 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKORSAL: Key-point Detection based Online Real-Time Spatio-Temporal Action Localization
Nov 05, 2021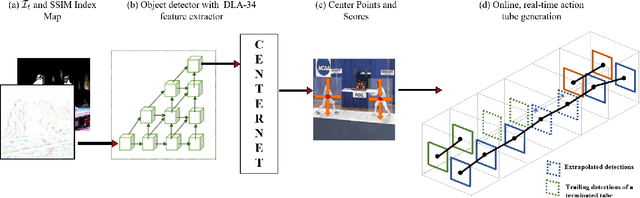
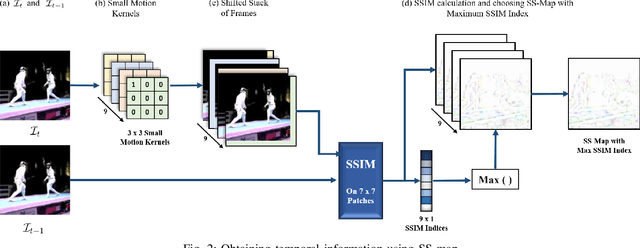

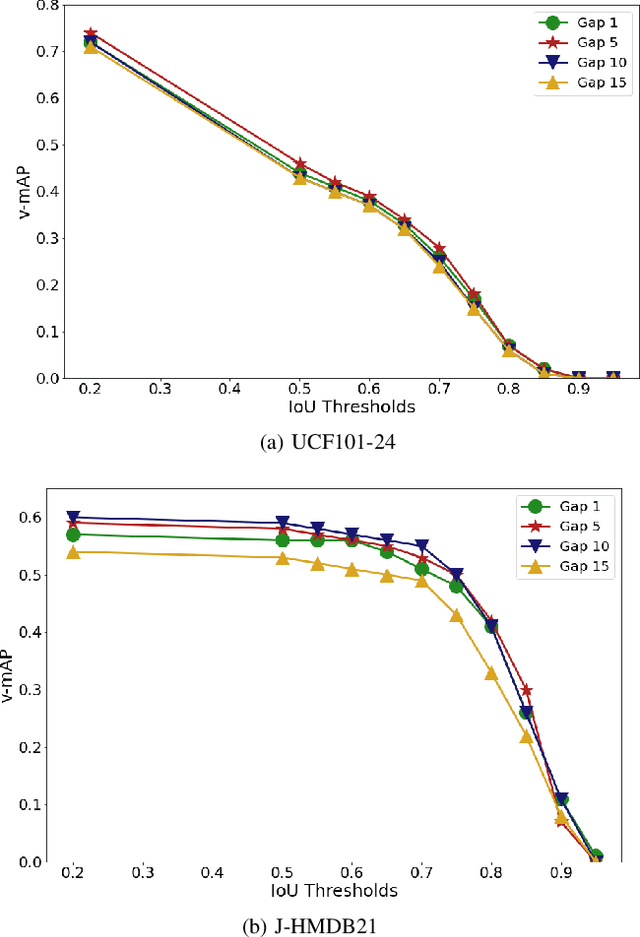
Real-time and online action localization in a video is a critical yet highly challenging problem. Accurate action localization requires the utilization of both temporal and spatial information. Recent attempts achieve this by using computationally intensive 3D CNN architectures or highly redundant two-stream architectures with optical flow, making them both unsuitable for real-time, online applications. To accomplish activity localization under highly challenging real-time constraints, we propose utilizing fast and efficient key-point based bounding box prediction to spatially localize actions. We then introduce a tube-linking algorithm that maintains the continuity of action tubes temporally in the presence of occlusions. Further, we eliminate the need for a two-stream architecture by combining temporal and spatial information into a cascaded input to a single network, allowing the network to learn from both types of information. Temporal information is efficiently extracted using a structural similarity index map as opposed to computationally intensive optical flow. Despite the simplicity of our approach, our lightweight end-to-end architecture achieves state-of-the-art frame-mAP of 74.7% on the challenging UCF101-24 dataset, demonstrating a performance gain of 6.4% over the previous best online methods. We also achieve state-of-the-art video-mAP results compared to both online and offline methods. Moreover, our model achieves a frame rate of 41.8 FPS, which is a 10.7% improvement over contemporary real-time methods.