 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOHORT: Hybrid RL for Collaborative Large DNN Inference on Multi-Robot Systems Under Real-Time Constraints
Mar 11, 2026Large deep neural networks (DNNs), especially transformer-based and multimodal architectures, are computationally demanding and challenging to deploy on resource-constrained edge platforms like field robots. These challenges intensify in mission-critical scenarios (e.g., disaster response), where robots must collaborate under tight constraints on bandwidth, latency, and battery life, often without infrastructure or server support. To address these limitations, we present COHORT, a collaborative DNN inference and task-execution framework for multi-robot systems built on the Robotic Operating System (ROS). COHORT employs a hybrid offline-online reinforcement learning (RL) strategy to dynamically schedule and distribute DNN module execution across robots. Our key contributions are threefold: (a) Offline RL policy learning combined with Advantage-Weighted Regression (AWR), trained on auction-based task allocation data from heterogeneous DNN workloads across distributed robots, (b) Online policy adaptation via Multi-Agent PPO (MAPPO), initialized from the offline policy and fine-tuned in real time, and (c) comprehensive evaluation of COHORT on vision-language model (VLM) inference tasks such as CLIP and SAM, analyzing scalability with increasing robot/workload and robustness under . We benchmark COHORT against genetic algorithms and multiple RL baselines. Experimental results demonstrate that COHORT reduces battery consumption by 15.4% and increases GPU utilization by 51.67%, while satisfying frame-rate and deadline constraints 2.55 times of the time.
Data-Driven Distributed Common Operational Picture from Heterogeneous Platforms using Multi-Agent Reinforcement Learning
Nov 08, 2024



The integration of unmanned platforms equipped with advanced sensors promises to enhance situational awareness and mitigate the "fog of war" in military operations. However, managing the vast influx of data from these platforms poses a significant challenge for Command and Control (C2) systems. This study presents a novel multi-agent learning framework to address this challenge. Our method enables autonomous and secure communication between agents and humans, which in turn enables real-time formation of an interpretable Common Operational Picture (COP). Each agent encodes its perceptions and actions into compact