 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Detection For Short Text Messages In Social Media
Paper and Code
Aug 30, 2016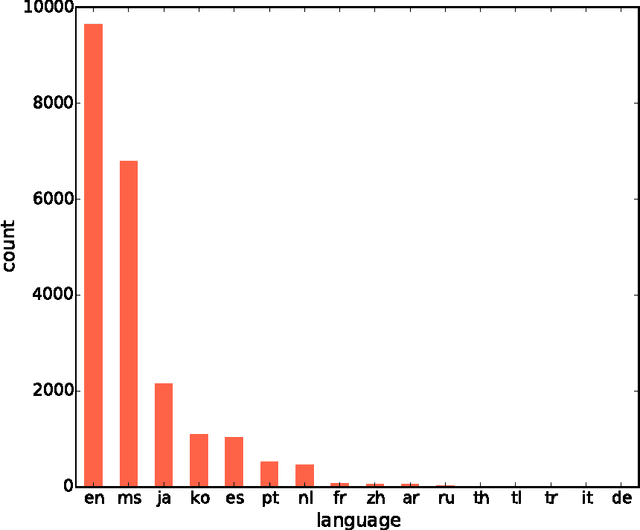
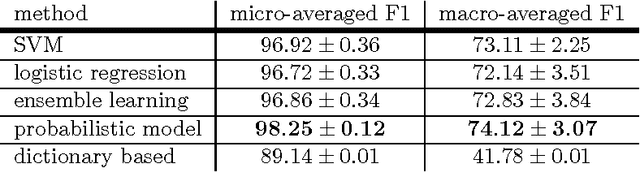
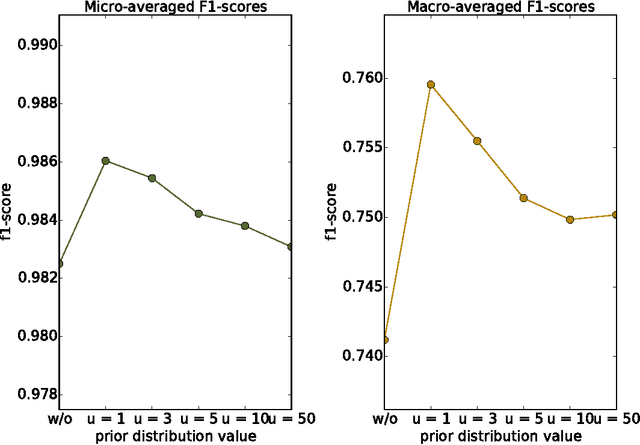

With the constant growth of the World Wide Web and the number of documents in different languages accordingly, the need for reliable language detection tools has increased as well. Platforms such as Twitter with predominantly short texts are becoming important information resources, which additionally imposes the need for short texts language detection algorithms. In this paper, we show how incorporating personalized user-specific information into the language detection algorithm leads to an important improvement of detection results. To choose the best algorithm for language detection for short text messages, we investigate several machine learning approaches. These approaches include the use of the well-known classifiers such as SVM and logistic regression, a dictionary based approach, and a probabilistic model based on modified Kneser-Ney smoothing. Furthermore, the extension of the probabilistic model to include additional user-specific information such as evidence accumulation per user and user interface language is explored, with the goal of improving the classification performance. The proposed approaches are evaluated on randomly collected Twitter data containing Latin as well as non-Latin alphabet languages and the quality of the obtained results is compared, followed by the selection of the best performing algorithm. This algorithm is then evaluated against two already existing general language detection tools: Chromium Compact Language Detector 2 (CLD2) and langid, where our method significantly outperforms the results achieved by both of the mentioned methods. Additionally, a preview of benefits and possible applications of having a reliable language detection algorithm is given.