 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI needs formal notions of explanation correctness
Sep 26, 2024The use of machine learning (ML) in critical domains such as medicine poses risks and requires regulation. One requirement is that decisions of ML systems in high-risk applications should be human-understandable. The field of "explainable artificial intelligence" (XAI) seemingly addresses this need. However, in its current form, XAI is unfit to provide quality control for ML; it itself needs scrutiny. Popular XAI methods cannot reliably answer important questions about ML models, their training data, or a given test input. We recapitulate results demonstrating that popular XAI methods systematically attribute importance to input features that are independent of the prediction target. This limits their utility for purposes such as model and data (in)validation, model improvement, and scientific discovery. We argue that the fundamental reason for this limitation is that current XAI methods do not address well-defined problems and are not evaluated against objective criteria of explanation correctness. Researchers should formally define the problems they intend to solve first and then design methods accordingly. This will lead to notions of explanation correctness that can be theoretically verified and objective metrics of explanation performance that can be assessed using ground-truth data.
EXACT: Towards a platform for empirically benchmarking Machine Learning model explanation methods
May 20, 2024The evolving landscape of explainable artificial intelligence (XAI) aims to improve the interpretability of intricate machine learning (ML) models, yet faces challenges in formalisation and empirical validation, being an inherently unsupervised process. In this paper, we bring together various benchmark datasets and novel performance metrics in an initial benchmarking platform, the Explainable AI Comparison Toolkit (EXACT), providing a standardised foundation for