 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphLeap: Decoupling Graph Construction and Convolution for Vision GNN Acceleration on FPGA
Apr 23, 2026Vision Graph Neural Networks (ViGs) represent an image as a graph of patch tokens, enabling adaptive, feature-driven neighborhoods. Unlike CNNs with fixed grid biases or Vision Transformers with global token interactions, ViGs rely on dynamic graph convolution: at each layer, a feature-dependent graph is built via k-nearest-neighbor (kNN) search on current patch features, followed by message passing. This per-layer graph construction is the main bottleneck, consuming 50--95\% of graph convolution time on CPUs and GPUs, scaling as $O(N^2)$ with the number of patches $N$, and creating a sequential dependency between graph construction and feature updates. We introduce GraphLeap, a simple reformulation that removes this dependency by decoupling graph construction from feature update across layers. GraphLeap performs the feature update at layer $\ell$ using a graph built from the previous layer's features, while simultaneously using the current layer's features to construct the graph for layer $\ell+1$. This one-layer-lookahead graph construction enables concurrent graph construction and message passing. Although using prior-layer features can introduce minor accuracy degradation, lightweight fine-tuning for a few epochs is sufficient to recover the original accuracy. Building on GraphLeap, we present the first end-to-end FPGA accelerator for Vision GNNs. Our streaming, layer-pipelined design overlaps a kNN graph construction engine with a feature update engine, exploits node- and channel-level parallelism, and enables efficient on-chip dataflow without explicit edge-feature materialization. Evaluated on isotropic and pyramidal ViG models on an Alveo U280 FPGA, GraphLeap achieves up to $95.7\times$ speedup over CPU and $8.5\times$ speedup over GPU baselines, demonstrating the feasibility of real-time Vision GNN inference.
Latent Denoising Improves Visual Alignment in Large Multimodal Models
Apr 23, 2026Large Multimodal Models (LMMs) such as LLaVA are typically trained with an autoregressive language modeling objective, providing only indirect supervision to visual tokens. This often yields weak internal visual representations and brittle behavior under distribution shift. Inspired by recent progress on latent denoising for learning high-quality visual tokenizers, we show that the same principle provides an effective form of visual supervision for improving internal visual feature alignment and multimodal understanding in LMMs. We propose a latent denoising framework that corrupts projected visual tokens using a saliency-aware mixture of masking and Gaussian noising. The LMM is trained to denoise these corrupted tokens by recovering clean teacher patch features from hidden states at a selected intermediate LLM layer using a decoder. To prevent representation collapse, our framework also preserves the teacher's intra-image similarity structure and applies intra-image contrastive patch distillation. During inference, corruption and auxiliary heads are disabled, introducing no additional inference-time overhead. Across a broad suite of standard multimodal benchmarks, our method consistently improves visual understanding and reasoning over strong baselines, and yields clear gains on compositional robustness benchmarks (e.g., NaturalBench). Moreover, under ImageNet-C-style non-adversarial common corruptions applied to benchmark images, our method maintains higher accuracy and exhibits reduced degradation at both moderate and severe corruption levels. Our code is available at https://github.com/dhruvashp/latent-denoising-for-lmms.
ImageHD: Energy-Efficient On-Device Continual Learning of Visual Representations via Hyperdimensional Computing
Apr 23, 2026On-device continual learning (CL) is critical for edge AI systems operating on non-stationary data streams, but most existing methods rely on backpropagation or exemplar-heavy classifiers, incurring substantial compute, memory, and latency overheads. Hyperdimensional computing (HDC) offers a lightweight alternative through fast, non-iterative online updates. Combined with a compact convolutional neural network (CNN) feature extractor, HDC enables efficient on-device adaptation with strong visual representations. However, prior HDC-based CL systems often depend on multi-tier memory hierarchies and complex cluster management, limiting deployability on resource-constrained hardware. We present ImageHD, an FPGA accelerator for on-device continual learning of visual data based on HDC. ImageHD targets streaming CL under strict latency and on-chip memory constraints, avoiding costly iterative optimization. At the algorithmic level, we introduce a hardware-aware CL method that bounds class exemplars through a unified exemplar memory and a hardware-efficient cluster merging strategy, while incorporating a quantized CNN front-end to reduce deployment overhead without sacrificing accuracy. At the system level, ImageHD is implemented as a streaming dataflow architecture on the AMD Zynq ZCU104 FPGA, integrating HDC encoding, similarity search, and bounded cluster management using word-packed binary hypervectors for massively parallel bitwise computation within tight on-chip resource budgets. On CORe50, ImageHD achieves up to 40.4x (4.84x) speedup and 383x (105.1x) energy efficiency over optimized CPU (GPU) baselines, demonstrating the practicality of HDC-enabled continual learning for real-time edge AI.
