 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning-Based Approach for a Single Vehicle Persistent Surveillance Problem with Fuel Constraints
Apr 13, 2024



This article presents a deep reinforcement learning-based approach to tackle a persistent surveillance mission requiring a single unmanned aerial vehicle initially stationed at a depot with fuel or time-of-flight constraints to repeatedly visit a set of targets with equal priority. Owing to the vehicle's fuel or time-of-flight constraints, the vehicle must be regularly refueled, or its battery must be recharged at the depot. The objective of the problem is to determine an optimal sequence of visits to the targets that minimizes the maximum time elapsed between successive visits to any target while ensuring that the vehicle never runs out of fuel or charge. We present a deep reinforcement learning algorithm to solve this problem and present the results of numerical experiments that corroborate the effectiveness of this approach in comparison with common-sense greedy heuristics.
Beyond Joint Demonstrations: Personalized Expert Guidance for Efficient Multi-Agent Reinforcement Learning
Mar 13, 2024



Multi-Agent Reinforcement Learning (MARL) algorithms face the challenge of efficient exploration due to the exponential increase in the size of the joint state-action space. While demonstration-guided learning has proven beneficial in single-agent settings, its direct applicability to MARL is hindered by the practical difficulty of obtaining joint expert demonstrations. In this work, we introduce a novel concept of personalized expert demonstrations, tailored for each individual agent or, more broadly, each individual type of agent within a heterogeneous team. These demonstrations solely pertain to single-agent behaviors and how each agent can achieve personal goals without encompassing any cooperative elements, thus naively imitating them will not achieve cooperation due to potential conflicts. To this end, we propose an approach that selectively utilizes personalized expert demonstrations as guidance and allows agents to learn to cooperate, namely personalized expert-guided MARL (PegMARL). This algorithm utilizes two discriminators: the first provides incentives based on the alignment of policy behavior with demonstrations, and the second regulates incentives based on whether the behavior leads to the desired objective. We evaluate PegMARL using personalized demonstrations in both discrete and continuous environments. The results demonstrate that PegMARL learns near-optimal policies even when provided with suboptimal demonstrations, and outperforms state-of-the-art MARL algorithms in solving coordinated tasks. We also showcase PegMARL's capability to leverage joint demonstrations in the StarCraft scenario and converge effectively even with demonstrations from non-co-trained policies.
GALOPP: Multi-Agent Deep Reinforcement Learning For Persistent Monitoring With Localization Constraints
Sep 22, 2021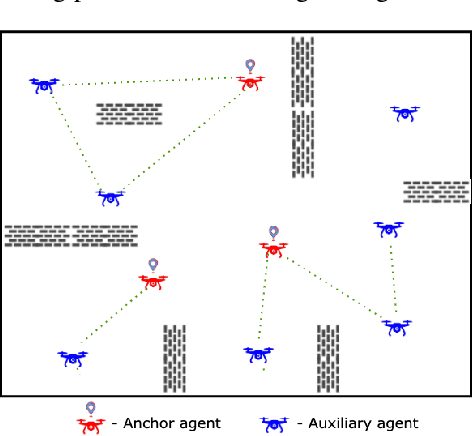
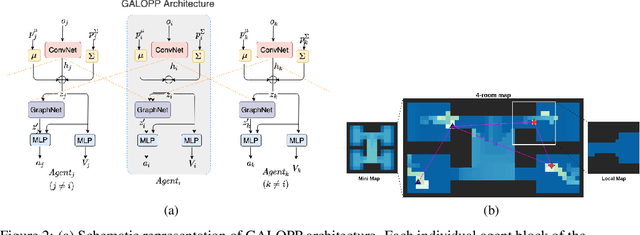
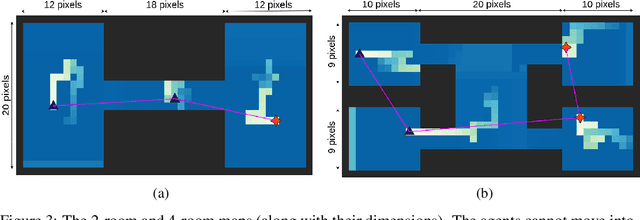
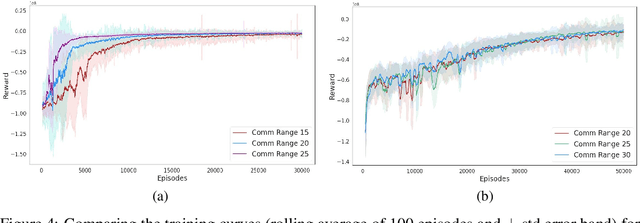
Persistently monitoring a region under localization and communication constraints is a challenging problem. In this paper, we consider a heterogenous robotic system consisting of two types of agents -- anchor agents that have accurate localization capability, and auxiliary agents that have low localization accuracy. The auxiliary agents must be within the communication range of an {anchor}, directly or indirectly to localize itself. The objective of the robotic team is to minimize the uncertainty in the environment through persistent monitoring. We propose a multi-agent deep reinforcement learning (MADRL) based architecture with graph attention called Graph Localized Proximal Policy Optimization (GALLOP), which incorporates the localization and communication constraints of the agents along with persistent monitoring objective to determine motion policies for each agent. We evaluate the performance of GALLOP on three different custom-built environments. The results show the agents are able to learn a stable policy and outperform greedy and random search baseline approaches.