evaluating XAI methods. Our datasets incorporate ground truth explanations for class-conditional features, and leveraging novel quantitative metrics, this platform assesses the performance of post-hoc XAI methods in the quality of the explanations they produce. Our recent findings have highlighted the limitations of popular XAI methods, as they often struggle to surpass random baselines, attributing significance to irrelevant features. Moreover, we show the variability in explanations derived from different equally performing model architectures. This initial benchmarking platform therefore aims to allow XAI researchers to test and assure the high quality of their newly developed methods.
Optimal Sampling Density for Nonparametric Regression
May 25, 2021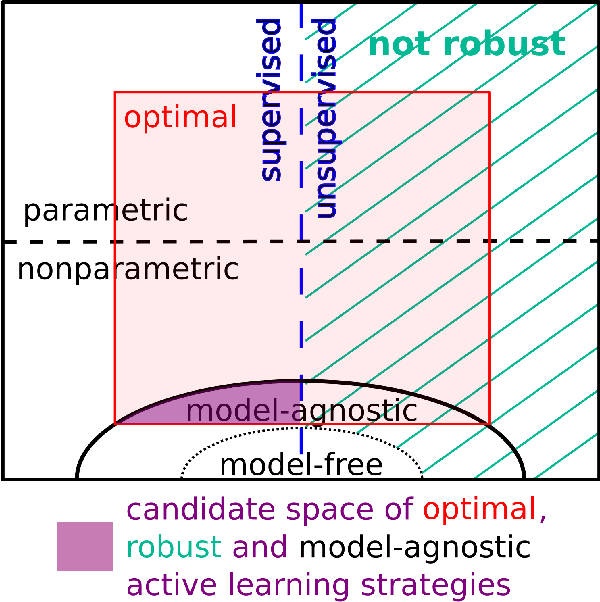
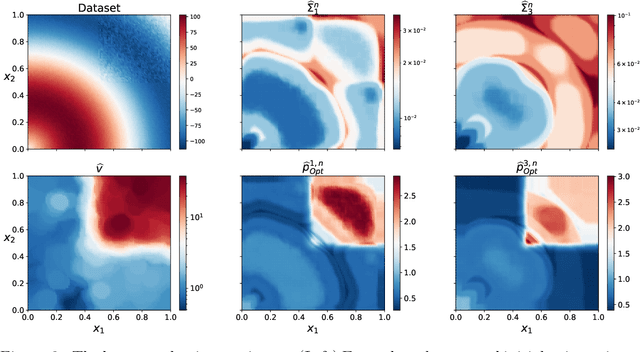
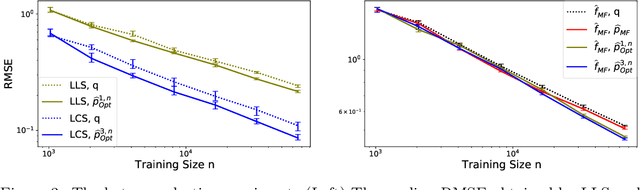
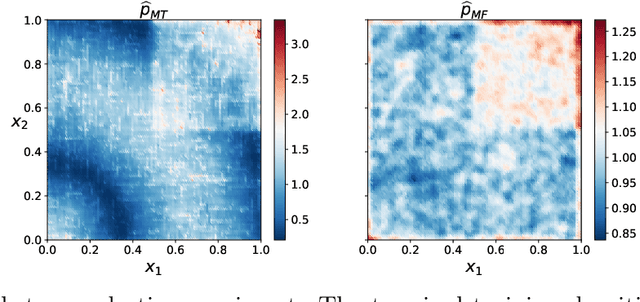
We propose a novel active learning strategy for regression, which is model-agnostic, robust against model mismatch, and interpretable. Assuming that a small number of initial samples are available, we derive the optimal training density that minimizes the generalization error of local polynomial smoothing (LPS) with its kernel bandwidth tuned locally: We adopt the mean integrated squared error (MISE) as a generalization criterion, and use the asymptotic behavior of the MISE as well as thelocally optimal bandwidths (LOB) -- the bandwidth function that minimizes MISE in the asymptotic limit. The asymptotic expression of our objective then reveals the dependence of the MISE on the training density, enabling analytic minimization. As a result, we obtain the optimal training density in a closed-form. The almost model-free nature of our approach should encode raw properties of the target problem, and thus provide a robust and model-agnostic active learning strategy. Furthermore, the obtained training density factorizes the influence of local function complexity, noise leveland test density in a transparent and interpretable way. We validate our theory in numerical simulations, and show that the proposed active learning method outperforms the existing state-of-the-art model-agnostic approaches.
