 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative analysis of subword tokenization approaches for Indian languages
May 22, 2025Tokenization is the act of breaking down text into smaller parts, or tokens, that are easier for machines to process. This is a key phase in machine translation (MT) models. Subword tokenization enhances this process by breaking down words into smaller subword units, which is especially beneficial in languages with complicated morphology or a vast vocabulary. It is useful in capturing the intricate structure of words in Indian languages (ILs), such as prefixes, suffixes, and other morphological variations. These languages frequently use agglutinative structures, in which words are formed by the combination of multiple morphemes such as suffixes, prefixes, and stems. As a result, a suitable tokenization strategy must be chosen to address these scenarios. This paper examines how different subword tokenization techniques, such as SentencePiece, Byte Pair Encoding (BPE), and WordPiece Tokenization, affect ILs. The effectiveness of these subword tokenization techniques is investigated in statistical, neural, and multilingual neural machine translation models. All models are examined using standard evaluation metrics, such as the Bilingual Evaluation Understudy (BLEU) score, TER, METEOR, CHRF, RIBES, and COMET. Based on the results, it appears that for the majority of language pairs for the Statistical and Neural MT models, the SentencePiece tokenizer continuously performed better than other tokenizers in terms of BLEU score. However, BPE tokenization outperformed other tokenization techniques in the context of Multilingual Neural Machine Translation model. The results show that, despite using the same tokenizer and dataset for each model, translations from ILs to English surpassed translations from English to ILs.
An approach for mistranslation removal from popular dataset for Indic MT Task
Jan 12, 2024The conversion of content from one language to another utilizing a computer system is known as Machine Translation (MT). Various techniques have come up to ensure effective translations that retain the contextual and lexical interpretation of the source language. End-to-end Neural Machine Translation (NMT) is a popular technique and it is now widely used in real-world MT systems. Massive amounts of parallel datasets (sentences in one language alongside translations in another) are required for MT systems. These datasets are crucial for an MT system to learn linguistic structures and patterns of both languages during the training phase. One such dataset is Samanantar, the largest publicly accessible parallel dataset for Indian languages (ILs). Since the corpus has been gathered from various sources, it contains many incorrect translations. Hence, the