vectors, which are then transmitted, received and decoded to form a COP encompassing the current state of all agents (friendly and enemy) on the battlefield. Using Deep Reinforcement Learning (DRL), we jointly train COP models and agent's action selection policies. We demonstrate resilience to degraded conditions such as denied GPS and disrupted communications. Experimental validation is performed in the Starcraft-2 simulation environment to evaluate the precision of the COPs and robustness of policies. We report less than 5% error in COPs and policies resilient to various adversarial conditions. In summary, our contributions include a method for autonomous COP formation, increased resilience through distributed prediction, and joint training of COP models and multi-agent RL policies. This research advances adaptive and resilient C2, facilitating effective control of heterogeneous unmanned platforms.
SERN: Simulation-Enhanced Realistic Navigation for Multi-Agent Robotic Systems in Contested Environments
Oct 22, 2024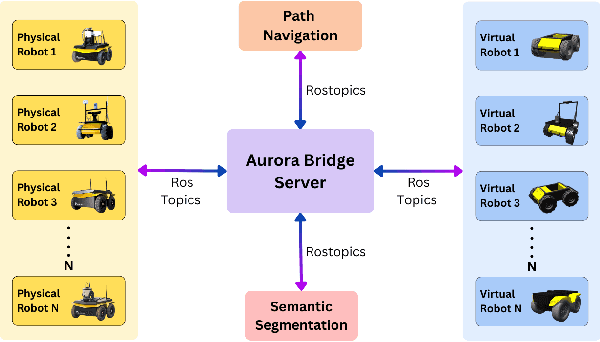
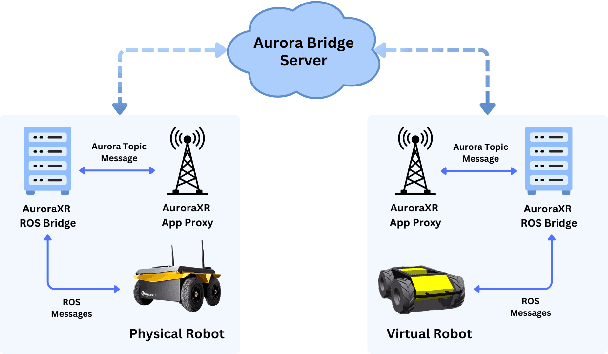
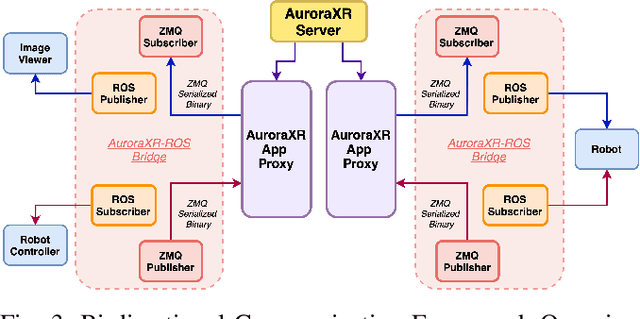
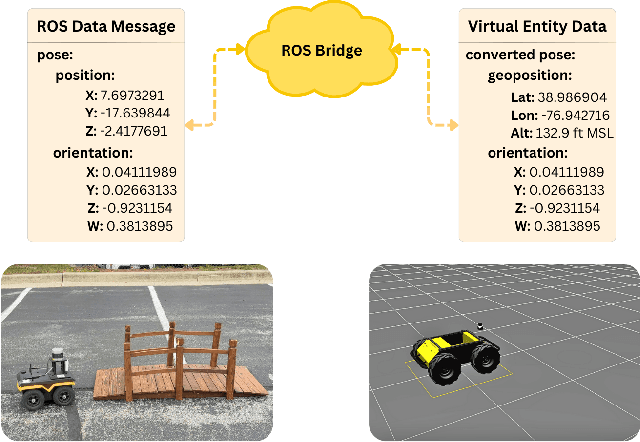
The increasing deployment of autonomous systems in complex environments necessitates efficient communication and task completion among multiple agents. This paper presents SERN (Simulation-Enhanced Realistic Navigation), a novel framework integrating virtual and physical environments for real-time collaborative decision-making in multi-robot systems. SERN addresses key challenges in asset deployment and coordination through a bi-directional communication framework using the AuroraXR ROS Bridge. Our approach advances the SOTA through accurate real-world representation in virtual environments using Unity high-fidelity simulator; synchronization of physical and virtual robot movements; efficient ROS data distribution between remote locations; and integration of SOTA semantic segmentation for enhanced environmental perception. Our evaluations show a 15% to 24% improvement in latency and up to a 15% increase in processing efficiency compared to traditional ROS setups. Real-world and virtual simulation experiments with multiple robots demonstrate synchronization accuracy, achieving less than 5 cm positional error and under 2-degree rotational error. These results highlight SERN's potential to enhance situational awareness and multi-agent coordination in diverse, contested environments.
GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA
Apr 10, 2024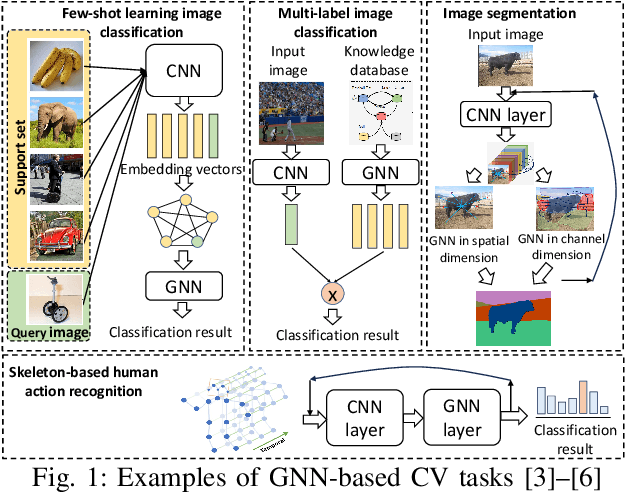
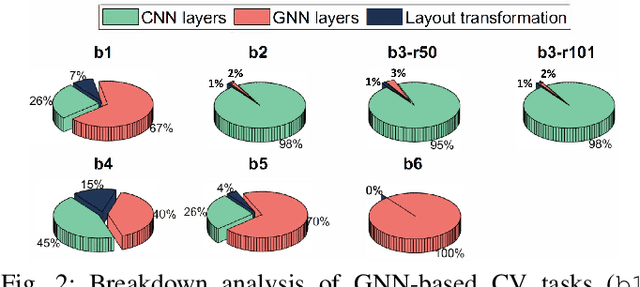
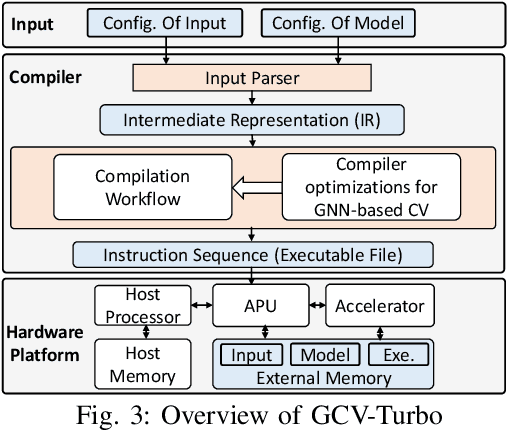
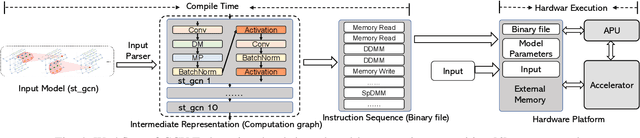
Graph neural networks (GNNs) have recently empowered various novel computer vision (CV) tasks. In GNN-based CV tasks, a combination of CNN layers and GNN layers or only GNN layers are employed. This paper introduces GCV-Turbo, a domain-specific accelerator on FPGA for end-to-end acceleration of GNN-based CV tasks. GCV-Turbo consists of two key components: (1) a \emph{novel} hardware architecture optimized for the computation kernels in both CNNs and GNNs using the same set of computation resources. (2) a PyTorch-compatible compiler that takes a user-defined model as input, performs end-to-end optimization for the computation graph of a given GNN-based CV task, and produces optimized code for hardware execution. The hardware architecture and the compiler work synergistically to support a variety of GNN-based CV tasks. We implement GCV-Turbo on a state-of-the-art FPGA and evaluate its performance across six representative GNN-based CV tasks with diverse input data modalities (e.g., image, human skeleton, point cloud). Compared with state-of-the-art CPU (GPU) implementations, GCV-Turbo achieves an average latency reduction of $68.4\times$ ($4.1\times$) on these six GNN-based CV tasks. Moreover, GCV-Turbo supports the execution of the standalone CNNs or GNNs, achieving performance comparable to that of state-of-the-art CNN (GNN) accelerators for widely used CNN-only (GNN-only) models.
VTR: An Optimized Vision Transformer for SAR ATR Acceleration on FPGA
Apr 06, 2024Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is a key technique used in military applications like remote-sensing image recognition. Vision Transformers (ViTs) are the current state-of-the-art in various computer vision applications, outperforming their CNN counterparts. However, using ViTs for SAR ATR applications is challenging due to (1) standard ViTs require extensive training data to generalize well due to their low locality; the standard SAR datasets, however, have a limited number of labeled training data which reduces the learning capability of ViTs; (2) ViTs have a high parameter count and are computation intensive which makes their deployment on resource-constrained SAR platforms difficult. In this work, we develop a lightweight ViT model that can be trained directly on small datasets without any pre-training by utilizing the Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) modules. We directly train this model on SAR datasets which have limited training samples to evaluate its effectiveness for SAR ATR applications. We evaluate our proposed model, that we call VTR (ViT for SAR ATR), on three widely used SAR datasets: MSTAR, SynthWakeSAR, and GBSAR. Further, we propose a novel FPGA accelerator for VTR, in order to enable deployment for real-time SAR ATR applications.