Local Bandwidth Estimation via Mixture of Gaussian Processes
Feb 27, 2019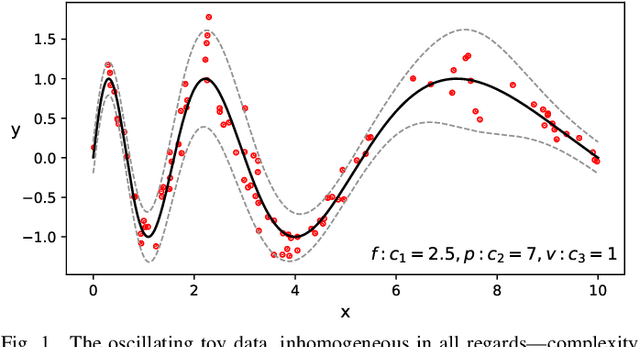
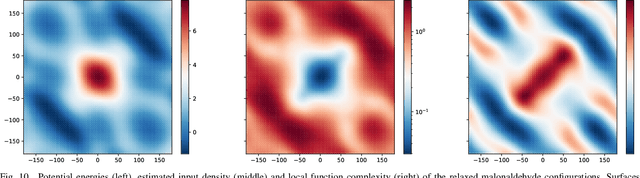
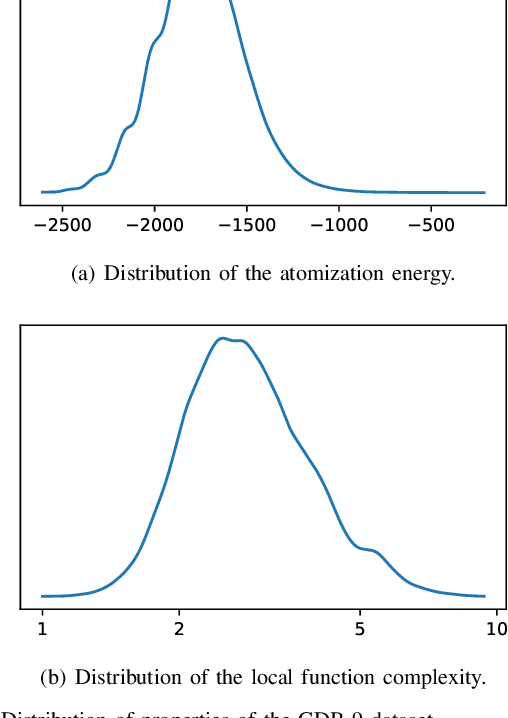
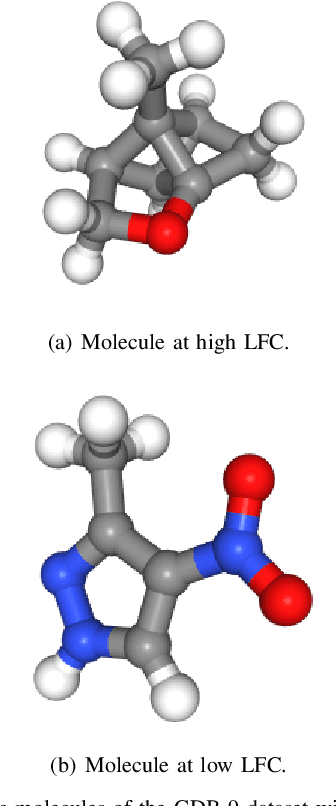
Real world data often exhibit inhomogeneity - complexity of the target function, noise level, etc. are not uniform over the input space. We address the issue of estimating locally optimal kernel bandwidth as a way to describe inhomogeneity. Estimated kernel bandwidths can be used not only for improving the regression/classification performance, but also for Bayesian optimization and active learning, i.e., we need more samples in the region where the function complexity and the noise level are higher. Our method, called kernel mixture of kernel experts regression (KMKER) follows the concept of mixture of experts, which is constituted of several complementary inference models, the so called experts, where in advance a latent classifier, called the gate, predicts the best fitting expert for each test input to infer. For the experts we implement Gaussian process regression models at different (global) bandwidths and a multinomial kernel logistic regression model as the gate. The basic idea behind mixture of experts is, that several distinct ground truth functions over a joint input space drive the observations, which one may want to disentangle. Each expert is meant to model one of the incompatible functions such that each expert needs its individual set of hyperparameters. We differ from that idea in the sense that we assume only one ground truth function which however exhibits spacially inhomogeneous behavior. Under these assumptions we share the hyperparameters among the experts keeping their number constant. We