 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Detection For Short Text Messages In Social Media
Aug 30, 2016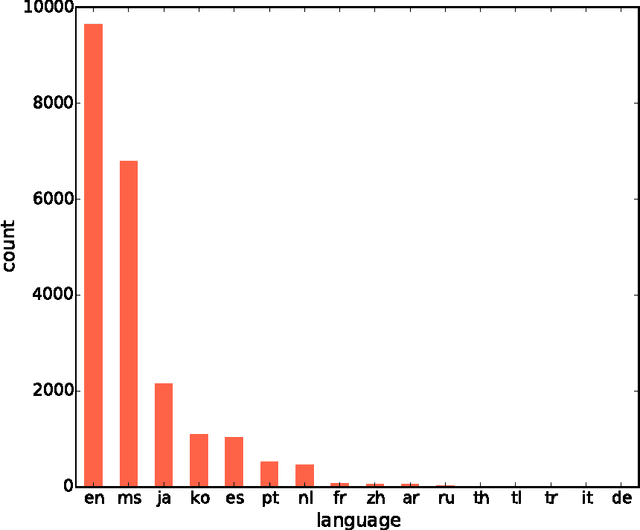
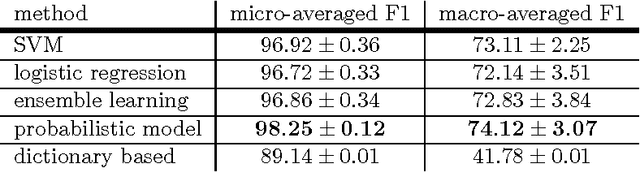
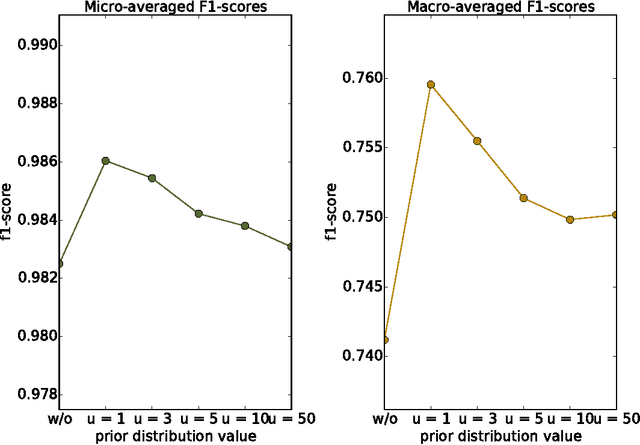

With the constant growth of the World Wide Web and the number of documents in different languages accordingly, the need for reliable language detection tools has increased as well. Platforms such as Twitter with predominantly short texts are becoming important information resources, which additionally imposes the need for short texts language detection algorithms. In this paper, we show how incorporating personalized user-specific information into the language detection algorithm leads to an important improvement of detection results. To choose the best algorithm for language detection for short text messages, we investigate several machine learning approaches. These approaches include the use of the well-known classifiers such as SVM and logistic regression, a dictionary based approach, and a probabilistic model based on modified Kneser-Ney smoothing. Furthermore, the extension of the probabilistic model to include additional user-specific information such as evidence accumulation per user and user interface language is explored, with the goal of improving the classification performance. The proposed approaches are evaluated on randomly collected Twitter data containing Latin as well as non-Latin alphabet languages and the quality of the obtained results is compared, followed by the selection of the best performing algorithm. This algorithm is then evaluated against two already existing general language detection tools: Chromium Compact Language Detector 2 (CLD2) and langid, where our method significantly outperforms the results achieved by both of the mentioned methods. Additionally, a preview of benefits and possible applications of having a reliable language detection algorithm is given.
Fast Cross-Validation via Sequential Testing
Feb 03, 2016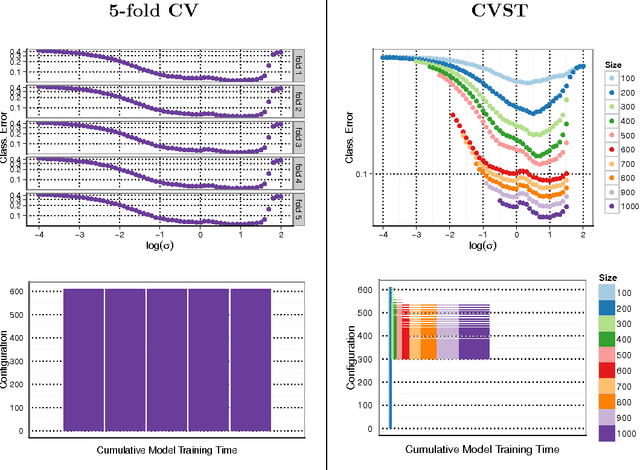



