furthermore, for Graph Convolutional Network (GCN) inference, our approach leads to a speedup of 3.9-96.7x compared to designs using PL only on the same ACAP device.
Graph Neural Network for Accurate and Low-complexity SAR ATR
May 11, 2023



Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is the key technique for remote sensing image recognition. The state-of-the-art works exploit the deep convolutional neural networks (CNNs) for SAR ATR, leading to high computation costs. These deep CNN models are unsuitable to be deployed on resource-limited platforms. In this work, we propose a graph neural network (GNN) model to achieve accurate and low-latency SAR ATR. We transform the input SAR image into the graph representation. The proposed GNN model consists of a stack of GNN layers that operates on the input graph to perform target classification. Unlike the state-of-the-art CNNs, which need heavy convolution operations, the proposed GNN model has low computation complexity and achieves comparable high accuracy. The GNN-based approach enables our proposed \emph{input pruning} strategy. By filtering out the irrelevant vertices in the input graph, we can reduce the computation complexity. Moreover, we propose the \emph{model pruning} strategy to sparsify the model weight matrices which further reduces the computation complexity. We evaluate the proposed GNN model on the MSTAR dataset and ship discrimination dataset. The evaluation results show that the proposed GNN model achieves 99.38\% and 99.7\% classification accuracy on the above two datasets, respectively. The proposed pruning strategies can prune 98.6\% input vertices and 97\% weight entries with negligible accuracy loss. Compared with the state-of-the-art CNNs, the proposed GNN model has only 1/3000 computation cost and 1/80 model size.
Accurate, Low-latency, Efficient SAR Automatic Target Recognition on FPGA
Jan 04, 2023Synthetic aperture radar (SAR) automatic target recognition (ATR) is the key technique for remote-sensing image recognition. The state-of-the-art convolutional neural networks (CNNs) for SAR ATR suffer from \emph{high computation cost} and \emph{large memory footprint}, making them unsuitable to be deployed on resource-limited platforms, such as small/micro satellites. In this paper, we propose a comprehensive GNN-based model-architecture {co-design} on FPGA to address the above issues. \emph{Model design}: we design a novel graph neural network (GNN) for SAR ATR. The proposed GNN model incorporates GraphSAGE layer operators and attention mechanism, achieving comparable accuracy as the state-of-the-art work with near $1/100$ computation cost. Then, we propose a pruning approach including weight pruning and input pruning. While weight pruning through lasso regression reduces most parameters without accuracy drop, input pruning eliminates most input pixels with negligible accuracy drop. \emph{Architecture design}: to fully unleash the computation parallelism within the proposed model, we develop a novel unified hardware architecture that can execute various computation kernels (feature aggregation, feature transformation, graph pooling). The proposed hardware design adopts the Scatter-Gather paradigm to efficiently handle the irregular computation {patterns} of various computation kernels. We deploy the proposed design on an embedded FPGA (AMD Xilinx ZCU104) and evaluate the performance using MSTAR dataset. Compared with the state-of-the-art CNNs, the proposed GNN achieves comparable accuracy with $1/3258$ computation cost and $1/83$ model size. Compared with the state-of-the-art CPU/GPU, our FPGA accelerator achieves $14.8\times$/$2.5\times$ speedup (latency) and is $62\times$/$39\times$ more energy efficient.
Model-Architecture Co-Design for High Performance Temporal GNN Inference on FPGA
Mar 10, 2022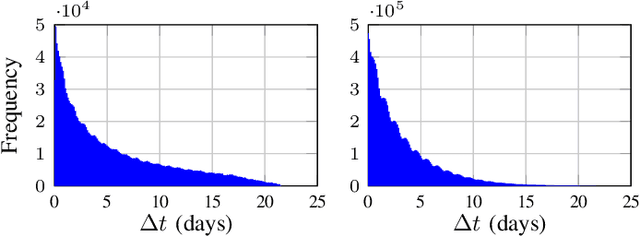
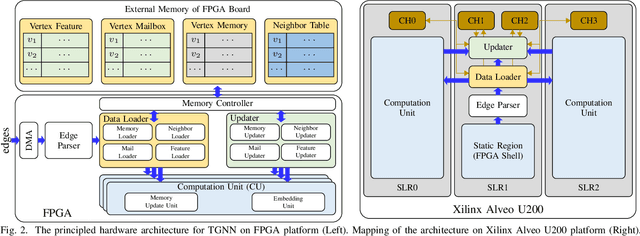
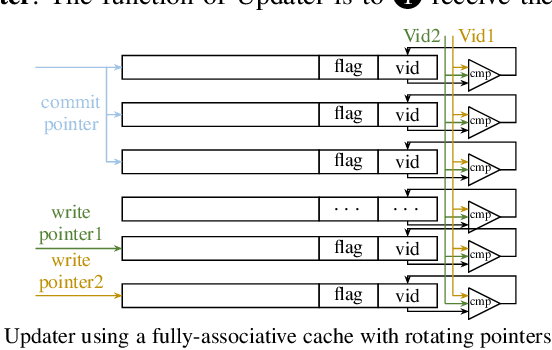
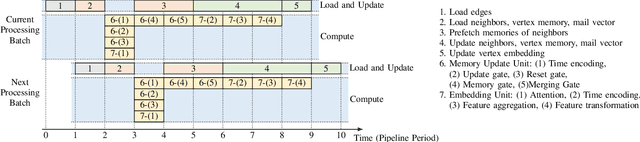
Temporal Graph Neural Networks (TGNNs) are powerful models to capture temporal, structural, and contextual information on temporal graphs. The generated temporal node embeddings outperform other methods in many downstream tasks. Real-world applications require high performance inference on real-time streaming dynamic graphs. However, these models usually rely on complex attention mechanisms to capture relationships between temporal neighbors. In addition, maintaining vertex memory suffers from intrinsic temporal data dependency that hinders task-level parallelism, making it inefficient on general-purpose processors. In this work, we present a novel model-architecture co-design for inference in memory-based TGNNs on FPGAs. The key modeling optimizations we propose include a light-weight method to compute attention scores and a related temporal neighbor pruning strategy to further reduce computation and memory accesses. These are holistically coupled with key hardware optimizations that leverage FPGA hardware. We replace the temporal sampler with an on-chip FIFO based hardware sampler and the time encoder with a look-up-table. We train our simplified models using knowledge distillation to ensure similar accuracy vis-\'a-vis the original model. Taking advantage of the model optimizations, we propose a principled hardware architecture using batching, pipelining, and prefetching techniques to further improve the performance. We also propose a hardware mechanism to ensure the chronological vertex updating without sacrificing the computation parallelism. We evaluate the performance of the proposed hardware accelerator on three real-world datasets.