MT systems built using this dataset cannot perform to their usual potential. In this paper, we propose an algorithm to remove mistranslations from the training corpus and evaluate its performance and efficiency. Two Indic languages (ILs), namely, Hindi (HIN) and Odia (ODI) are chosen for the experiment. A baseline NMT system is built for these two ILs, and the effect of different dataset sizes is also investigated. The quality of the translations in the experiment is evaluated using standard metrics such as BLEU, METEOR, and RIBES. From the results, it is observed that removing the incorrect translation from the dataset makes the translation quality better. It is also noticed that, despite the fact that the ILs-English and English-ILs systems are trained using the same corpus, ILs-English works more effectively across all the evaluation metrics.
Multilingual Neural Machine Translation System for Indic to Indic Languages
Jun 22, 2023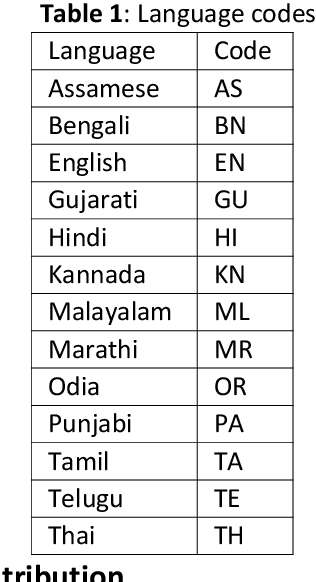
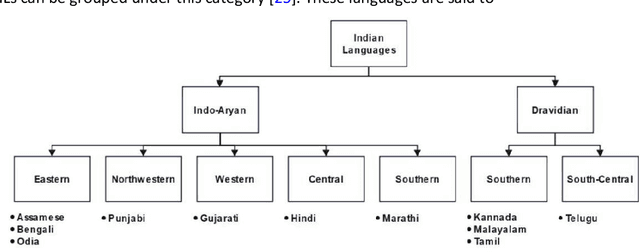
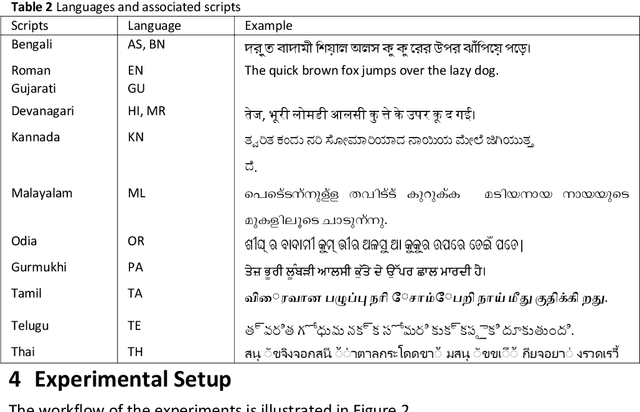
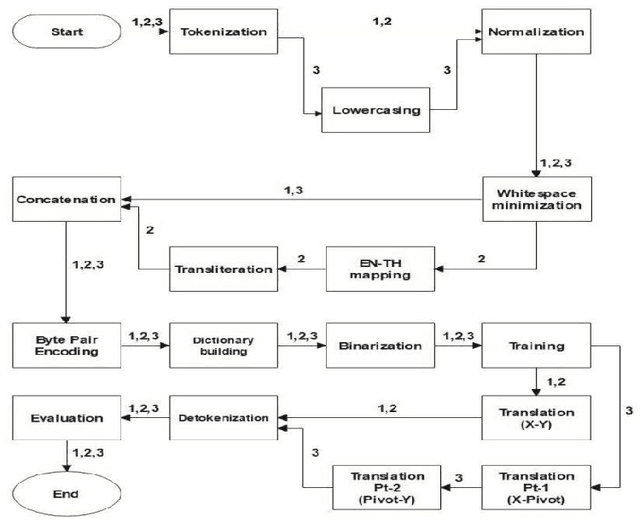
This paper gives an Indic-to-Indic (IL-IL) MNMT baseline model for 11 ILs implemented on the Samanantar corpus and analyzed on the Flores-200 corpus. All the models are evaluated using the BLEU score. In addition, the languages are classified under three groups namely East Indo- Aryan (EI), Dravidian (DR), and West Indo-Aryan (WI). The effect of language relatedness on MNMT model efficiency is studied. Owing to the presence of large corpora from English (EN) to ILs, MNMT IL-IL models using EN as a pivot are also built and examined. To achieve this, English- Indic (EN-IL) models are also developed, with and without the usage of related languages. Results reveal that using related languages is beneficial for the WI group only, while it is detrimental for the EI group and shows an inconclusive effect on the DR group, but it is useful for EN-IL models. Thus, related language groups are used to develop pivot MNMT models. Furthermore, the IL corpora are transliterated from the corresponding scripts to a modified ITRANS script, and the best MNMT models from the previous approaches are built on the transliterated corpus. It is observed that the usage of pivot models greatly improves MNMT baselines with AS-TA achieving the minimum BLEU score and PA-HI achieving the maximum score. Among languages, AS, ML, and TA achieve the lowest BLEU score, whereas HI, PA, and GU perform the best. Transliteration also helps the models with few exceptions. The best increment of scores is observed in ML, TA, and BN and the worst average increment is observed in KN, HI, and PA, across all languages. The best model obtained is the PA-HI language pair trained on PAWI transliterated corpus which gives 24.29 BLEU.