compare KMKER to previous methods (which cope with inhomogeneity but do not provide the optimal bandwidth estimator) on artificial and benchmark data and analyze its performance and capability for interpretation on datasets from quantum chemistry. We also demonstrate how KMKER can be applied for automatic adaptive grid selection in fluid dynamics simulations.
Sharing Hash Codes for Multiple Purposes
Jun 01, 2017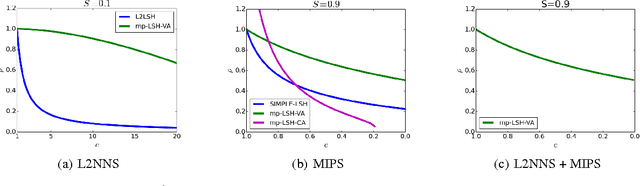
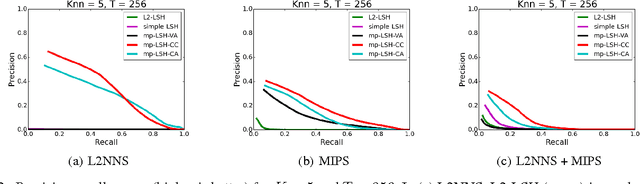
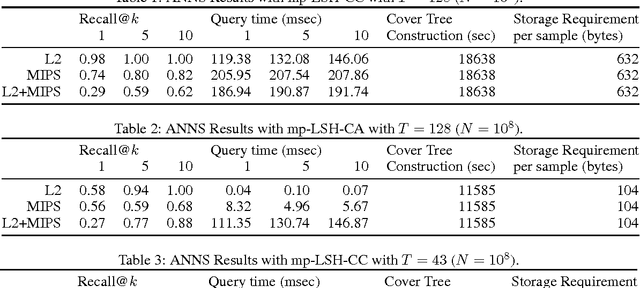
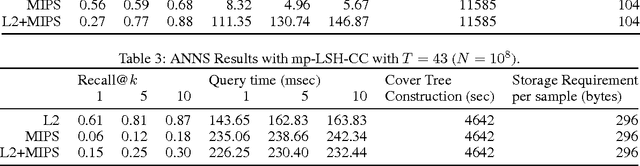
Locality sensitive hashing (LSH) is a powerful tool for sublinear-time approximate nearest neighbor search, and a variety of hashing schemes have been proposed for different dissimilarity measures. However, hash codes significantly depend on the dissimilarity, which prohibits users from adjusting the dissimilarity at query time. In this paper, we propose {multiple purpose LSH (mp-LSH) which shares the hash codes for different dissimilarities. mp-LSH supports L2, cosine, and inner product dissimilarities, and their corresponding weighted sums, where the weights can be adjusted at query time. It also allows us to modify the importance of pre-defined groups of features. Thus, mp-LSH enables us, for example, to retrieve similar items to a query with the user preference taken into account, to find a similar material to a query with some properties (stability, utility, etc.) optimized, and to turn on or off a part of multi-modal information (brightness, color, audio, text, etc.) in image/video retrieval. We theoretically and empirically analyze the performance of three variants of mp-LSH, and demonstrate their usefulness on real-world data sets.
Validity of time reversal for testing Granger causality
Feb 11, 2016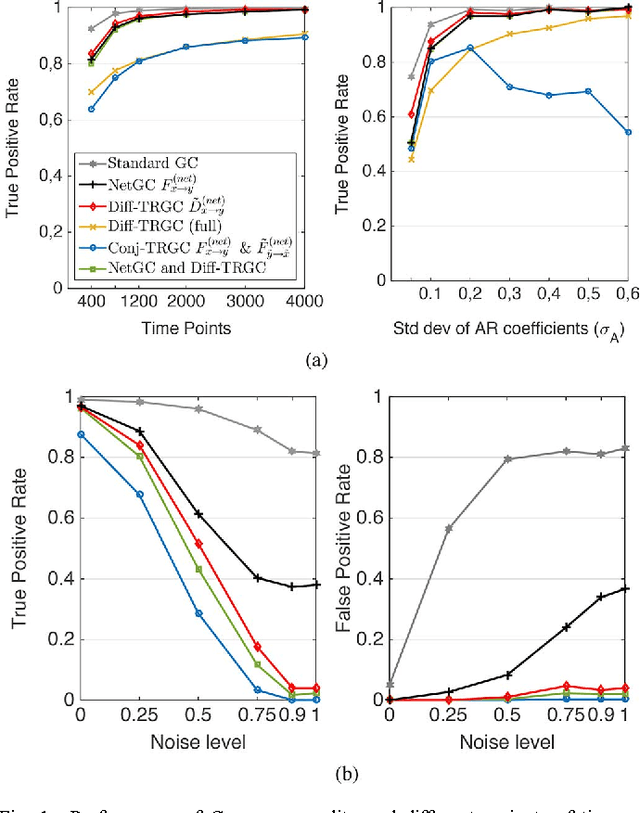
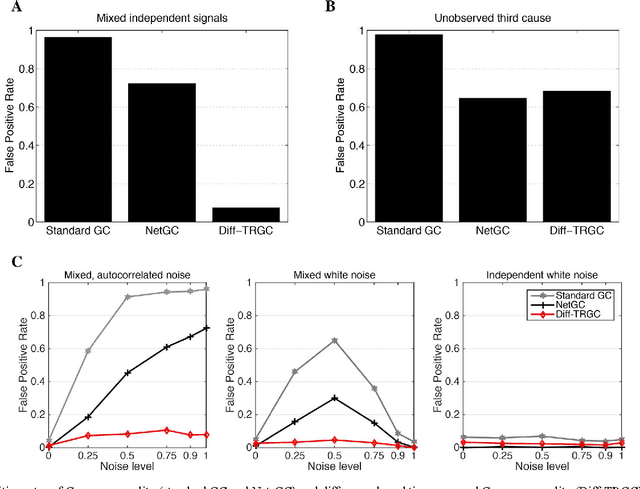
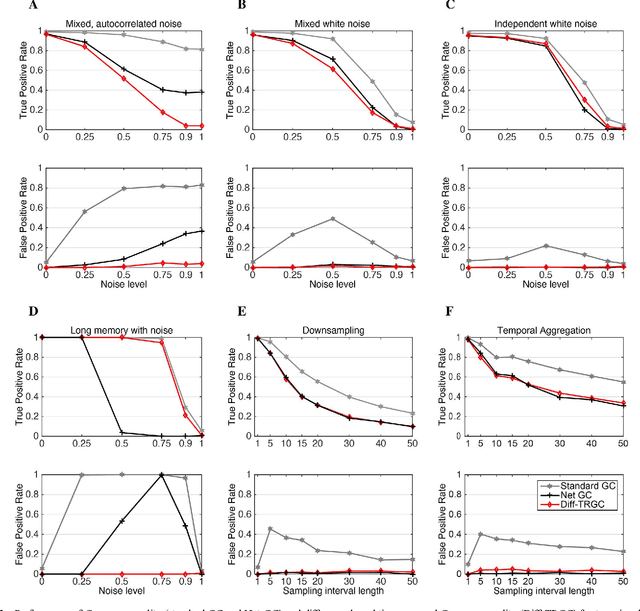
