 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Where does it hurt?" -- Dataset and Study on Physician Intent Trajectories in Doctor Patient Dialogues
Aug 26, 2025



In a doctor-patient dialogue, the primary objective of physicians is to diagnose patients and propose a treatment plan. Medical doctors guide these conversations through targeted questioning to efficiently gather the information required to provide the best possible outcomes for patients. To the best of our knowledge, this is the first work that studies physician intent trajectories in doctor-patient dialogues. We use the `Ambient Clinical Intelligence Benchmark' (Aci-bench) dataset for our study. We collaborate with medical professionals to develop a fine-grained taxonomy of physician intents based on the SOAP framework (Subjective, Objective, Assessment, and Plan). We then conduct a large-scale annotation effort to label over 5000 doctor-patient turns with the help of a large number of medical experts recruited using Prolific, a popular crowd-sourcing platform. This large labeled dataset is an important resource contribution that we use for benchmarking the state-of-the-art generative and encoder models for medical intent classification tasks. Our findings show that our models understand the general structure of medical dialogues with high accuracy, but often fail to identify transitions between SOAP categories. We also report for the first time common trajectories in medical dialogue structures that provide valuable insights for designing `differential diagnosis' systems. Finally, we extensively study the impact of intent filtering for medical dialogue summarization and observe a significant boost in performance. We make the codes and data, including annotation guidelines, publicly available at https://github.com/DATEXIS/medical-intent-classification.
Generalist embedding models are better at short-context clinical semantic search than specialized embedding models
Jan 06, 2024The increasing use of tools and solutions based on Large Language Models (LLMs) for various tasks in the medical domain has become a prominent trend. Their use in this highly critical and sensitive domain has thus raised important questions about their robustness, especially in response to variations in input, and the reliability of the generated outputs. This study addresses these questions by constructing a textual dataset based on the ICD-10-CM code descriptions, widely used in US hospitals and containing many clinical terms, and their easily reproducible rephrasing. We then benchmarked existing embedding models, either generalist or specialized in the clinical domain, in a semantic search task where the goal was to correctly match the rephrased text to the original description. Our results showed that generalist models performed better than clinical models, suggesting that existing clinical specialized models are more sensitive to small changes in input that confuse them. The highlighted problem of specialized models may be due to the fact that they have not been trained on sufficient data, and in particular on datasets that are not diverse enough to have a reliable global language understanding, which is still necessary for accurate handling of medical documents.
MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data