Uncertainty-Aware SAR ATR: Defending Against Adversarial Attacks via Bayesian Neural Networks
Mar 27, 2024Adversarial attacks have demonstrated the vulnerability of Machine Learning (ML) image classifiers in Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) systems. An adversarial attack can deceive the classifier into making incorrect predictions by perturbing the input SAR images, for example, with a few scatterers attached to the on-ground objects. Therefore, it is critical to develop robust SAR ATR systems that can detect potential adversarial attacks by leveraging the inherent uncertainty in ML classifiers, thereby effectively alerting human decision-makers. In this paper, we propose a novel uncertainty-aware SAR ATR for detecting adversarial attacks. Specifically, we leverage the capability of Bayesian Neural Networks (BNNs) in performing image classification with quantified epistemic uncertainty to measure the confidence for each input SAR image. By evaluating the uncertainty, our method alerts when the input SAR image is likely to be adversarially generated. Simultaneously, we also generate visual explanations that reveal the specific regions in the SAR image where the adversarial scatterers are likely to to be present, thus aiding human decision-making with hints of evidence of adversarial attacks. Experiments on the MSTAR dataset demonstrate that our approach can identify over 80% adversarial SAR images with fewer than 20% false alarms, and our visual explanations can identify up to over 90% of scatterers in an adversarial SAR image.
Accelerating ViT Inference on FPGA through Static and Dynamic Pruning
Mar 21, 2024Vision Transformers (ViTs) have achieved state-of-the-art accuracy on various computer vision tasks. However, their high computational complexity prevents them from being applied to many real-world applications. Weight and token pruning are two well-known methods for reducing complexity: weight pruning reduces the model size and associated computational demands, while token pruning further dynamically reduces the computation based on the input. Combining these two techniques should significantly reduce computation complexity and model size; however, naively integrating them results in irregular computation patterns, leading to significant accuracy drops and difficulties in hardware acceleration. Addressing the above challenges, we propose a comprehensive algorithm-hardware codesign for accelerating ViT on FPGA through simultaneous pruning -combining static weight pruning and dynamic token pruning. For algorithm design, we systematically combine a hardware-aware structured block-pruning method for pruning model parameters and a dynamic token pruning method for removing unimportant token vectors. Moreover, we design a novel training algorithm to recover the model's accuracy. For hardware design, we develop a novel hardware accelerator for executing the pruned model. The proposed hardware design employs multi-level parallelism with load balancing strategy to efficiently deal with the irregular computation pattern led by the two pruning approaches. Moreover, we develop an efficient hardware mechanism for efficiently executing the on-the-fly token pruning.
Beyond Joint Demonstrations: Personalized Expert Guidance for Efficient Multi-Agent Reinforcement Learning
Mar 13, 2024



Multi-Agent Reinforcement Learning (MARL) algorithms face the challenge of efficient exploration due to the exponential increase in the size of the joint state-action space. While demonstration-guided learning has proven beneficial in single-agent settings, its direct applicability to MARL is hindered by the practical difficulty of obtaining joint expert demonstrations. In this work, we introduce a novel concept of personalized expert demonstrations, tailored for each individual agent or, more broadly, each individual type of agent within a heterogeneous team. These demonstrations solely pertain to single-agent behaviors and how each agent can achieve personal goals without encompassing any cooperative elements, thus naively imitating them will not achieve cooperation due to potential conflicts. To this end, we propose an approach that selectively utilizes personalized expert demonstrations as guidance and allows agents to learn to cooperate, namely personalized expert-guided MARL (PegMARL). This algorithm utilizes two discriminators: the first provides incentives based on the alignment of policy behavior with demonstrations, and the second regulates incentives based on whether the behavior leads to the desired objective. We evaluate PegMARL using personalized demonstrations in both discrete and continuous environments. The results demonstrate that PegMARL learns near-optimal policies even when provided with suboptimal demonstrations, and outperforms state-of-the-art MARL algorithms in solving coordinated tasks. We also showcase PegMARL's capability to leverage joint demonstrations in the StarCraft scenario and converge effectively even with demonstrations from non-co-trained policies.
