 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Machine Translation for Indic Languages
Paper and Code
Jan 02, 2023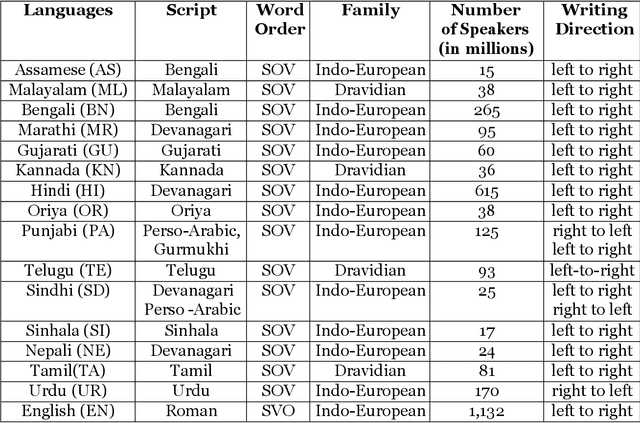
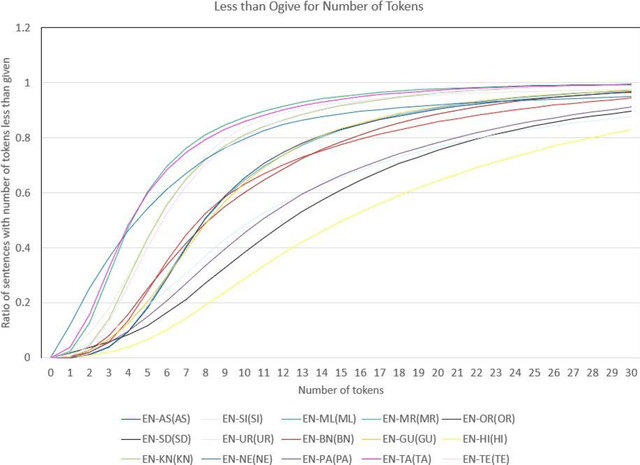
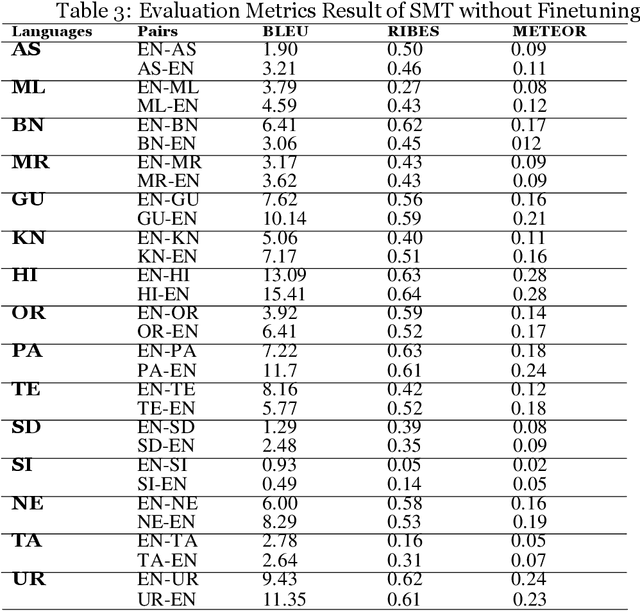
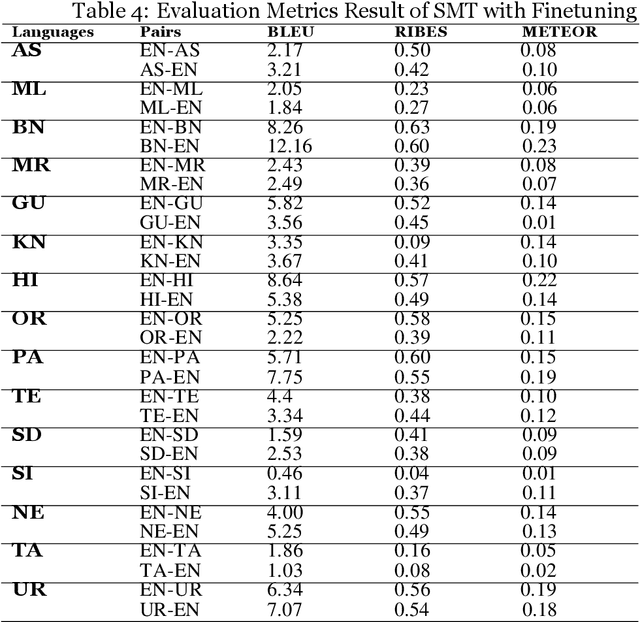
Machine Translation (MT) system generally aims at automatic representation of source language into target language retaining the originality of context using various Natural Language Processing (NLP) techniques. Among various NLP methods, Statistical Machine Translation(SMT). SMT uses probabilistic and statistical techniques to analyze information and conversion. This paper canvasses about the development of bilingual SMT models for translating English to fifteen low-resource Indian Languages (ILs) and vice versa. At the outset, all 15 languages are briefed with a short description related to our experimental need. Further, a detailed analysis of Samanantar and OPUS dataset for model building, along with standard benchmark dataset (Flores-200) for fine-tuning and testing, is done as a part of our experiment. Different preprocessing approaches are proposed in this paper to handle the noise of the dataset. To create the system, MOSES open-source SMT toolkit is explored. Distance reordering is utilized with the aim to understand the rules of grammar and context-dependent adjustments through a phrase reordering categorization framework. In our experiment, the quality of the translation is evaluated using standard metrics such as BLEU, METEOR, and RIBES