 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTR: An Optimized Vision Transformer for SAR ATR Acceleration on FPGA
Apr 06, 2024Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is a key technique used in military applications like remote-sensing image recognition. Vision Transformers (ViTs) are the current state-of-the-art in various computer vision applications, outperforming their CNN counterparts. However, using ViTs for SAR ATR applications is challenging due to (1) standard ViTs require extensive training data to generalize well due to their low locality; the standard SAR datasets, however, have a limited number of labeled training data which reduces the learning capability of ViTs; (2) ViTs have a high parameter count and are computation intensive which makes their deployment on resource-constrained SAR platforms difficult. In this work, we develop a lightweight ViT model that can be trained directly on small datasets without any pre-training by utilizing the Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) modules. We directly train this model on SAR datasets which have limited training samples to evaluate its effectiveness for SAR ATR applications. We evaluate our proposed model, that we call VTR (ViT for SAR ATR), on three widely used SAR datasets: MSTAR, SynthWakeSAR, and GBSAR. Further, we propose a novel FPGA accelerator for VTR, in order to enable deployment for real-time SAR ATR applications.
A Single Graph Convolution Is All You Need: Efficient Grayscale Image Classification
Feb 01, 2024

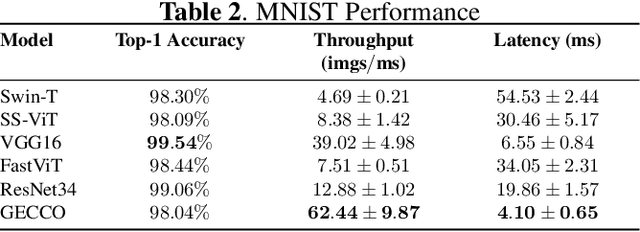

Image classifiers often rely on convolutional neural networks (CNN) for their tasks, which are inherently more heavyweight than multilayer perceptrons (MLPs), which can be problematic in real-time applications. Additionally, many image classification models work on both RGB and grayscale datasets. Classifiers that operate solely on grayscale images are much less common. Grayscale image classification has diverse applications, including but not limited to medical image classification and synthetic aperture radar (SAR) automatic target recognition (ATR). Thus, we present a novel grayscale (single channel) image classification approach using a vectorized view of images. We exploit the lightweightness of MLPs by viewing images as a vector and reducing our problem setting to the grayscale image classification setting. We find that using a single graph convolutional layer batch-wise increases accuracy and reduces variance in the performance of our model. Moreover, we develop a customized accelerator on FPGA for the proposed model with several optimizations to improve its performance. Our experimental results on benchmark grayscale image datasets demonstrate the effectiveness of the proposed model, achieving vastly lower latency (up to 16$\times$ less) and competitive or leading performance compared to other state-of-the-art image classification models on various domain-specific grayscale image classification datasets.