EvoClaw: Evaluating AI Agents on Continuous Software Evolution
Mar 13, 2026With AI agents increasingly deployed as long-running systems, it becomes essential to autonomously construct and continuously evolve customized software to enable interaction within dynamic environments. Yet, existing benchmarks evaluate agents on isolated, one-off coding tasks, neglecting the temporal dependencies and technical debt inherent in real-world software evolution. To bridge this gap, we introduce DeepCommit, an agentic pipeline that reconstructs verifiable Milestone DAGs from noisy commit logs, where milestones are defined as semantically cohesive development goals. These executable sequences enable EvoClaw, a novel benchmark that requires agents to sustain system integrity and limit error accumulation, dimensions of long-term software evolution largely missing from current benchmarks. Our evaluation of 12 frontier models across 4 agent frameworks reveals a critical vulnerability: overall performance scores drop significantly from $>$80% on isolated tasks to at most 38% in continuous settings, exposing agents' profound struggle with long-term maintenance and error propagation.
ConsensusDrop: Fusing Visual and Cross-Modal Saliency for Efficient Vision Language Models
Feb 01, 2026Vision-Language Models (VLMs) are expensive because the LLM processes hundreds of largely redundant visual tokens. Existing token reduction methods typically exploit \textit{either} vision-encoder saliency (broad but query-agnostic) \textit{or} LLM cross-attention (query-aware but sparse and costly). We show that neither signal alone is sufficient: fusing them consistently improves performance compared to unimodal visual token selection (ranking). However, making such fusion practical is non-trivial: cross-modal saliency is usually only available \emph{inside} the LLM (too late for efficient pre-LLM pruning), and the two signals are inherently asymmetric, so naive fusion underutilizes their complementary strengths. We propose \textbf{ConsensusDrop}, a training-free framework that derives a \emph{consensus} ranking by reconciling vision encoder saliency with query-aware cross-attention, retaining the most informative tokens while compressing the remainder via encoder-guided token merging. Across LLaVA-1.5/NeXT, Video-LLaVA, and other open-source VLMs, ConsensusDrop consistently outperforms prior pruning methods under identical token budgets and delivers a stronger accuracy-efficiency Pareto frontier -- preserving near-baseline accuracy even at aggressive token reductions while reducing TTFT and KV cache footprint. Our code will be open-sourced.
Primitive-Driven Acceleration of Hyperdimensional Computing for Real-Time Image Classification
Jan 27, 2026Hyperdimensional Computing (HDC) represents data using extremely high-dimensional, low-precision vectors, termed hypervectors (HVs), and performs learning and inference through lightweight, noise-tolerant operations. However, the high dimensionality, sparsity, and repeated data movement involved in HDC make these computations difficult to accelerate efficiently on conventional processors. As a result, executing core HDC operations: binding, permutation, bundling, and similarity search: on CPUs or GPUs often leads to suboptimal utilization, memory bottlenecks, and limits on real-time performance. In this paper, our contributions are two-fold. First, we develop an image-encoding algorithm that, similar in spirit to convolutional neural networks, maps local image patches to hypervectors enriched with spatial information. These patch-level hypervectors are then merged into a global representation using the fundamental HDC operations, enabling spatially sensitive and robust image encoding. This encoder achieves 95.67% accuracy on MNIST and 85.14% on Fashion-MNIST, outperforming prior HDC-based image encoders. Second, we design an end-to-end accelerator that implements these compute operations on an FPGA through a pipelined architecture that exploits parallelism both across the hypervector dimensionality and across the set of image patches. Our Alveo U280 implementation delivers 0.09ms inference latency, achieving up to 1300x and 60x speedup over state-of-the-art CPU and GPU baselines, respectively.
ScalableHD: Scalable and High-Throughput Hyperdimensional Computing Inference on Multi-Core CPUs
Jun 10, 2025



Hyperdimensional Computing (HDC) is a brain-inspired computing paradigm that represents and manipulates information using high-dimensional vectors, called hypervectors (HV). Traditional HDC methods, while robust to noise and inherently parallel, rely on single-pass, non-parametric training and often suffer from low accuracy. To address this, recent approaches adopt iterative training of base and class HVs, typically accelerated on GPUs. Inference, however, remains lightweight and well-suited for real-time execution. Yet, efficient HDC inference has been studied almost exclusively on specialized hardware such as FPGAs and GPUs, with limited attention to general-purpose multi-core CPUs. To address this gap, we propose ScalableHD for scalable and high-throughput HDC inference on multi-core CPUs. ScalableHD employs a two-stage pipelined execution model, where each stage is parallelized across cores and processes chunks of base and class HVs. Intermediate results are streamed between stages using a producer-consumer mechanism, enabling on-the-fly consumption and improving cache locality. To maximize performance, ScalableHD integrates memory tiling and NUMA-aware worker-to-core binding. Further, it features two execution variants tailored for small and large batch sizes, each designed to exploit compute parallelism based on workload characteristics while mitigating the memory-bound compute pattern that limits HDC inference performance on modern multi-core CPUs. ScalableHD achieves up to 10x speedup in throughput (samples per second) over state-of-the-art baselines such as TorchHD, across a diverse set of tasks ranging from human activity recognition to image classification, while preserving task accuracy. Furthermore, ScalableHD exhibits robust scalability: increasing the number of cores yields near-proportional throughput improvements.