Statistical Machine Translation for Indic Languages
Jan 02, 2023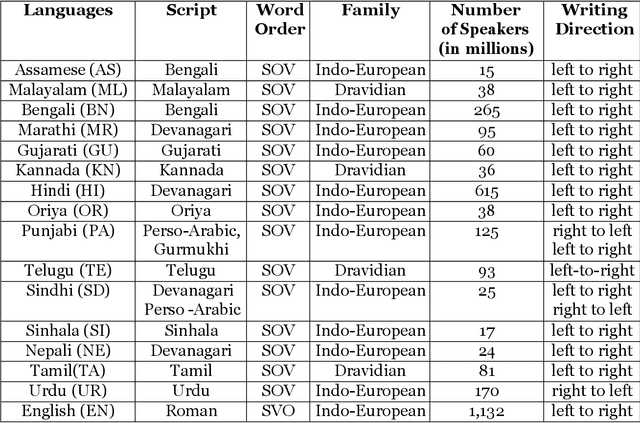
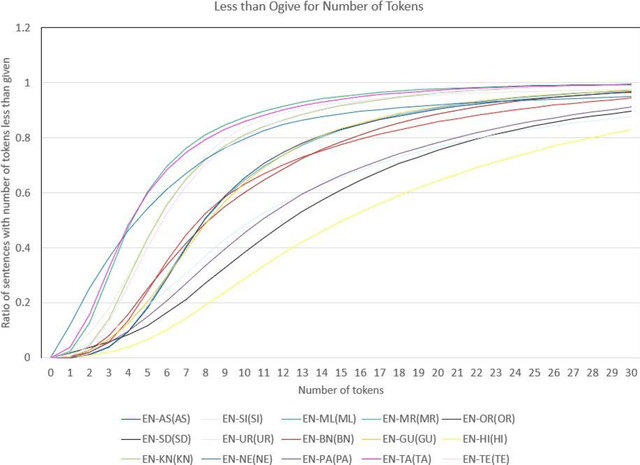
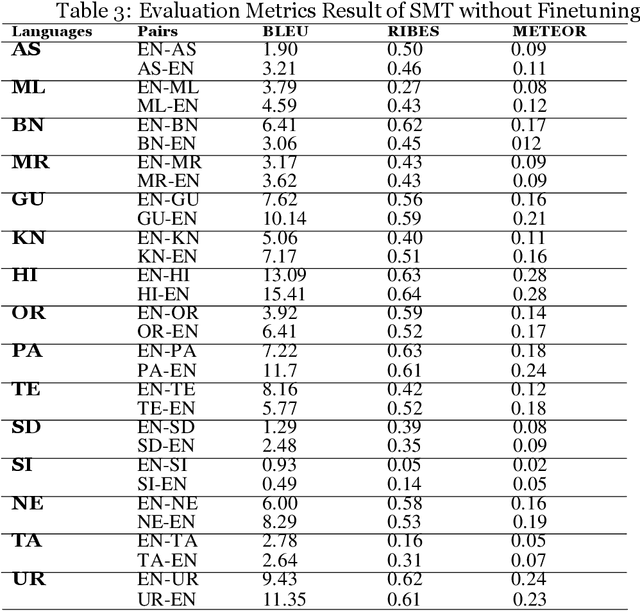
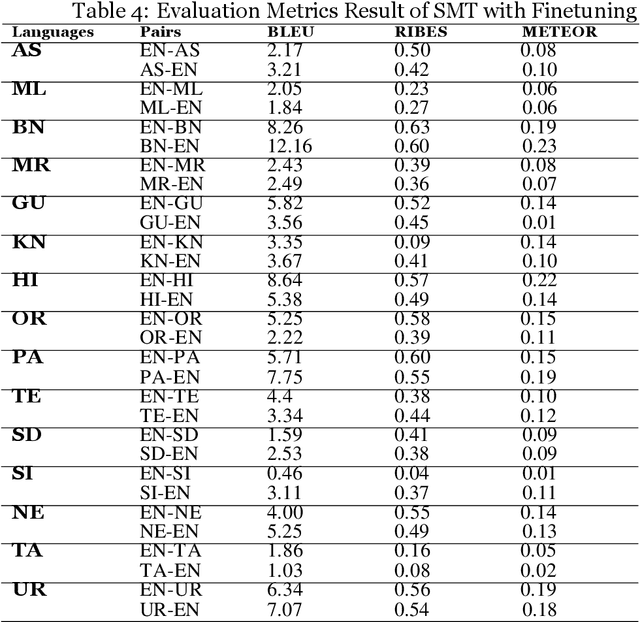
Machine Translation (MT) system generally aims at automatic representation of source language into target language retaining the originality of context using various Natural Language Processing (NLP) techniques. Among various NLP methods, Statistical Machine Translation(SMT). SMT uses probabilistic and statistical techniques to analyze information and conversion. This paper canvasses about the development of bilingual SMT models for translating English to fifteen low-resource Indian Languages (ILs) and vice versa. At the outset, all 15 languages are briefed with a short description related to our experimental need. Further, a detailed analysis of Samanantar and OPUS dataset for model building, along with standard benchmark dataset (Flores-200) for fine-tuning and testing, is done as a part of our experiment. Different preprocessing approaches are proposed in this paper to handle the noise of the dataset. To create the system, MOSES open-source SMT toolkit is explored. Distance reordering is utilized with the aim to understand the rules of grammar and context-dependent adjustments through a phrase reordering categorization framework. In our experiment, the quality of the translation is evaluated using standard metrics such as BLEU, METEOR, and RIBES