 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Expansion: Parameter-Efficient Modules as Building Blocks for Composite Domains
Jan 24, 2025Parameter-Efficient Fine-Tuning (PEFT) is an efficient alternative to full scale fine-tuning, gaining popularity recently. With pre-trained model sizes growing exponentially, PEFT can be effectively utilized to fine-tune compact modules, Parameter-Efficient Modules (PEMs), trained to be domain experts over diverse domains. In this project, we explore composing such individually fine-tuned PEMs for distribution generalization over the composite domain. To compose PEMs, simple composing functions are used that operate purely on the weight space of the individually fine-tuned PEMs, without requiring any additional fine-tuning. The proposed method is applied to the task of representing the 16 Myers-Briggs Type Indicator (MBTI) composite personalities via 4 building block dichotomies, comprising of 8 individual traits which can be merged (composed) to yield a unique personality. We evaluate the individual trait PEMs and the composed personality PEMs via an online MBTI personality quiz questionnaire, validating the efficacy of PEFT to fine-tune PEMs and merging PEMs without further fine-tuning for domain composition.
Multilingual Neural Machine Translation System for Indic to Indic Languages
Jun 22, 2023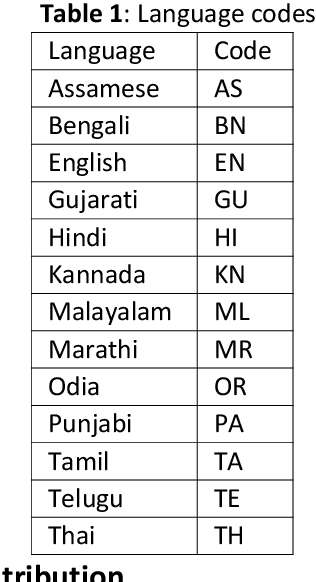
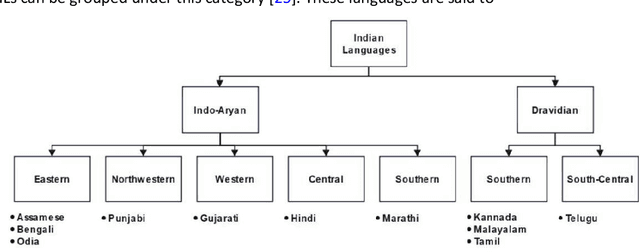
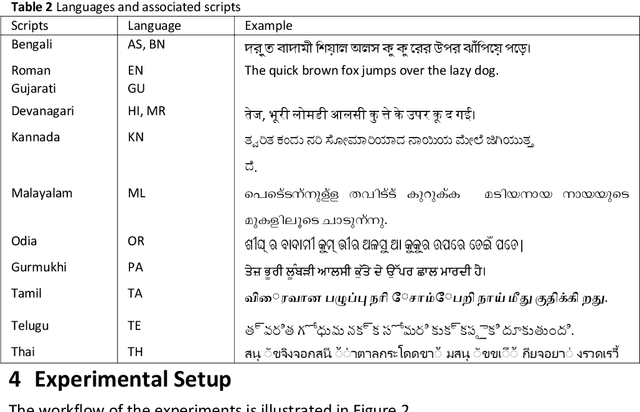
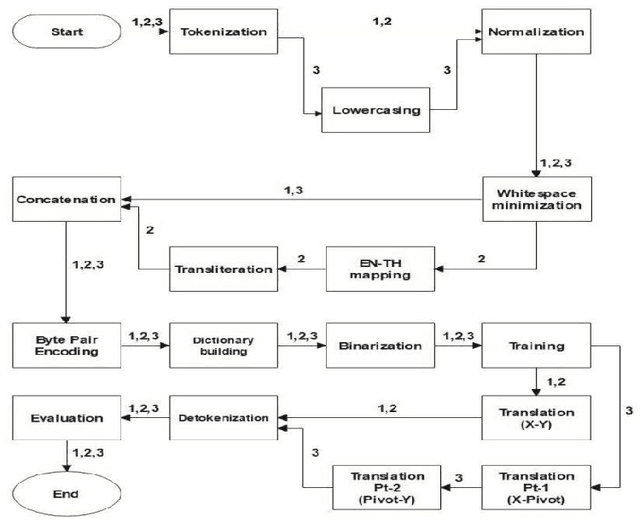
This paper gives an Indic-to-Indic (IL-IL) MNMT baseline model for 11 ILs implemented on the Samanantar corpus and analyzed on the Flores-200 corpus. All the models are evaluated using the BLEU score. In addition, the languages are classified under three groups namely East Indo- Aryan (EI), Dravidian (DR), and West Indo-Aryan (WI). The effect of language relatedness on MNMT model efficiency is studied. Owing to the presence of large corpora from English (EN) to ILs, MNMT IL-IL models using EN as a pivot are also built and examined. To achieve this, English- Indic (EN-IL) models are also developed, with and without the usage of related languages. Results reveal that using related languages is beneficial for the WI group only, while it is detrimental for the EI group and shows an inconclusive effect on the DR group, but it is useful for EN-IL models. Thus, related language groups are used to develop pivot MNMT models. Furthermore, the IL corpora are transliterated from the corresponding scripts to a modified ITRANS script, and the best MNMT models from the previous approaches are built on the transliterated corpus. It is observed that the usage of pivot models greatly improves MNMT baselines with AS-TA achieving the minimum BLEU score and PA-HI achieving the maximum score. Among languages, AS, ML, and TA achieve the lowest BLEU score, whereas HI, PA, and GU perform the best. Transliteration also helps the models with few exceptions. The best increment of scores is observed in ML, TA, and BN and the worst average increment is observed in KN, HI, and PA, across all languages. The best model obtained is the PA-HI language pair trained on PAWI transliterated corpus which gives 24.29 BLEU.