Domain Expansion: Parameter-Efficient Modules as Building Blocks for Composite Domains
Jan 24, 2025Parameter-Efficient Fine-Tuning (PEFT) is an efficient alternative to full scale fine-tuning, gaining popularity recently. With pre-trained model sizes growing exponentially, PEFT can be effectively utilized to fine-tune compact modules, Parameter-Efficient Modules (PEMs), trained to be domain experts over diverse domains. In this project, we explore composing such individually fine-tuned PEMs for distribution generalization over the composite domain. To compose PEMs, simple composing functions are used that operate purely on the weight space of the individually fine-tuned PEMs, without requiring any additional fine-tuning. The proposed method is applied to the task of representing the 16 Myers-Briggs Type Indicator (MBTI) composite personalities via 4 building block dichotomies, comprising of 8 individual traits which can be merged (composed) to yield a unique personality. We evaluate the individual trait PEMs and the composed personality PEMs via an online MBTI personality quiz questionnaire, validating the efficacy of PEFT to fine-tune PEMs and merging PEMs without further fine-tuning for domain composition.
ClusterViG: Efficient Globally Aware Vision GNNs via Image Partitioning
Jan 18, 2025


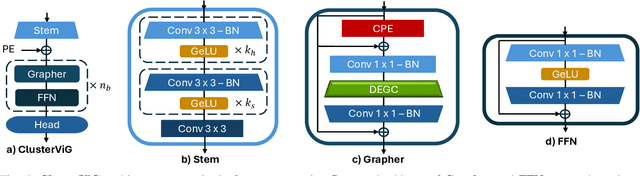
Convolutional Neural Networks (CNN) and Vision Transformers (ViT) have dominated the field of Computer Vision (CV). Graph Neural Networks (GNN) have performed remarkably well across diverse domains because they can represent complex relationships via unstructured graphs. However, the applicability of GNNs for visual tasks was unexplored till the introduction of Vision GNNs (ViG). Despite the success of ViGs, their performance is severely bottlenecked due to the expensive $k$-Nearest Neighbors ($k$-NN) based graph construction. Recent works addressing this bottleneck impose constraints on the flexibility of GNNs to build unstructured graphs, undermining their core advantage while introducing additional inefficiencies. To address these issues, in this paper, we propose a novel method called Dynamic Efficient Graph Convolution (DEGC) for designing efficient and globally aware ViGs. DEGC partitions the input image and constructs graphs in parallel for each partition, improving graph construction efficiency. Further, DEGC integrates local intra-graph and global inter-graph feature learning, enabling enhanced global context awareness. Using DEGC as a building block, we propose a novel CNN-GNN architecture, ClusterViG, for CV tasks. Extensive experiments indicate that ClusterViG reduces end-to-end inference latency for vision tasks by up to $5\times$ when compared against a suite of models such as ViG, ViHGNN, PVG, and GreedyViG, with a similar model parameter count. Additionally, ClusterViG reaches state-of-the-art performance on image classification, object detection, and instance segmentation tasks, demonstrating the effectiveness of the proposed globally aware learning strategy. Finally, input partitioning performed by DEGC enables ClusterViG to be trained efficiently on higher-resolution images, underscoring the scalability of our approach.
Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
May 16, 2024



We demonstrate the capabilities of an attention-based end-to-end approach for high-speed quadrotor obstacle avoidance in dense, cluttered environments, with comparison to various state-of-the-art architectures. Quadrotor unmanned aerial vehicles (UAVs) have tremendous maneuverability when flown fast; however, as flight speed increases, traditional vision-based navigation via independent mapping, planning, and control modules breaks down due to increased sensor noise, compounding errors, and increased processing latency. Thus, learning-based, end-to-end planning and control networks have shown to be effective for online control of these fast robots through cluttered environments. We train and compare convolutional, U-Net, and recurrent architectures against vision transformer models for depth-based end-to-end control, in a photorealistic, high-physics-fidelity simulator as well as in hardware, and observe that the attention-based models are more effective as quadrotor speeds increase, while recurrent models with many layers provide smoother commands at lower speeds. To the best of our knowledge, this is the first work to utilize vision transformers for end-to-end vision-based quadrotor control.