 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA
Paper and Code
Apr 10, 2024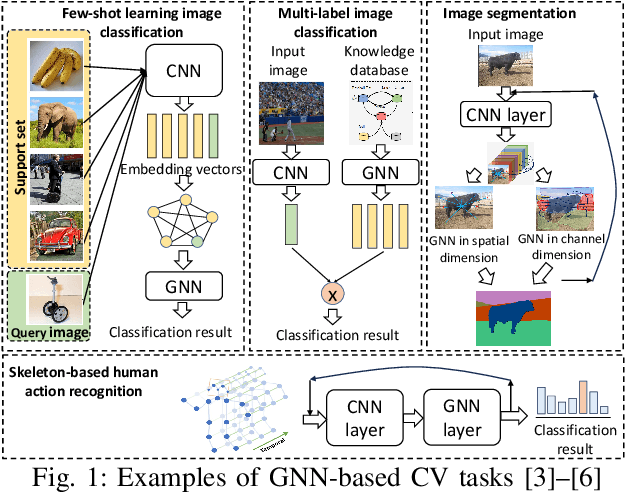
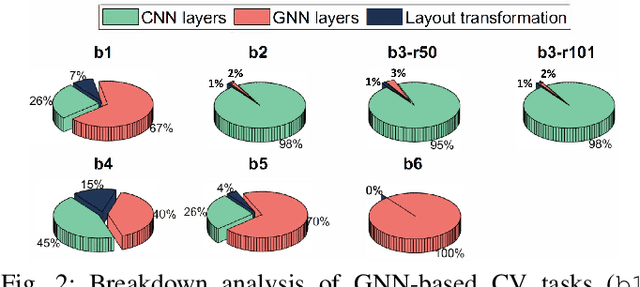
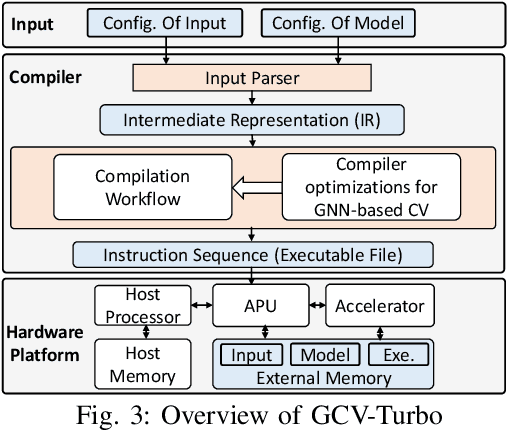
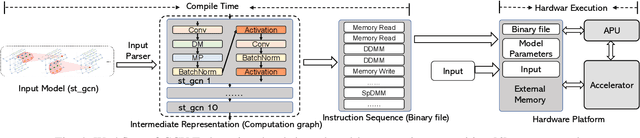
Graph neural networks (GNNs) have recently empowered various novel computer vision (CV) tasks. In GNN-based CV tasks, a combination of CNN layers and GNN layers or only GNN layers are employed. This paper introduces GCV-Turbo, a domain-specific accelerator on FPGA for end-to-end acceleration of GNN-based CV tasks. GCV-Turbo consists of two key components: (1) a \emph{novel} hardware architecture optimized for the computation kernels in both CNNs and GNNs using the same set of computation resources. (2) a PyTorch-compatible compiler that takes a user-defined model as input, performs end-to-end optimization for the computation graph of a given GNN-based CV task, and produces optimized code for hardware execution. The hardware architecture and the compiler work synergistically to support a variety of GNN-based CV tasks. We implement GCV-Turbo on a state-of-the-art FPGA and evaluate its performance across six representative GNN-based CV tasks with diverse input data modalities (e.g., image, human skeleton, point cloud). Compared with state-of-the-art CPU (GPU) implementations, GCV-Turbo achieves an average latency reduction of $68.4\times$ ($4.1\times$) on these six GNN-based CV tasks. Moreover, GCV-Turbo supports the execution of the standalone CNNs or GNNs, achieving performance comparable to that of state-of-the-art CNN (GNN) accelerators for widely used CNN-only (GNN-only) models.