 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Tools are Needed for Tracking Adherence to AI Model Behavioral Use Clauses
May 28, 2025



Foundation models have had a transformative impact on AI. A combination of large investments in research and development, growing sources of digital data for training, and architectures that scale with data and compute has led to models with powerful capabilities. Releasing assets is fundamental to scientific advancement and commercial enterprise. However, concerns over negligent or malicious uses of AI have led to the design of mechanisms to limit the risks of the technology. The result has been a proliferation of licenses with behavioral-use clauses and acceptable-use-policies that are increasingly being adopted by commonly used families of models (Llama, Gemma, Deepseek) and a myriad of smaller projects. We created and deployed a custom AI licenses generator to facilitate license creation and have quantitatively and qualitatively analyzed over 300 customized licenses created with this tool. Alongside this we analyzed 1.7 million models licenses on the HuggingFace model hub. Our results show increasing adoption of these licenses, interest in tools that support their creation and a convergence on common clause configurations. In this paper we take the position that tools for tracking adoption of, and adherence to, these licenses is the natural next step and urgently needed in order to ensure they have the desired impact of ensuring responsible use.
How simple can you go? An off-the-shelf transformer approach to molecular dynamics
Mar 05, 2025Most current neural networks for molecular dynamics (MD) include physical inductive biases, resulting in specialized and complex architectures. This is in contrast to most other machine learning domains, where specialist approaches are increasingly replaced by general-purpose architectures trained on vast datasets. In line with this trend, several recent studies have questioned the necessity of architectural features commonly found in MD models, such as built-in rotational equivariance or energy conservation. In this work, we contribute to the ongoing discussion by evaluating the performance of an MD model with as few specialized architectural features as possible. We present a recipe for MD using an Edge Transformer, an "off-the-shelf'' transformer architecture that has been minimally modified for the MD domain, termed MD-ET. Our model implements neither built-in equivariance nor energy conservation. We use a simple supervised pre-training scheme on $\sim$30 million molecular structures from the QCML database. Using this "off-the-shelf'' approach, we show state-of-the-art results on several benchmarks after fine-tuning for a small number of steps. Additionally, we examine the effects of being only approximately equivariant and energy conserving for MD simulations, proposing a novel method for distinguishing the errors resulting from non-equivariance from other sources of inaccuracies like numerical rounding errors. While our model exhibits runaway energy increases on larger structures, we show approximately energy-conserving NVE simulations for a range of small structures.
Responding to Generative AI Technologies with Research-through-Design: The Ryelands AI Lab as an Exploratory Study
May 07, 2024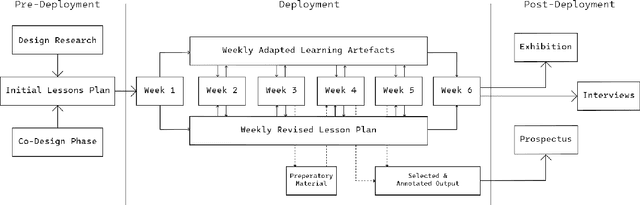
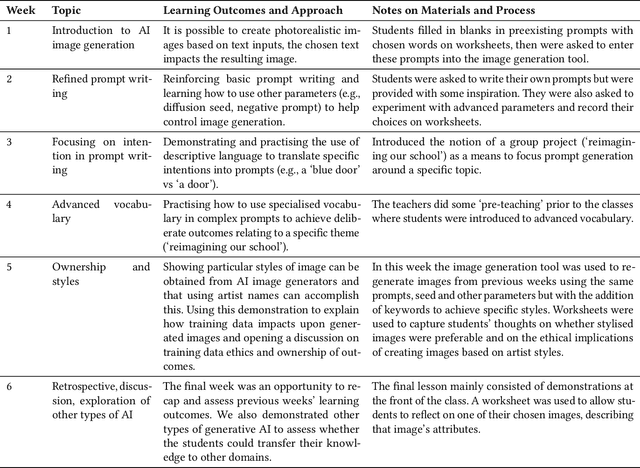

