 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Rich Feedback with Distributional DAgger
Jun 03, 2026Reasoning models have advanced rapidly, but the dominant reinforcement learning from verifiable rewards (RLVR) recipe remains surprisingly narrow: sample many responses and reward each with a single bit indicating whether the final answer is correct. Yet many settings provide rich feedback, including execution traces, tool outputs, expert corrections, and model self-evaluations. We study how to use such feedback through a distributional variant of the classic imitation learning algorithm DAgger, where the learner has local access to an expert distribution on states visited by the current policy. This yields a simple forward cross-entropy objective that admits a blackbox expert and whose sequence-level gradient {conduct rich credit assignment by propagating} future expert-student disagreement back to earlier decisions. We show that prior RL with self-distillation objectives based on reverse KL or Jensen-Shannon fail to guarantee monotonic policy improvement: even when the expert has higher reward, their updates may increase probability on worse actions. In contrast, we show that forward cross-entropy admits monotonic policy improvement and enjoys guarantees on regret. We further show that our objective optimizes a lower bound on teacher-weighted likelihood of success, leading to improved Pass@N. Empirically, our approach, DistIL, improves over RLVR and RL with self-distillation baselines across a variety of domains: scientific reasoning, coding, and solving hard mathematical problems.
Solve the Loop: Attractor Models for Language and Reasoning
May 12, 2026Looped Transformers offer a promising alternative to purely feed-forward computation by iteratively refining latent representations, improving language modeling and reasoning. Yet recurrent architectures remain unstable to train, costly to optimize and deploy, and constrained to small, fixed recurrence depths. We introduce Attractor Models, in which a backbone module first proposes output embeddings, then an attractor module refines them by solving for the fixed point, with gradients obtained through implicit differentiation. Thus, training memory remains constant in effective depth, and iterations are chosen adaptively by convergence. Empirically, Attractor Models outperform existing models across two regimes, large-scale language-model pretraining and reasoning with tiny models. In language modeling, Attractor Models deliver a Pareto improvement over standard Transformers and stable looped models across sizes, improving perplexity by up to 46.6% and downstream accuracy by up to 19.7% while reducing training cost. Notably, a 770M Attractor Model outperforms a 1.3B Transformer trained on twice as many tokens. On challenging reasoning tasks, we show that our model with only 27M parameters and approximately 1000 examples achieves 91.4% accuracy on Sudoku-Extreme and 93.1% on Maze-Hard, scaling favorably where frontier models like Claude and GPT o3, fail completely, and specialized recursive reasoners collapse at larger sizes. Lastly, we show that Attractor Models exhibit a novel phenomenon, which we call equilibrium internalization: fixed-point training places the model's initial output embedding near equilibrium, allowing the solver to be removed at inference time with little degradation. Together, these results suggest that Attractor Models make iterative refinement scalable by turning recurrence into a computation the model can learn to internalize.
Latent Denoising Improves Visual Alignment in Large Multimodal Models
Apr 23, 2026Large Multimodal Models (LMMs) such as LLaVA are typically trained with an autoregressive language modeling objective, providing only indirect supervision to visual tokens. This often yields weak internal visual representations and brittle behavior under distribution shift. Inspired by recent progress on latent denoising for learning high-quality visual tokenizers, we show that the same principle provides an effective form of visual supervision for improving internal visual feature alignment and multimodal understanding in LMMs. We propose a latent denoising framework that corrupts projected visual tokens using a saliency-aware mixture of masking and Gaussian noising. The LMM is trained to denoise these corrupted tokens by recovering clean teacher patch features from hidden states at a selected intermediate LLM layer using a decoder. To prevent representation collapse, our framework also preserves the teacher's intra-image similarity structure and applies intra-image contrastive patch distillation. During inference, corruption and auxiliary heads are disabled, introducing no additional inference-time overhead. Across a broad suite of standard multimodal benchmarks, our method consistently improves visual understanding and reasoning over strong baselines, and yields clear gains on compositional robustness benchmarks (e.g., NaturalBench). Moreover, under ImageNet-C-style non-adversarial common corruptions applied to benchmark images, our method maintains higher accuracy and exhibits reduced degradation at both moderate and severe corruption levels. Our code is available at https://github.com/dhruvashp/latent-denoising-for-lmms.
Bridging Hidden States in Vision-Language Models
Nov 14, 2025Vision-Language Models (VLMs) are a new family of models that align image content with natural language. Existing approaches typically fuse either (a) early: by mixing tokens/features inside the encoders, or (b) late: by comparing pooled embeddings. Many methods also tie fusion to an autoregressive decoder. However, the hidden states of both modalities already carry rich, modality-specific structure (spatial layout in vision; syntax and semantics in text), so directly aligning these states is a natural way to match what the two modalities "think". We propose a lightweight fusion module: a few cross-only, bidirectional attention layers placed near the top of both encoders. Each layer projects the vision and text encoder hidden-state sequences into a shared space, attends across modalities, and sends gated residual updates back, with simple stabilizers to improve alignment. The encoders remain non-causal and strong for understanding, while generation stays cleanly decoupled via an optional decoder. Across standard retrieval, VQA, and visual reasoning benchmarks, BRIDGE outperforms comparable VLMs while preserving the bi-encoder efficiency of contrastive models. We make our code publicly available at https://github.com/jfeinashley/BRIDGE.