Apr 14, 2023As large language models (LLMs) like OpenAI's GPT series continue to make strides, we witness the emergence of artificial intelligence applications in an ever-expanding range of fields. In medicine, these LLMs hold considerable promise for improving medical workflows, diagnostics, patient care, and education. Yet, there is an urgent need for open-source models that can be deployed on-premises to safeguard patient privacy. In our work, we present an innovative dataset consisting of over 160,000 entries, specifically crafted to fine-tune LLMs for effective medical applications. We investigate the impact of fine-tuning these datasets on publicly accessible pre-trained LLMs, and subsequently, we juxtapose the performance of pre-trained-only models against the fine-tuned models concerning the examinations that future medical doctors must pass to achieve certification.
MEDBERT.de: A Comprehensive German BERT Model for the Medical Domain
Mar 24, 2023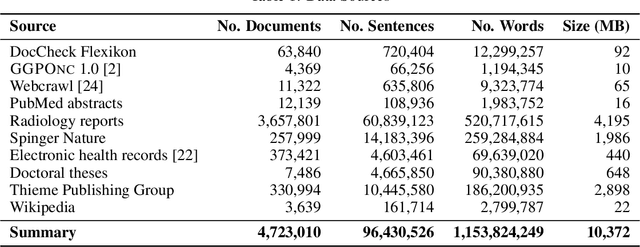
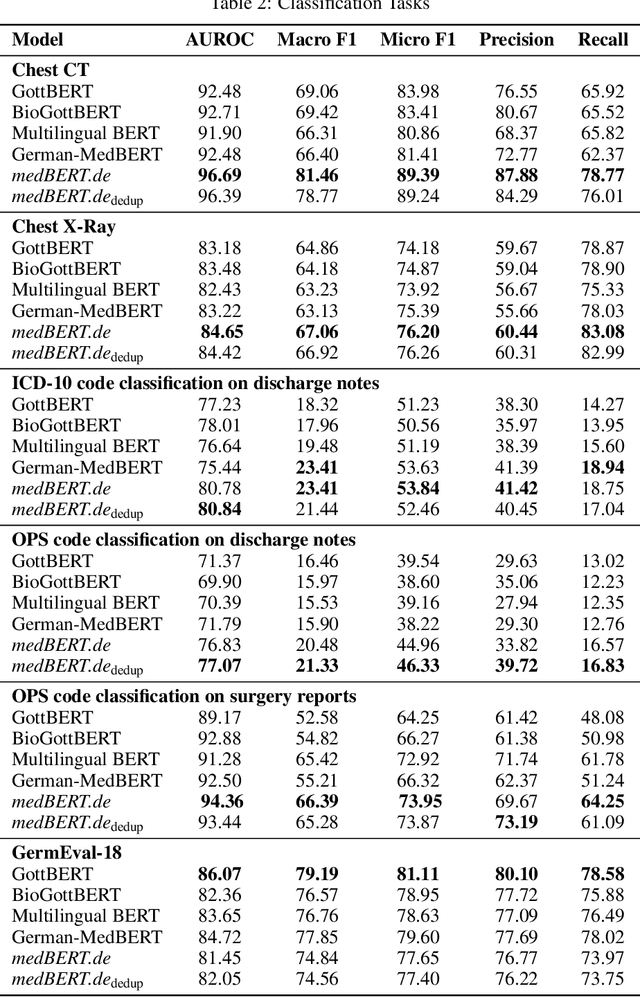
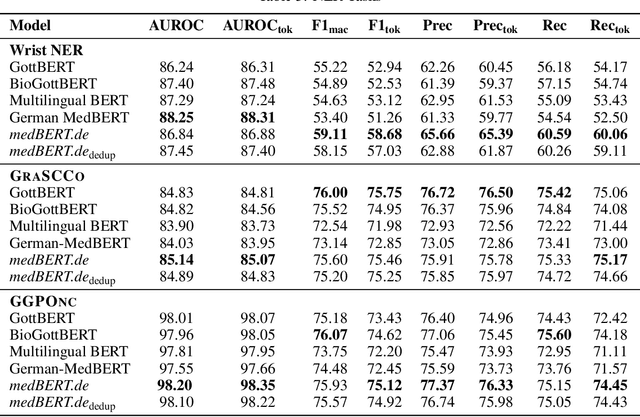

This paper presents medBERTde, a pre-trained German BERT model specifically designed for the German medical domain. The model has been trained on a large corpus of 4.7 Million German medical documents and has been shown to achieve new state-of-the-art performance on eight different medical benchmarks covering a wide range of disciplines and medical document types. In addition to evaluating the overall performance of the model, this paper also conducts a more in-depth analysis of its capabilities. We investigate the impact of data deduplication on the model's performance, as well as the potential benefits of using more efficient tokenization methods. Our results indicate that domain-specific models such as medBERTde are particularly useful for longer texts, and that deduplication of training data does not necessarily lead to improved performance. Furthermore, we found that efficient tokenization plays only a minor role in improving model performance, and attribute most of the improved performance to the large amount of training data. To encourage further research, the pre-trained model weights and new benchmarks based on radiological data are made publicly available for use by the scientific community.
This Patient Looks Like That Patient: Prototypical Networks for Interpretable Diagnosis Prediction from Clinical Text
Oct 16, 2022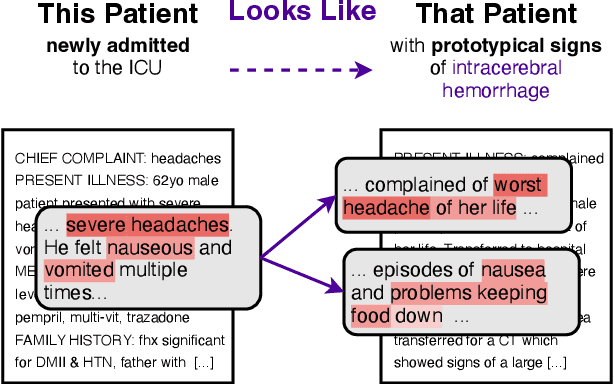
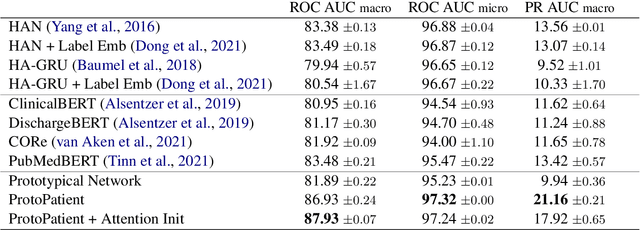

The use of deep neural models for diagnosis prediction from clinical text has shown promising results. However, in clinical practice such models must not only be accurate, but provide doctors with interpretable and helpful results. We introduce ProtoPatient, a novel method based on prototypical networks and label-wise attention with both of these abilities. ProtoPatient makes predictions based on parts of the text that are similar to prototypical patients - providing justifications that doctors understand. We evaluate the model on two publicly available clinical datasets and show that it outperforms existing baselines. Quantitative and qualitative evaluations with medical doctors further demonstrate that the model provides valuable explanations for clinical decision support.
