 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLD: A Benchmark for Linked Data User Agents and a Simulation Framework for Dynamic Linked Data Environments
Jul 18, 2023The paper presents the BOLD (Buildings on Linked Data) benchmark for Linked Data agents, next to the framework to simulate dynamic Linked Data environments, using which we built BOLD. The BOLD benchmark instantiates the BOLD framework by providing a read-write Linked Data interface to a smart building with simulated time, occupancy movement and sensors and actuators around lighting. On the Linked Data representation of this environment, agents carry out several specified tasks, such as controlling illumination. The simulation environment provides means to check for the correct execution of the tasks and to measure the performance of agents. We conduct measurements on Linked Data agents based on condition-action rules.
Specifying, Monitoring, and Executing Workflows in Linked Data Environments
Apr 19, 2018



We present an ontology for representing workflows over components with Read-Write Linked Data interfaces and give an operational semantics to the ontology via a rule language. Workflow languages have been successfully applied for modelling behaviour in enterprise information systems, in which the data is often managed in a relational database. Linked Data interfaces have been widely deployed on the web to support data integration in very diverse domains, increasingly also in scenarios involving the Internet of Things, in which application behaviour is often specified using imperative programming languages. With our work we aim to combine workflow languages, which allow for the high-level specification of application behaviour by non-expert users, with Linked Data, which allows for decentralised data publication and integrated data access. We show that our ontology is expressive enough to cover the basic workflow patterns and demonstrate the applicability of our approach with a prototype system that observes pilots carrying out tasks in a mixed-reality aircraft cockpit. On a synthetic benchmark from the building automation domain, the runtime scales linearly with the size of the number of Internet of Things devices.
Canonical Trends: Detecting Trend Setters in Web Data
Jun 27, 2012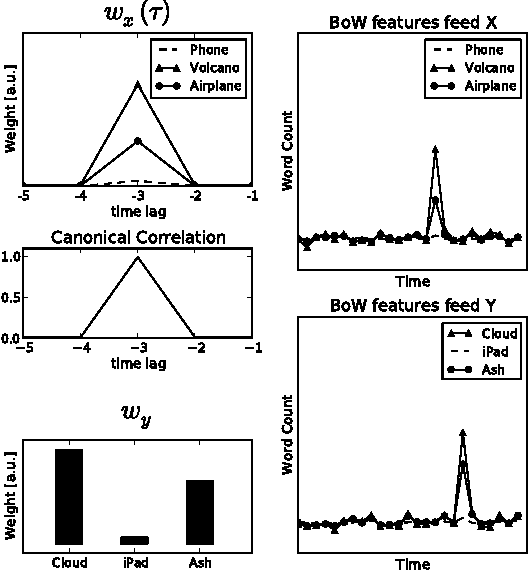
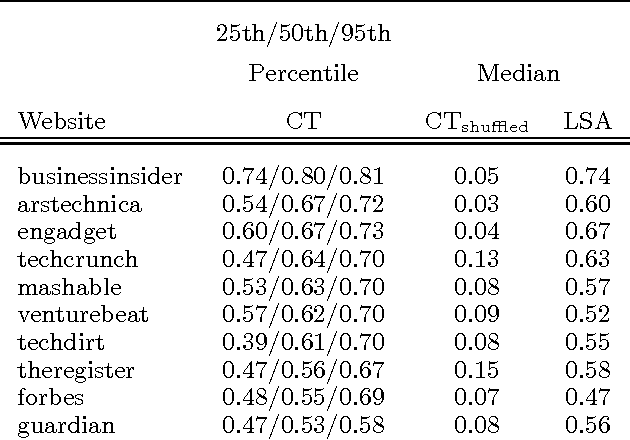
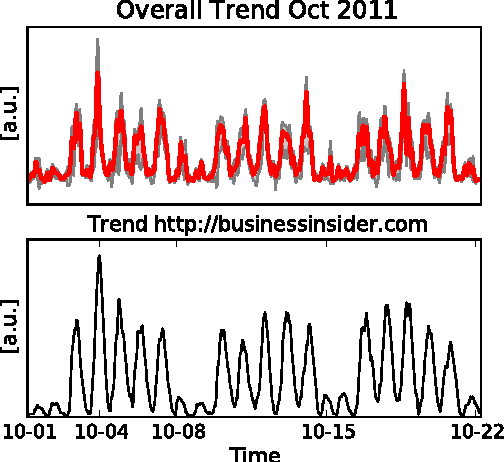
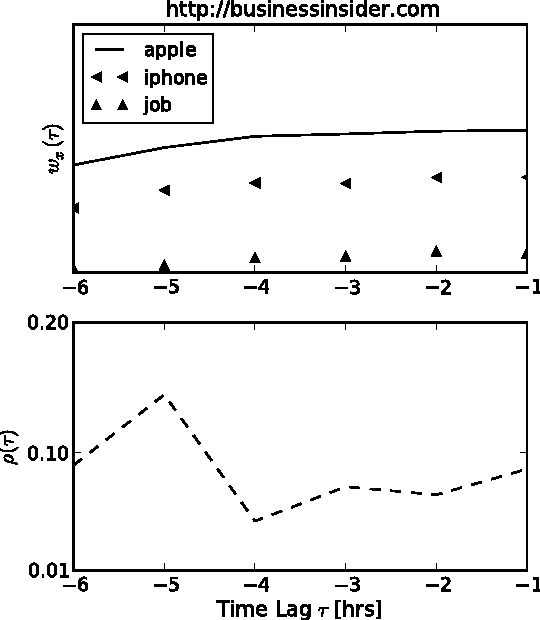
Much information available on the web is copied, reused or rephrased. The phenomenon that multiple web sources pick up certain information is often called trend. A central problem in the context of web data mining is to detect those web sources that are first to publish information which will give rise to a trend. We present a simple and efficient method for finding trends dominating a pool of web sources and identifying those web sources that publish the information relevant to a trend before others. We validate our approach on real data collected from influential technology news feeds.