The FFT Strikes Back: An Efficient Alternative to Self-Attention
Feb 26, 2025Conventional self-attention mechanisms incur quadratic complexity, limiting their scalability on long sequences. We introduce FFTNet, an adaptive spectral filtering framework that leverages the Fast Fourier Transform (FFT) to achieve global token mixing in $\mathcal{O}(n\log n)$ time. By transforming inputs into the frequency domain, FFTNet exploits the orthogonality and energy preservation guaranteed by Parseval's theorem to capture long-range dependencies efficiently. A learnable spectral filter and modReLU activation dynamically emphasize salient frequency components, providing a rigorous and adaptive alternative to traditional self-attention. Experiments on the Long Range Arena and ImageNet benchmarks validate our theoretical insights and demonstrate superior performance over fixed Fourier and standard attention models.
Linear Diffusion Networks: Harnessing Diffusion Processes for Global Interactions
Feb 19, 2025Diffusion kernels capture global dependencies. We present Linear Diffusion Networks (LDNs), a novel architecture that reinterprets sequential data processing as a unified diffusion process. Our model integrates adaptive diffusion modules with localized nonlinear updates and a diffusion-inspired attention mechanism. This design enables efficient global information propagation while preserving fine-grained temporal details. LDN overcomes the limitations of conventional recurrent and transformer models by allowing full parallelization across time steps and supporting robust multi-scale temporal representations. Experiments on benchmark sequence modeling tasks demonstrate that LDN delivers superior performance and scalability, setting a new standard for global interaction in sequential data.
Flowing Through Layers: A Continuous Dynamical Systems Perspective on Transformers
Feb 08, 2025We show that the standard discrete update rule of transformer layers can be naturally interpreted as a forward Euler discretization of a continuous dynamical system. Our Transformer Flow Approximation Theorem demonstrates that, under standard Lipschitz continuity assumptions, token representations converge uniformly to the unique solution of an ODE as the number of layers grows. Moreover, if the underlying mapping satisfies a one-sided Lipschitz condition with a negative constant, the resulting dynamics are contractive, causing perturbations to decay exponentially across layers. Beyond clarifying the empirical stability and expressivity of transformer models, these insights link transformer updates to a broader iterative reasoning framework, suggesting new avenues for accelerated convergence and architectural innovations inspired by dynamical systems theory.
Iterate to Accelerate: A Unified Framework for Iterative Reasoning and Feedback Convergence
Feb 06, 2025We introduce a unified framework for iterative reasoning that leverages non-Euclidean geometry via Bregman divergences, higher-order operator averaging, and adaptive feedback mechanisms. Our analysis establishes that, under mild smoothness and contractivity assumptions, a generalized update scheme not only unifies classical methods such as mirror descent and dynamic programming but also captures modern chain-of-thought reasoning processes in large language models. In particular, we prove that our accelerated iterative update achieves an $O(1/t^2)$ convergence rate in the absence of persistent perturbations, and we further demonstrate that feedback (iterative) architectures are necessary to approximate certain fixed-point functions efficiently. These theoretical insights bridge classical acceleration techniques with contemporary applications in neural computation and optimization.
ClusterViG: Efficient Globally Aware Vision GNNs via Image Partitioning
Jan 18, 2025


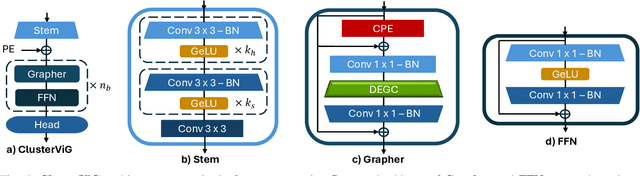
Convolutional Neural Networks (CNN) and Vision Transformers (ViT) have dominated the field of Computer Vision (CV). Graph Neural Networks (GNN) have performed remarkably well across diverse domains because they can represent complex relationships via unstructured graphs. However, the applicability of GNNs for visual tasks was unexplored till the introduction of Vision GNNs (ViG). Despite the success of ViGs, their performance is severely bottlenecked due to the expensive $k$-Nearest Neighbors ($k$-NN) based graph construction. Recent works addressing this bottleneck impose constraints on the flexibility of GNNs to build unstructured graphs, undermining their core advantage while introducing additional inefficiencies. To address these issues, in this paper, we propose a novel method called Dynamic Efficient Graph Convolution (DEGC) for designing efficient and globally aware ViGs. DEGC partitions the input image and constructs graphs in parallel for each partition, improving graph construction efficiency. Further, DEGC integrates local intra-graph and global inter-graph feature learning, enabling enhanced global context awareness. Using DEGC as a building block, we propose a novel CNN-GNN architecture, ClusterViG, for CV tasks. Extensive experiments indicate that ClusterViG reduces end-to-end inference latency for vision tasks by up to $5\times$ when compared against a suite of models such as ViG, ViHGNN, PVG, and GreedyViG, with a similar model parameter count. Additionally, ClusterViG reaches state-of-the-art performance on image classification, object detection, and instance segmentation tasks, demonstrating the effectiveness of the proposed globally aware learning strategy. Finally, input partitioning performed by DEGC enables ClusterViG to be trained efficiently on higher-resolution images, underscoring the scalability of our approach.
Contextual Feedback Loops: Amplifying Deep Reasoning with Iterative Top-Down Feedback
Dec 28, 2024



Deep neural networks typically rely on a single forward pass for inference, which can limit their capacity to resolve ambiguous inputs. We introduce Contextual Feedback Loops (CFLs) as an iterative mechanism that incorporates top-down feedback to refine intermediate representations, thereby improving accuracy and robustness. This repeated process mirrors how humans continuously re-interpret sensory information in daily life-by checking and re-checking our perceptions using contextual cues. Our results suggest that CFLs can offer a straightforward yet powerful way to incorporate such contextual reasoning in modern deep learning architectures.