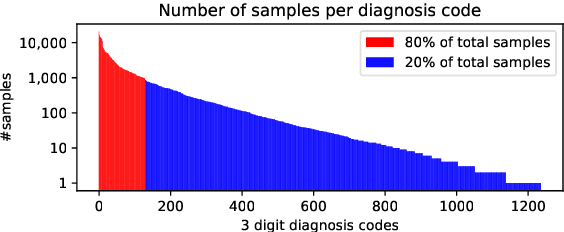
Cross-Lingual Knowledge Transfer for Clinical Phenotyping
Aug 03, 2022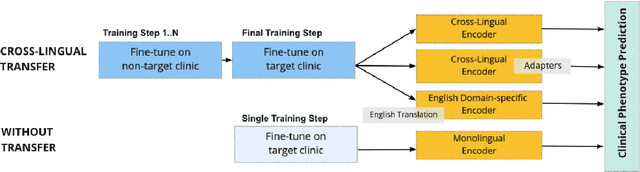
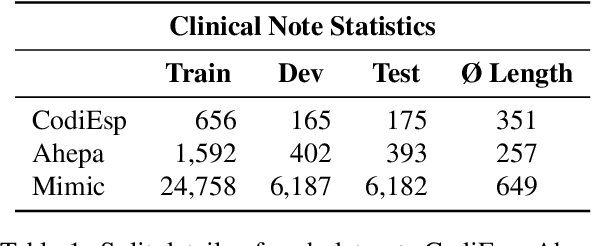

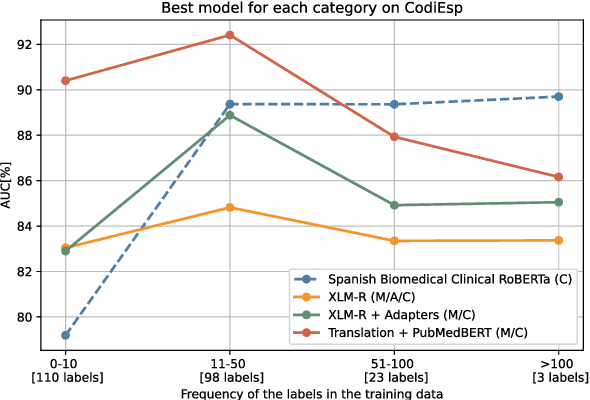
Clinical phenotyping enables the automatic extraction of clinical conditions from patient records, which can be beneficial to doctors and clinics worldwide. However, current state-of-the-art models are mostly applicable to clinical notes written in English. We therefore investigate cross-lingual knowledge transfer strategies to execute this task for clinics that do not use the English language and have a small amount of in-domain data available. We evaluate these strategies for a Greek and a Spanish clinic leveraging clinical notes from different clinical domains such as cardiology, oncology and the ICU. Our results reveal two strategies that outperform the state-of-the-art: Translation-based methods in combination with domain-specific encoders and cross-lingual encoders plus adapters. We find that these strategies perform especially well for classifying rare phenotypes and we advise on which method to prefer in which situation. Our results show that using multilingual data overall improves clinical phenotyping models and can compensate for data sparseness.
* LREC 2022 submmision: January 2022
Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration
Feb 08, 2021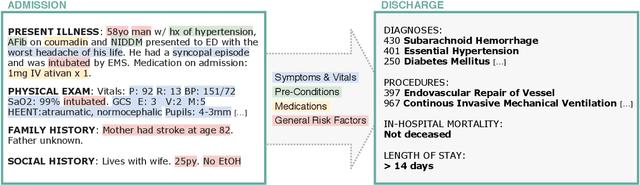
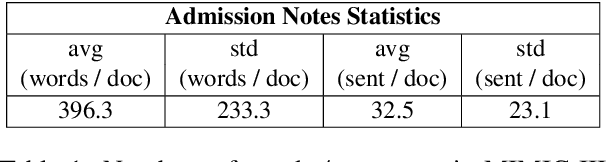

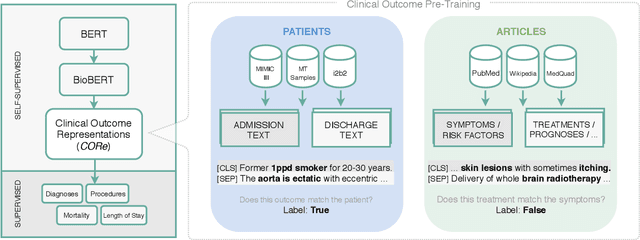
Outcome prediction from clinical text can prevent doctors from overlooking possible risks and help hospitals to plan capacities. We simulate patients at admission time, when decision support can be especially valuable, and contribute a novel admission to discharge task with four common outcome prediction targets: Diagnoses at discharge, procedures performed, in-hospital mortality and length-of-stay prediction. The ideal system should infer outcomes based on symptoms, pre-conditions and risk factors of a patient. We evaluate the effectiveness of language models to handle this scenario and propose clinical outcome pre-training to integrate knowledge about patient outcomes from multiple public sources. We further present a simple method to incorporate ICD code hierarchy into the models. We show that our approach improves performance on the outcome tasks against several baselines. A detailed analysis reveals further strengths of the model, including transferability, but also weaknesses such as handling of vital values and inconsistencies in the underlying data.