PAHD: Perception-Action based Human Decision Making using Explainable Graph Neural Networks on SAR Images
Jan 05, 2024Synthetic Aperture Radar (SAR) images are commonly utilized in military applications for automatic target recognition (ATR). Machine learning (ML) methods, such as Convolutional Neural Networks (CNN) and Graph Neural Networks (GNN), are frequently used to identify ground-based objects, including battle tanks, personnel carriers, and missile launchers. Determining the vehicle class, such as the BRDM2 tank, BMP2 tank, BTR60 tank, and BTR70 tank, is crucial, as it can help determine whether the target object is an ally or an enemy. While the ML algorithm provides feedback on the recognized target, the final decision is left to the commanding officers. Therefore, providing detailed information alongside the identified target can significantly impact their actions. This detailed information includes the SAR image features that contributed to the classification, the classification confidence, and the probability of the identified object being classified as a different object type or class. We propose a GNN-based ATR framework that provides the final classified class and outputs the detailed information mentioned above. This is the first study to provide a detailed analysis of the classification class, making final decisions more straightforward. Moreover, our GNN framework achieves an overall accuracy of 99.2\% when evaluated on the MSTAR dataset, improving over previous state-of-the-art GNN methods.
Benchmarking Deep Learning Classifiers for SAR Automatic Target Recognition
Dec 12, 2023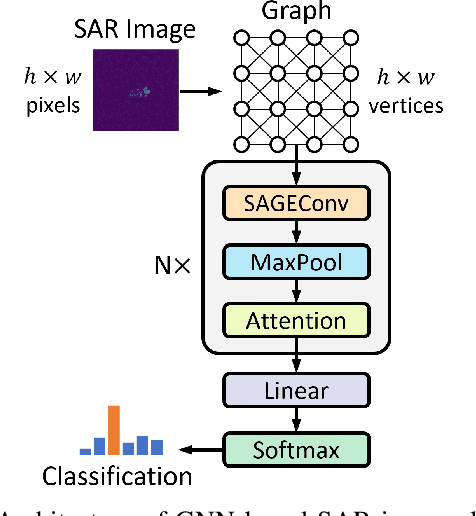
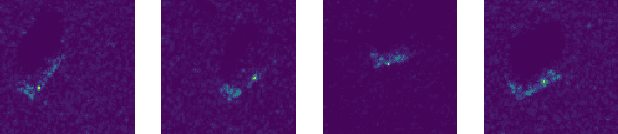

Synthetic Aperture Radar SAR Automatic Target Recognition ATR is a key technique of remote-sensing image recognition which can be supported by deep neural networks The existing works of SAR ATR mostly focus on improving the accuracy of the target recognition while ignoring the systems performance in terms of speed and storage which is critical to real-world applications of SAR ATR For decision-makers aiming to identify a proper deep learning model to deploy in a SAR ATR system it is important to understand the performance of different candidate deep learning models and determine the best model accordingly This paper comprehensively benchmarks several advanced deep learning models for SAR ATR with multiple distinct SAR imagery datasets Specifically we train and test five SAR image classifiers based on Residual Neural Networks ResNet18 ResNet34 ResNet50 Graph Neural Network GNN and Vision Transformer for Small-Sized Datasets (SS-ViT) We select three datasets MSTAR GBSAR and SynthWakeSAR that offer heterogeneity We evaluate and compare the five classifiers concerning their classification accuracy runtime performance in terms of inference throughput and analytical performance in terms of number of parameters number of layers model size and number of operations Experimental results show that the GNN classifier outperforms with respect to throughput and latency However it is also shown that no clear model winner emerges from all of our chosen metrics and a one model rules all case is doubtful in the domain of SAR ATR