Inferring causal interactions from observed data is a challenging problem, especially in the presence of measurement noise. To alleviate the problem of spurious causality, Haufe et al. (2013) proposed to contrast measures of information flow obtained on the original data against the same measures obtained on time-reversed data. They show that this procedure, time-reversed Granger causality (TRGC), robustly rejects causal interpretations on mixtures of independent signals. While promising results have been achieved in simulations, it was so far unknown whether time reversal leads to valid measures of information flow in the presence of true interaction. Here we prove that, for linear finite-order autoregressive processes with unidirectional information flow, the application of time reversal for testing Granger causality indeed leads to correct estimates of information flow and its directionality. Using simulations, we further show that TRGC is able to infer correct directionality with similar statistical power as the net Granger causality between two variables, while being much more robust to the presence of measurement noise.
Fast Cross-Validation via Sequential Testing
Feb 03, 2016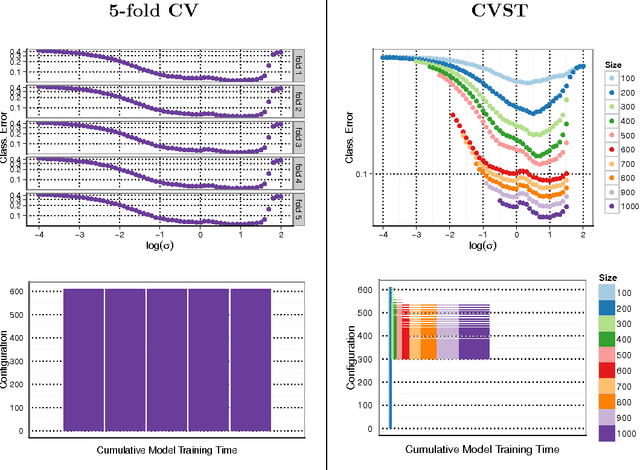



With the increasing size of today's data sets, finding the right parameter configuration in model selection via cross-validation can be an extremely time-consuming task. In this paper we propose an improved cross-validation procedure which uses nonparametric testing coupled with sequential analysis to determine the best parameter set on linearly increasing subsets of the data. By eliminating underperforming candidates quickly and keeping promising candidates as long as possible, the method speeds up the computation while preserving the capability of the full cross-validation. Theoretical considerations underline the statistical power of our procedure. The experimental evaluation shows that our method reduces the computation time by a factor of up to 120 compared to a full cross-validation with a negligible impact on the accuracy.