Canonical Trends: Detecting Trend Setters in Web Data
Jun 27, 2012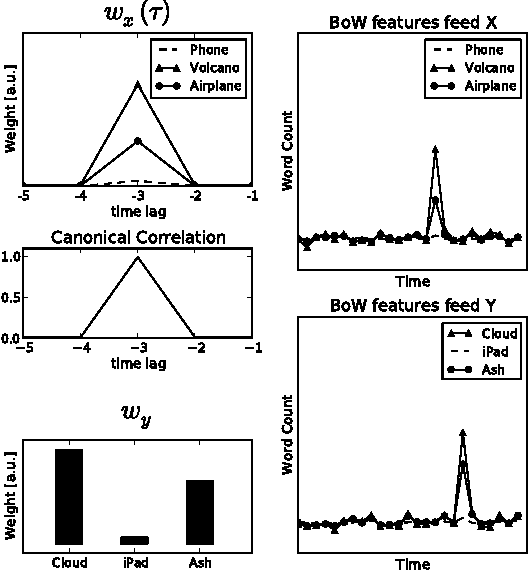
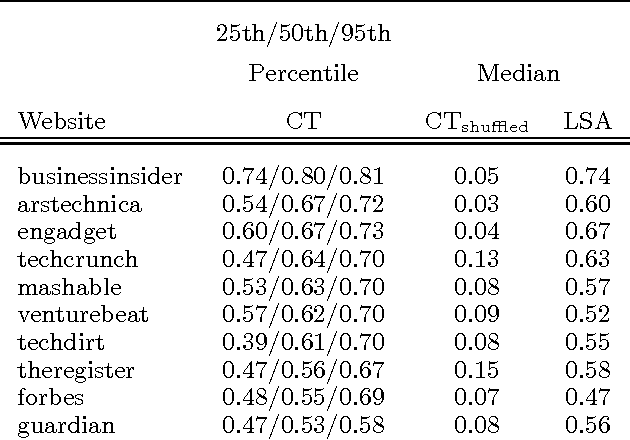
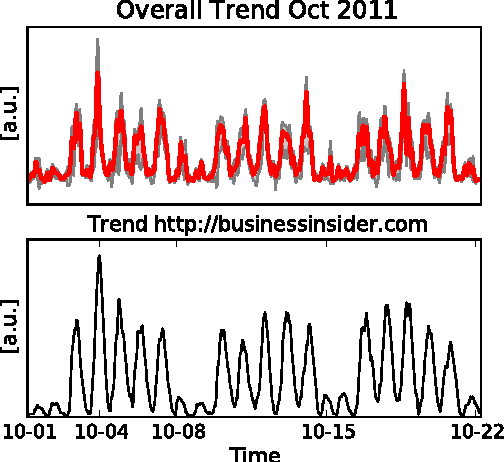
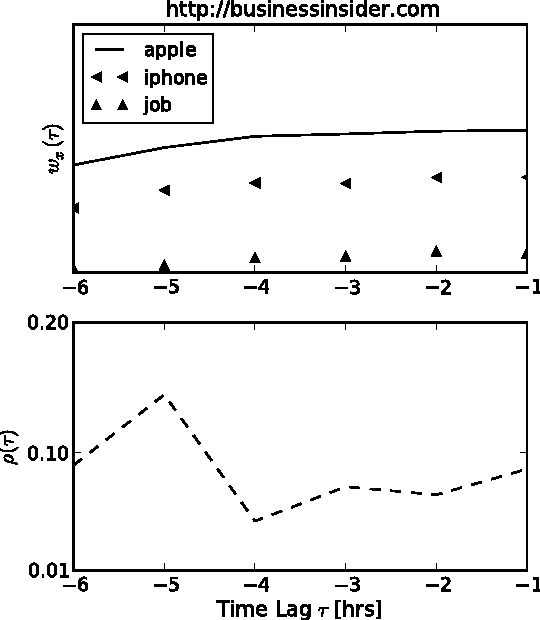
Much information available on the web is copied, reused or rephrased. The phenomenon that multiple web sources pick up certain information is often called trend. A central problem in the context of web data mining is to detect those web sources that are first to publish information which will give rise to a trend. We present a simple and efficient method for finding trends dominating a pool of web sources and identifying those web sources that publish the information relevant to a trend before others. We validate our approach on real data collected from influential technology news feeds.