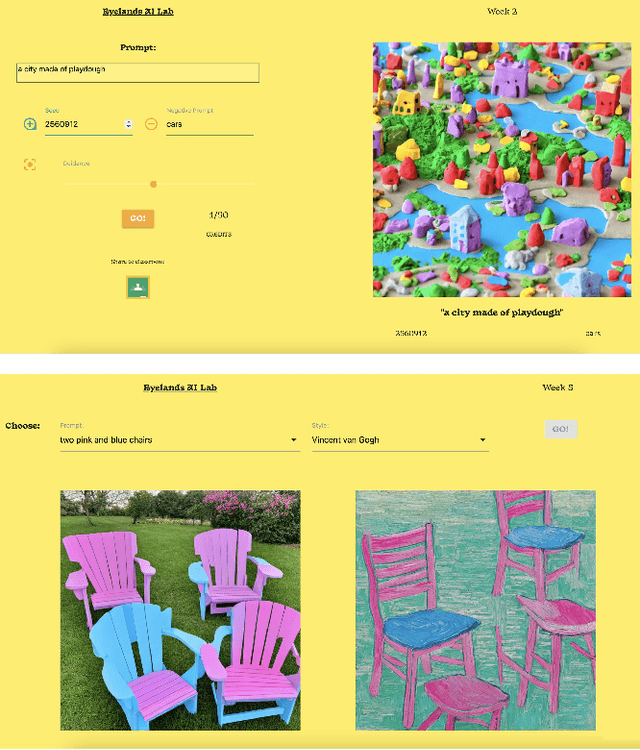
Generative AI technologies demand new practical and critical competencies, which call on design to respond to and foster these. We present an exploratory study guided by Research-through-Design, in which we partnered with a primary school to develop a constructionist curriculum centered on students interacting with a generative AI technology. We provide a detailed account of the design of and outputs from the curriculum and learning materials, finding centrally that the reflexive and prolonged `hands-on' approach led to a co-development of students' practical and critical competencies. From the study, we contribute guidance for designing constructionist approaches to generative AI technology education; further arguing to do so with `critical responsivity.' We then discuss how HCI researchers may leverage constructionist strategies in designing interactions with generative AI technologies; and suggest that Research-through-Design can play an important role as a `rapid response methodology' capable of reacting to fast-evolving, disruptive technologies such as generative AI.
On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI
Feb 07, 2024Growing concerns over negligent or malicious uses of AI have increased the appetite for tools that help manage the risks of the technology. In 2018, licenses with behaviorial-use clauses (commonly referred to as Responsible AI Licenses) were proposed to give developers a framework for releasing AI assets while specifying their users to mitigate negative applications. As of the end of 2023, on the order of 40,000 software and model repositories have adopted responsible AI licenses licenses. Notable models licensed with behavioral use clauses include BLOOM (language) and LLaMA2 (language), Stable Diffusion (image), and GRID (robotics). This paper explores why and how these licenses have been adopted, and why and how they have been adapted to fit particular use cases. We use a mixed-methods methodology of qualitative interviews, clustering of license clauses, and quantitative analysis of license adoption. Based on this evidence we take the position that responsible AI licenses need standardization to avoid confusing users or diluting their impact. At the same time, customization of behavioral restrictions is also appropriate in some contexts (e.g., medical domains). We advocate for ``standardized customization'' that can meet users' needs and can be supported via tooling.
Explanation Strategies as an Empirical-Analytical Lens for Socio-Technical Contextualization of Machine Learning Interpretability
Sep 24, 2021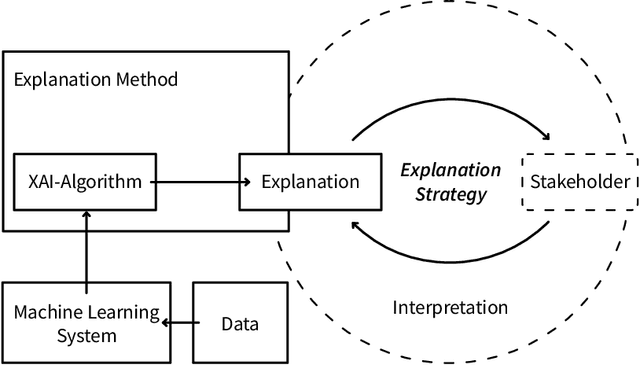


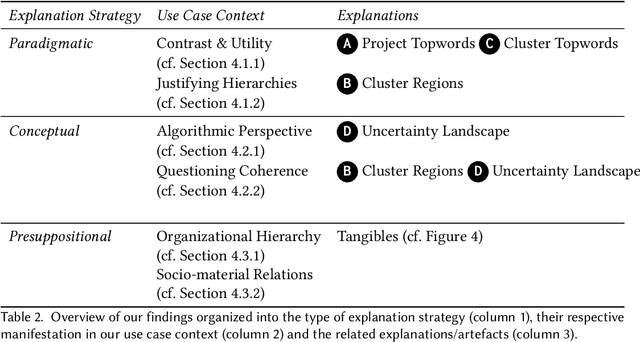
During a research project in which we developed a machine learning (ML) driven visualization system for non-ML experts, we reflected on interpretability research in ML, computer-supported collaborative work and human-computer interaction. We found that while there are manifold technical approaches, these often focus on ML experts and are evaluated in decontextualized empirical studies. We hypothesized that participatory design research may support the understanding of stakeholders' situated sense-making in our project, yet, found guidance regarding ML interpretability inexhaustive. Building on philosophy of technology, we formulated explanation strategies as an empirical-analytical lens explicating how technical explanations mediate the contextual preferences concerning people's interpretations. In this paper, we contribute a report of our proof-of-concept use of explanation strategies to analyze a co-design workshop with non-ML experts, methodological implications for participatory design research, design implications for explanations for non-ML experts and suggest further investigation of technological mediation theories in the ML interpretability space.
FedAUX: Leveraging Unlabeled Auxiliary Data in Federated Learning
Feb 04, 2021



Federated Distillation (FD) is a popular novel algorithmic paradigm for Federated Learning, which achieves training performance competitive to prior parameter averaging based methods, while additionally allowing the clients to train different model architectures, by distilling the client predictions on an unlabeled auxiliary set of data into a student model. In this work we propose FedAUX, an extension to FD, which, under the same set of assumptions, drastically improves performance by deriving maximum utility from the unlabeled auxiliary data. FedAUX modifies the FD training procedure in two ways: First, unsupervised pre-training on the auxiliary data is performed to find a model initialization for the distributed training. Second, $(\varepsilon, \delta)$-differentially private certainty scoring is used to weight the ensemble predictions on the auxiliary data according to the certainty of each client model. Experiments on large-scale convolutional neural networks and transformer models demonstrate, that the training performance of FedAUX exceeds SOTA FL baseline methods by a substantial margin in both the iid and non-iid regime, further closing the gap to centralized training performance. Code is available at github.com/fedl-repo/fedaux.