 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary Volumetric Refocusing of Dense and Sparse Light Fields
Feb 26, 2025A four-dimensional light field (LF) captures both textural and geometrical information of a scene in contrast to a two-dimensional image that captures only the textural information of a scene. Post-capture refocusing is an exciting application of LFs enabled by the geometric information captured. Previously proposed LF refocusing methods are mostly limited to the refocusing of single planar or volumetric region of a scene corresponding to a depth range and cannot simultaneously generate in-focus and out-of-focus regions having the same depth range. In this paper, we propose an end-to-end pipeline to simultaneously refocus multiple arbitrary planar or volumetric regions of a dense or a sparse LF. We employ pixel-dependent shifts with the typical shift-and-sum method to refocus an LF. The pixel-dependent shifts enables to refocus each pixel of an LF independently. For sparse LFs, the shift-and-sum method introduces ghosting artifacts due to the spatial undersampling. We employ a deep learning model based on U-Net architecture to almost completely eliminate the ghosting artifacts. The experimental results obtained with several LF datasets confirm the effectiveness of the proposed method. In particular, sparse LFs refocused with the proposed method archive structural similarity index higher than 0.9 despite having only 20% of data compared to dense LFs.
DualCam: A Novel Benchmark Dataset for Fine-grained Real-time Traffic Light Detection
Sep 03, 2022


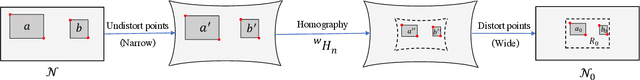
Traffic light detection is essential for self-driving cars to navigate safely in urban areas. Publicly available traffic light datasets are inadequate for the development of algorithms for detecting distant traffic lights that provide important navigation information. We introduce a novel benchmark traffic light dataset captured using a synchronized pair of narrow-angle and wide-angle cameras covering urban and semi-urban roads. We provide 1032 images for training and 813 synchronized image pairs for testing. Additionally, we provide synchronized video pairs for qualitative analysis. The dataset includes images of resolution 1920$\times$1080 covering 10 different classes. Furthermore, we propose a post-processing algorithm for combining outputs from the two cameras. Results show that our technique can strike a balance between speed and accuracy, compared to the conventional approach of using a single camera frame.