With the increasing size of today's data sets, finding the right parameter configuration in model selection via cross-validation can be an extremely time-consuming task. In this paper we propose an improved cross-validation procedure which uses nonparametric testing coupled with sequential analysis to determine the best parameter set on linearly increasing subsets of the data. By eliminating underperforming candidates quickly and keeping promising candidates as long as possible, the method speeds up the computation while preserving the capability of the full cross-validation. Theoretical considerations underline the statistical power of our procedure. The experimental evaluation shows that our method reduces the computation time by a factor of up to 120 compared to a full cross-validation with a negligible impact on the accuracy.
Canonical Trends: Detecting Trend Setters in Web Data
Jun 27, 2012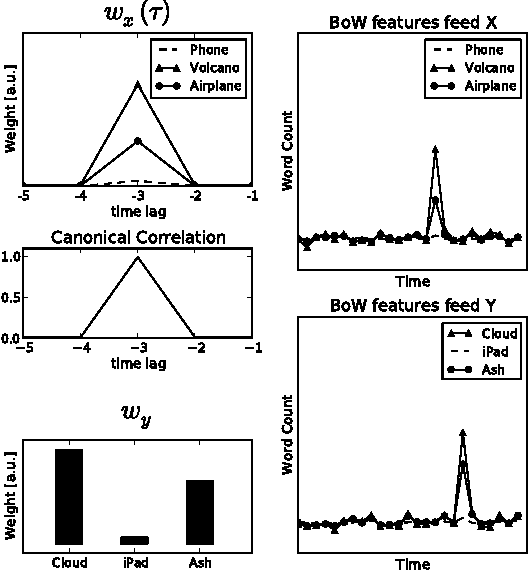
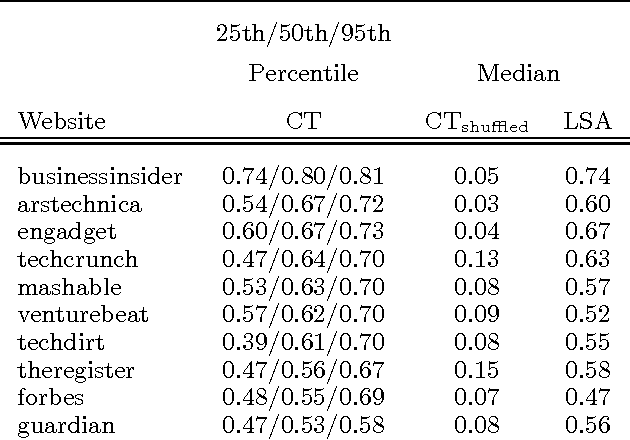
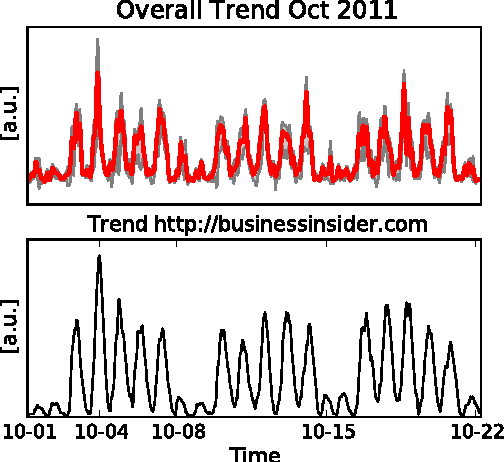
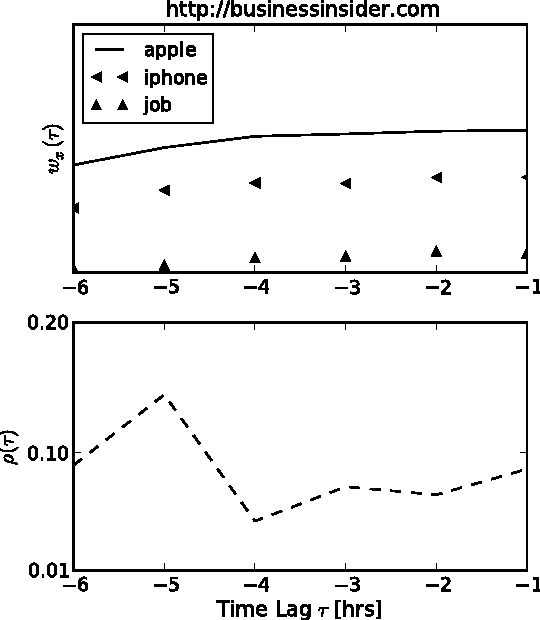
Much information available on the web is copied, reused or rephrased. The phenomenon that multiple web sources pick up certain information is often called trend. A central problem in the context of web data mining is to detect those web sources that are first to publish information which will give rise to a trend. We present a simple and efficient method for finding trends dominating a pool of web sources and identifying those web sources that publish the information relevant to a trend before others. We validate our approach on real data collected from influential technology news feeds.
Lanczos Approximations for the Speedup of Kernel Partial Least Squares Regression
Feb 19, 2009


The runtime for Kernel Partial Least Squares (KPLS) to compute the fit is quadratic in the number of examples. However, the necessity of obtaining sensitivity measures as degrees of freedom for model selection or confidence intervals for more detailed analysis requires cubic runtime, and thus constitutes a computational bottleneck in real-world data analysis. We propose a novel algorithm for KPLS which not only computes (a) the fit, but also (b) its approximate degrees of freedom and (c) error bars in quadratic runtime. The algorithm exploits a close connection between Kernel PLS and the Lanczos algorithm for approximating the eigenvalues of symmetric matrices, and uses this approximation to compute the trace of powers of the kernel matrix in quadratic runtime.
* to appear in Proceedings of the 12th International Conference on Artificial Intelligence and Statistics (AISTATS 09)