 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAUXfdp: Differentially Private One-Shot Federated Distillation
May 30, 2022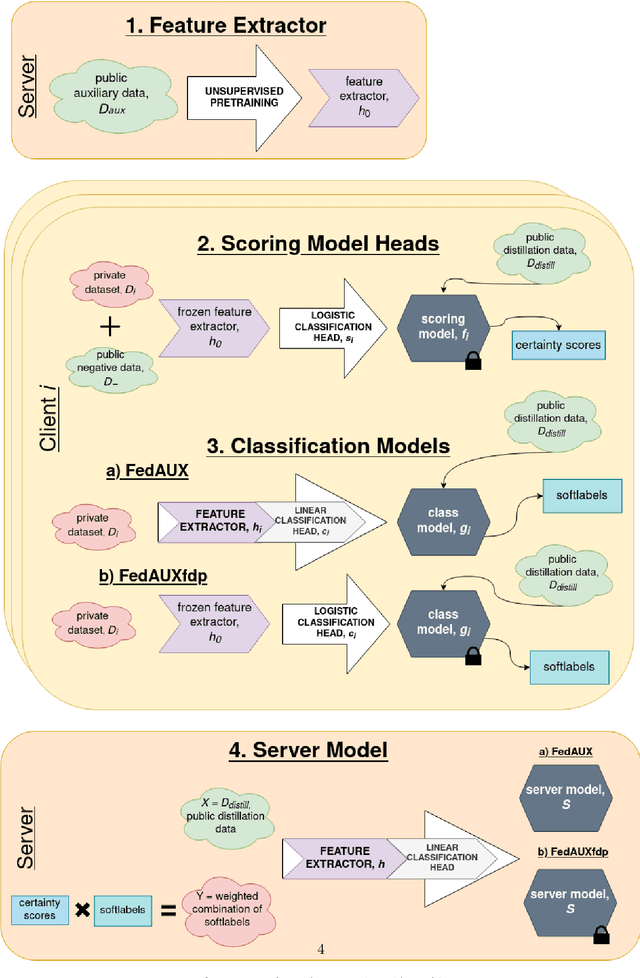



Federated learning suffers in the case of non-iid local datasets, i.e., when the distributions of the clients' data are heterogeneous. One promising approach to this challenge is the recently proposed method FedAUX, an augmentation of federated distillation with robust results on even highly heterogeneous client data. FedAUX is a partially $(\epsilon, \delta)$-differentially private method, insofar as the clients' private data is protected in only part of the training it takes part in. This work contributes a fully differentially private extension, termed FedAUXfdp. In experiments with deep networks on large-scale image datasets, FedAUXfdp with strong differential privacy guarantees performs significantly better than other equally privatized SOTA baselines on non-iid client data in just a single communication round. Full privatization results in a negligible reduction in accuracy at all levels of data heterogeneity.
FedAUX: Leveraging Unlabeled Auxiliary Data in Federated Learning
Feb 04, 2021



Federated Distillation (FD) is a popular novel algorithmic paradigm for Federated Learning, which achieves training performance competitive to prior parameter averaging based methods, while additionally allowing the clients to train different model architectures, by distilling the client predictions on an unlabeled auxiliary set of data into a student model. In this work we propose FedAUX, an extension to FD, which, under the same set of assumptions, drastically improves performance by deriving maximum utility from the unlabeled auxiliary data. FedAUX modifies the FD training procedure in two ways: First, unsupervised pre-training on the auxiliary data is performed to find a model initialization for the distributed training. Second, $(\varepsilon, \delta)$-differentially private certainty scoring is used to weight the ensemble predictions on the auxiliary data according to the certainty of each client model. Experiments on large-scale convolutional neural networks and transformer models demonstrate, that the training performance of FedAUX exceeds SOTA FL baseline methods by a substantial margin in both the iid and non-iid regime, further closing the gap to centralized training performance. Code is available at github.com/fedl-repo/fedaux.
Communication-Efficient Federated Distillation
Dec 01, 2020Communication constraints are one of the major challenges preventing the wide-spread adoption of Federated Learning systems. Recently, Federated Distillation (FD), a new algorithmic paradigm for Federated Learning with fundamentally different communication properties, emerged. FD methods leverage ensemble distillation techniques and exchange model outputs, presented as soft labels on an unlabeled public data set, between the central server and the participating clients. While for conventional Federated Learning algorithms, like Federated Averaging (FA), communication scales with the size of the jointly trained model, in FD communication scales with the distillation data set size, resulting in advantageous communication properties, especially when large models are trained. In this work, we investigate FD from the perspective of communication efficiency by analyzing the effects of active distillation-data curation, soft-label quantization and delta-coding techniques. Based on the insights gathered from this analysis, we present Compressed Federated Distillation (CFD), an efficient Federated Distillation method. Extensive experiments on Federated image classification and language modeling problems demonstrate that our method can reduce the amount of communication necessary to achieve fixed performance targets by more than two orders of magnitude, when compared to FD and by more than four orders of magnitude when compared with FA.